Параллелизм против многопоточности против асинхронного программирования: разъяснение / Habr
Хочу представить вашему вниманию перевод статьи Concurrency vs Multi-threading vs Asynchronous Programming: Explained.В последние время, я выступал на мероприятиях и отвечал на вопрос аудитории между моими выступлениями о Асинхронном программировании, я обнаружил что некоторые люди путали многопоточное и асинхронное программирование, а некоторые говорили, что это одно и тоже. Итак, я решил разъяснить эти термины и добавить еще одно понятие Параллелизм. Здесь есть две концепции и обе они совершенно разные, первая синхронное и асинхронное программирование и вторая – однопоточные и многопоточные приложения. Каждая программная модель (синхронная или асинхронная) может работать в однопоточной и многопоточной среде. Давайте обсудим их подробно.
Синхронная программная модель – это программная модель, когда потоку назначается одна задача и начинается выполнение. Когда завершено выполнение задачи тогда появляется возможность заняться другой задачей. В этой модели невозможно останавливать выполнение задачи чтобы в промежутке выполнить другую задачу. Давайте обсудим как эта модель работает в одно и многопоточном сценарии.
Однопоточность – если мы имеем несколько задач, которые надлежит выполнить, и текущая система предоставляет один поток, который может работать со всеми задачами, то он берет поочередно одну за другой и процесс выглядит так:

Здесь мы видим, что мы имеем поток (Поток 1) и 4 задачи, которые необходимо выполнить. Поток начинает выполнять поочередно одну за одной и выполняет их все. (Порядок, в котором задачи выполняются не влияет на общее выполнение, у нас может быть другой алгоритм, который может определять приоритеты задач.
Многопоточность – в этом сценарии, мы использовали много потоков, которые могут брать задачи и приступать к работе с ними. У нас есть пулы потоков (новые потоки также создаются, основываясь на потребности и доступности ресурсов) и множество задач. Итак, поток может работать вот так:

Здесь мы можем видеть, что у нас есть 4 потока и столько же задач для выполнения, и каждый поток начинает работать с ними. Это идеальный сценарий, но в обычных условиях мы используем большее количество задач чем количество доступных потоков, таким образом освободившийся поток получает другое задание. Как уже говорилось создание нового потока не происходит каждый раз потому что для этого требуются системные ресурсы такие как процессор, память и начальное количество потоков должно быть определенным.
Теперь давайте поговорим о Асинхронной модели и как она ведет себя в одно и многопоточной среде.
Асинхронная модель программирования – в отличии от синхронной программной модели, здесь поток однажды начав выполнение задачи может приостановить выполнение сохранив текущее состояние и между тем начать выполнение другой задачи.

Здесь мы можем видеть, что один поток отвечает за выполнение всех задач и задачи чередуются друг за другом.
Если наша система способно иметь много потоков тогда все потоки могут работать в асинхронной модели как показано ниже:

Здесь мы можем видеть, что одна и та же задача скажем Т4, Т5, Т6 … обрабатывается несколькими потоками. Это красота этого сценария. Как мы можем видеть, что задача Т4 начала выполнение первой Потоком 1 и завершен Потоком 2. Подобным образом задча Т6 выполнена Потоком 2, Потоком 3 и Потоком 4. Это демонстрирует максимальное использование потоков.
Итак, до сих пор мы обсудили 4 сценария:
- Синхронный однопоточный
- Синхронный многопоточный
- Асинхронный однопоточный
- Асинхронный многопоточный
Давайте обсудим еще один термин – параллелизм.
Параллелизм
Проще говоря параллелизм способ обработки множественных запросом одновременно. Так как мы обсуждали два сценария когда обрабатывались множественные запросы, многопоточное программирование и асинхронная модель (одно и многопоточная). В случае асинхронной модели будь она однопоточной или многопоточной, в то время, когда выполняются множество задач, некоторые из них приостанавливаются, а некоторые выполняются. Существует много особенностей, но это выходит за рамки этой публикации.
Как обсуждалось ранее новая эпоха за асинхронным программированием. Почему это так важно?
Преимущества асинхронного программирования
Существует две вещи очень важные для каждого приложения – удобство использования и производительность. Удобство использования потому что пользователь нажав кнопку чтобы сохранить некоторые данные что в свою очередь требует выполнения множества задач таких как чтение и заполнение данных во внутреннем объекте, установление соединения с SQL и сохранения его там. В свою очередь SQL запускается на другой машине в сети и работает под другим процессом, это может потребовать много время. Таким образом если запрос обрабатывается одним процессом экран будет находится в зависшем состоянии до тех пор, пока процесс не завершится. Вот почему сегодня многие приложения и фреймворки полностью полагаются на асинхронную модель.
Производительность приложения и системы также очень важны. Было замечено в то время как выполняется запрос, около 70-80% из них попадают в ожидании зависимых задач. Таким образом, это может быть максимально использовано в асинхронном программирование, где, как только задача передается другому потоку (например, SQL), текущий поток сохраняет состояние и доступен для выполнения другого процесса, а когда задача sql завершается, любой поток, который является свободным, может заняться этой задачей.
Асинхронность в ASP.NET
Асинхронность в ASP.NET может стать большим стимулом для повышения производительности вашего приложения. Вот, как IIS обрабатывает запрос:

Когда запрос получен IIS, он берет поток из пула потоков CLR (IIS не имеет какого-либо пула потоков, а сам вместо этого использует пул потоков CLR) и назначает его ему, который далее обрабатывает запрос. Поскольку количество потоков ограничено, и новые могут быть созданы с определенным пределом, тогда если поток будет находится большую часть времени в состоянии ожидания, то это сильно ударит по вашему серверу, вы можете предположить, что это реальность. Но если вы пишете асинхронный код (который теперь становится очень простым и может быть написан почти аналогично синхронному при использовании новых ключевых слов async / await), то он будет работать намного быстрее, и пропускная способность вашего сервера значительно возрастет, потому что вместо ожидания какого-нибудь завершения, он будет доступен пулу потоков, для нового запроса. Если приложение имеет множество зависимостей и длительный процесс выполнения, то для этого приложения асинхронное программирование будет не меньшем благом.
Итак, теперь мы поняли разницу многопоточного, асинхронного программирования и преимущества, которые мы можем получить, используя асинхронную модель программирования.
habr.com
Синхронность и асинхронность процессов / Habr
Мир может многому научиться у программистов. Он и так учится, только не тому и не так. Например, взял процессы и алгоритмы, но не заметил такого подхода, как асинхронность.Любому программисту понятно, что такое синхронность и асинхронность. Вот насколько это понятно программисту, настолько это непонятно и обычным разработчикам процессов.
Синхронные действия процесса – те, которые выполняются в основном потоке, в рамках одного экземпляра процесса. Ключевое отличие синхронного режима: следующее действие начинается только тогда, когда завершено предыдущее. Соответственно, пока одно действие не завершено, процесс стоит колом.
Асинхронные действия – те, которые выполняются параллельно основному потоку, либо в том же экземпляре процесса, либо вообще в другом процессе. Ключевое отличие асинхронного режима: параллельное выполнение двух и более ветвей процесса.
Синхронные процессы, как и программы, писать и отлаживать намного проще, поэтому такой подход к конструированию процесса очень сильно распространен. С асинхронностью надо много возиться, особенно – с обозначением точек перехода в параллельное выполнение и возврата обратно, в русло основного процесса. В жизни ведь нет промисов.
Например, тот же процесс закупок по заявке. Рисуется стандартно, как последовательность действий: появилась заявка, снабженец выбирает поставщика, запрашивает сроки и стоимость, согласует с продавцом или отделом внутреннего контроля, формирует заказ поставщику, запрашивает в юридическом отделе или в бухгалтерии оценку контрагента, создает заявку на оплату, ждет этой оплаты, отслеживает заказ, потом организует или отслеживает оприходование на складе, чтобы, в конце концов, закрыть заявку. Процесс полностью синхронен.
Теперь представим – в нашей информационной системе не подключен сервис оценки поставщиков. Значит, юридическому отделу нужно собирать информацию из открытых источников. Значит, на выполнение оценки требуется время. С учетом очереди заявок к юристам, пройдет дня три.
Что в это время будет с процессом? Согласно синхронной логике, он будет стоять колом. Снабженец, будучи верным элементом системы, и пальцем не пошевелит, пока не получит оценку поставщика – особенно, если предусмотрены санкции за работу с непроверенными контрагентами.
Можем мы здесь добавить асинхронности? Конечно. В тот момент, когда снабженец выбрал поставщика, он может отправить заявку на оценку контрагента в юридический отдел, а сам пока будет вести переговоры, согласовывать цены и сроки. К тому моменту, когда он будет готов разместить заказ, и оценка подоспеет. Процесс закончится раньше на три дня.
Конечно, юристы могут возмутиться – чего это мы будем оценивать поставщика, если вы там еще четко не решили, будете ли у него заказывать? Что им ответить?
Решение напрашивается само собой, выше мы его уже обозначили – подключить сервис оценки поставщиков. Теперь мы еще лучше понимаем, зачем оно нужно – для придания асинхронности и ускорения процесса. Хотя, сервис, наверное, будет как раз синхронным. Как думаете?
Если сервис не подключать, то можно оправдать такую оценку работой «впрок». Если в вашей информационной системе есть куда записать данные оценки, то в следующий раз, когда возникнет потребность в работе с этим поставщиком, обращаться в юридический отдел уже не придется. Конечно, у оценки есть срок годности, но в некоторых разумных пределах ей пользоваться можно.
В асинхронности обычно пугает отсутствие гарантий, то есть риск негативного результата в одной из параллельных ветвей процесса. Что делать, если согласование закончится неудачей?
Тут нужна статистика. Если вы работаете с существующим процессом, то примерно, или точно, представляете себе, как часто определенные действия заканчиваются негативно – например, согласования. Вот из этой вероятности и стоит исходить, запуская параллельное выполнение.
Асинхронность прям напрашивается во все процессы согласования. Если там работать только по синхронному режиму, да еще и идти на поводу у согласующих, то выстраиваются длинные, взаимозависимые цепочки, порождающие бюрократию и круговую поруку.
Типичный пример: «я буду согласовывать только после того, как согласует вот он». Или «я посмотрю на этот договор только после финансистов». Хотя, если верить статистике и здравому смыслу, подобные постановки не имеют под собой оснований, и являются лишь способом переложить ответственность.
Тут главное – не переживать, и не браться за все сразу. Попробуйте выделить в асинхронный режим сначала одну ветвь согласования. Возможно, потребуется пересмотреть задание, параметры согласования – так, чтобы исключить взаимозависимость.
Например, пусть финансовый отдел, стоящий в цепочке согласования договора, смотрит только на условия оплаты. Пусть у него будут свои, понятные критерии оценки. Лучше, если они будут формализованы в виде типового договора – например, 100% постоплата для поставщиков, 100 % предоплата для покупателей. В таком случае договоры, удовлетворяющие критериям, будут проскакивать на раз. И у финансистов не останется повода ждать оценки от тех же юристов.
Единственное, что важно: асинхронные процессы очень сложно реализовать без автоматизации. Если процессы, их исполнение и отслеживание реализованы только на бумаге, то добавление параллельных ветвей превратит их в хаос. Нужна автоматизация.
Лучше всего для такой автоматизации подходит принцип «Автозадачи». Хотя, можно обойтись и стандартными средствами рисования процессов, которые есть в современных платформах, только придется повозиться.
Стандартные «рисовалки» процессов потребуют от вас обозначить весь процесс, все ветви и взаимосвязи. Если процесс сложный и длинный, то вы столкнетесь с проблемой – он банально перестанет влезать на экран, в ширину. Если вы учились в институте на программиста, то помните такое правило оформления алгоритмов: не более трех параллельных вертикальных ветвей. Правило придумано не просто так – если ветвей будет больше, понять схему алгоритма будет проблематично.
Автозадачи от этой проблемы избавляют – там изображения процесса нет вообще, т.к. отсутствует такая сущность – процесс. Есть задачи. Если очень хочется, можно из них собрать процесс. Но не наоборот. Эдакий дедуктивный метод рисования процессов.
Кроме асинхронности, есть еще более мощный метод оптимизации – буферизация процессов. О нем – в другой раз.
habr.com
Асинхронное и синхронное программирование

С некоторых пор я получаю много вопросов об асинхронном программировании. И, поняв, что данная тема интересует многих моих читателей, я решил написать статью, для объяснения этих терминов, тем более, что асинхронное программирование является очень важной частью современного Интернета.
Для начала необходимо отметить, что существуют две совершенно разные концепции: первая — синхронная и асинхронная модели программирования, а вторая - однопоточные и многопоточные среды. Каждая из моделей программирования (синхронная и асинхронная) может работать как в однопоточной, так и в многопоточной среде.
Модель синхронного программирования.
В этой модели программирования поток назначается одной задаче и начинает работать над ней. Как только задача завершается, поток доступен для следующей задачи. Т.е. одна задача сменятся другой последовательно. В этой модели невозможно оставить выполнение задачи в середине для выполнения другой задачи. Давайте обсудим, как эта модель работает в однопоточных и многопоточных средах.
Однопоточная среда — Single Threaded — если у нас есть пара задач, которые необходимо выполнить, а текущая система предоставляет только один поток, тогда задачи назначаются потоку одна за другой. Наглядно это можно изобразить вот так:

,где Thread 1 — один поток, Task 1 и Task 2, Task 3, Task 4 – соответствующие задачи.
Мы видим, что у нас есть поток (Thread 1) и четыре задачи, которые нужно выполнить. Поток начинает работу над задачами и завершает все задачи одну за другой.
Многопоточная среда — Multi-Threaded — в этой среде мы используем несколько потоков, которые могут выполнять эти задачи одновременно. Это означает, что у нас есть пул потоков (новые потоки также могут создаваться по необходимости на основе доступных ресурсов) и множество задач.

Мы видим, что у нас есть четыре потока и столько же задач. Поэтому каждый поток выполняет одну задачу и завершает ее. Это идеальный сценарий, но в обычных условиях у нас, как правило, больше задач, чем количество доступных потоков. И поэтому, когда один поток закончит выполнять некоторую задачу, он немедленно приступит к выполнению другой. Обратите внимание также и на тот факт, что новый поток создается не каждый раз, потому что ему нужны системные ресурсы, такие как такты процессора и память, которых может оказаться недостаточно.
Теперь давайте поговорим об асинхронной модели и о том, как она ведет себя в однопоточной и многопоточной среде.
Модель асинхронного программирования.
В отличие от модели синхронного программирования, здесь один поток, запуская некую задачу, может остановить на некотором промежутке времени ее выполнения, сохраняя при этом ее текущее состояние, и начать выполнять другую задачу

мы видим, что один поток отвечает за выполнение всех задач, чередуя их, друг с другом.
Если наша система способна создавать несколько потоков, то все потоки могут работать по асинхронной модели.
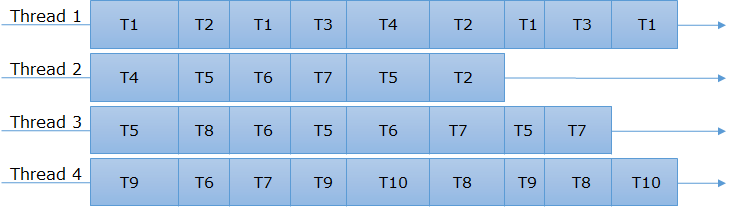
Мы видим, что те же задачи T4, T5, T6 обрабатываются несколькими потоками. В этом и состоит красота и сила этого сценария. Как вы можете видеть, задача T4 была запущена первой в потоке Thread 1 и завершена в потоке Thread 2. Точно так же T6 завершается в Thread 2, Thread 3 и Thread 4.
Итак, всего у нас четыре сценария –
- Синхронный однопоточный
- Синхронный многопоточный
- Асинхронный однопоточный
- Асинхронный многопоточный
Преимущества асинхронного программирования
Для любого приложения важны две вещи: удобство использования и производительность. Удобство использования важно потому, что когда пользователь нажимает кнопку, чтобы сохранить некоторые данные, это требует выполнения нескольких небольших задач, таких как чтение и заполнение данных во внутреннем объекте, установление соединения с SQL сервером и сохранение запроса там и. т. д.
Так как SQL-сервер, например, скорее всего, работает на другом компьютере в сети и работает под другим процессом, это может занять много времени. А, если приложение работает в одном потоке, тогда экран устройства пользователя будет находиться в неактивном состоянии до тех пор, пока все задачи не будут завершены, что является примером очень плохого пользовательского интерфейса. Вот почему многие приложения и новые фреймворки полностью полагаются на асинхронную модель, так как она позволяет выполнять множество задач, при этом сохраняя отзывчивость интерфейса.
Эффективность приложения также очень важна. Подсчитано, что при выполнении запроса около 70-80% времени теряется в ожидании зависимых задач. Поэтому, это место где асинхронное программирование как нельзя лучше придется кстати.
Таким образом, в данной статье мы рассмотрели, что такое синхронное и асинхронного программирование. Особый акцент был сделан на асинхронное программирование, так оно лежит в основе подавляющего большинства современных средств разработки. А в следующих статьях мы познакомимся с реальными примерами, использующими асинхронную модель.
-
 Создано 03.07.2018 10:47:38
Создано 03.07.2018 10:47:38 -
 Михаил Русаков
Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
myrusakov.ru
асинхронный поток данных — это… Что такое асинхронный поток данных?
- асинхронный поток данных
Engineering: asynchronous data stream
Универсальный русско-английский словарь. Академик.ру. 2011.
- асинхронный последовательный стык
- асинхронный преобразователь частоты
Смотреть что такое «асинхронный поток данных» в других словарях:
Поток выполнения — Для термина «Поток» см. другие значения. Процесс с двумя потоками выполнения на одном процессоре Поток выполнения (анг … Википедия
EDH-метод обнаружения и визуализации ошибок в последовательном транспортном потоке данных — 3.1.49 EDH метод обнаружения и визуализации ошибок в последовательном транспортном потоке данных (error detection and handling; EDH): Метод диагностики ошибок в последовательном транспортном потоке данных, заключающийся в сравнении контрольных… … Словарь-справочник терминов нормативно-технической документации
Универсальный асинхронный приёмопередатчик — (УАПП, англ. Universal Asynchronous Receiver Transmitter (UART)) узел вычислительных устройств, предназначенный для связи с другими цифровыми устройствами. Преобразует заданный набор данных в последовательный вид так, чтобы было… … Википедия
универсальный асинхронный приемо-передатчик — УАПП Интерфейсная схема, позволяющая принимать асинхронный последовательный поток информации и преобразовывать его в параллельные каналы и наоборот. Обычно используется для подключения удаленных терминалов к линии передачи данных. [Л.М. Невдяев.… … Справочник технического переводчика
ГОСТ Р 53531-2009: Телевидение вещательное цифровое. Требования к защите информации от несанкционированного доступа в сетях кабельного и наземного телевизионного вещания. Основные параметры. Технические требования — Терминология ГОСТ Р 53531 2009: Телевидение вещательное цифровое. Требования к защите информации от несанкционированного доступа в сетях кабельного и наземного телевизионного вещания. Основные параметры. Технические требования оригинал документа … Словарь-справочник терминов нормативно-технической документации
КР1816ВЕ51 — Intel P8051 Intel 8051 это однокристальный микроконтроллер (не путать с процессором) гарвардской архитектуры, который был впервые произведен 1980 году, для использования во встраиваемых системах. В течение 1980 ых и начале 1990 ых годов был… … Википедия
Модель акторов — В компьютерных науках модель акторов представляет собой математическую модель параллельных вычислений, которая трактует понятие «актор» как универсальный примитив параллельного численного расчёта: в ответ на сообщения, которые он получает, актор… … Википедия
Intel 8051 — Intel P8051 Intel 8051 это однокристальный микроконтроллер (не путать с процессором) гарвардской архитектуры, который был впервые произведен Intel в 1980 году … Википедия
16550 UART — Микросхема NS16550AFN 16550 UART (англ. universal asynchronous receiver/transmitter) это интегральная микросхема … Википедия
Инфраструктура — (Infrastructure) Инфраструктура это комплекс взаимосвязанных обслуживающих структур или объектов Транспортная, социальная, дорожная, рыночная, инновационная инфраструктуры, их развитие и элементы Содержание >>>>>>>> … Энциклопедия инвестора
Трансформатор — У этого термина существуют и другие значения, см. Трансформатор (значения). Трансформатор силовой ОСМ 0,16 Однофазный сухой многоцелевого назначения мощностью 0.16 кВт … Википедия
universal_ru_en.academic.ru
Асинхронное и синхронное выполнение, что это значит? — asynchronous
Синхронный/асинхронный НЕ НУЖНО СДЕЛАТЬ С МНОЖЕСТВЕННОЙ РЕЗЬБОЙ.
Синхронный или Синхронный означает «подключен» или «зависит» каким-то образом. Другими словами, две синхронные задачи должны быть осведомлены друг о друге, и одна задача должна выполняться каким-то образом, которая зависит от другой, например, ждать до начала выполнения другой задачи.
Асинхронный означает, что они полностью независимы и ни один из них не должен рассматривать другого каким-либо образом, либо в начале, либо в процессе исполнения.
Синхронный (один поток):
1 thread -> |<---A---->||<----B---------->||<------C----->|
Синхронный (многопоточный):
thread A -> |<---A---->|
\
thread B ------------> ->|<----B---------->|
\
thread C ----------------------------------> ->|<------C----->|
Асинхронный (один поток):
A-Start ------------------------------------------ A-End
| B-Start -----------------------------------------|--- B-End
| | C-Start ------------------- C-End | |
| | | | | |
V V V V V V
1 thread->|<-A-|<--B---|<-C-|-A-|-C-|--A--|-B-|--C-->|---A---->|--B-->|
Асинхронный (многопотоковый):
thread A -> |<---A---->|
thread B -----> |<----B---------->|
thread C ---------> |<------C--------->|
- Начальные и конечные точки задач A, B, C, представленные символами
<,>. - Временные срезы процессора, представленные вертикальными столбцами
|
Технически концепция синхронного/асинхронного действительно не имеет ничего общего с потоками. Хотя, в общем, необычно находить асинхронные задачи, запущенные в одном потоке, это возможно (см. Ниже примеры), и обычно бывает, что две или более задачи выполняются синхронно на отдельных потоках… Нет, концепция синхронного/асинхронного должен выполняться только с тем, можно ли инициировать вторую или последующую задачу до того, как другая (первая) задача завершится, или она должна ждать. Вот и все. Какой поток (или потоки), или процессы,
qaru.site
Использование асинхронного обмена сообщениями для улучшения доступности
Привет, Хаброжители! Мы недавно сдали в типографию книгу Криса Ричардсона, цель которой — научить успешно разрабатывать приложения с использованием микросервисной архитектуры. В книге обсуждаются не только преимущества, но и недостатки микросервисов. Вы узнаете, в каких ситуациях имеет смысл применять их, а когда лучше подумать о монолитном подходе.Основное внимание в книге уделяется архитектуре и разработке. Она рассчитана на любого, в чьи обязанности входят написание и доставка программного обеспечения, в том числе на разработчиков, архитекторов, технических директоров и начальников отделов по разработке.
Ниже представлен отрывок из книги «Использование асинхронного обмена сообщениями»
Использование асинхронного обмена сообщениями для улучшения доступности
Как вы видели, разнообразные механизмы IPC подталкивают вас к различным компромиссам. Один из них связан с тем, как механизм IPC влияет на доступность. В этом разделе вы узнаете, что синхронное взаимодействие с другими сервисами в рамках обработки запросов снижает степень доступности приложения. В связи с этим при проектировании своих сервисов вы должны по возможности использовать асинхронный обмен сообщениями.
Сначала посмотрим, какие проблемы создает синхронное взаимодействие и как это сказывается на доступности.
3.4.1. Синхронное взаимодействие снижает степень доступности
REST — это чрезвычайно популярный механизм IPC. У вас может возникнуть соблазн использовать его для межсервисного взаимодействия. Но проблема REST заключается в том, что это синхронный протокол: HTTP-клиенту приходится ждать, пока сервис не вернет ответ. Каждый раз, когда сервисы общаются между собой по синхронному протоколу, это снижает доступность приложения.
Чтобы понять, почему так происходит, рассмотрим сценарий, представленный на рис. 3.15. У сервиса Order есть интерфейс REST API для создания заказов. Для проверки заказа он обращается к сервисам Consumer и Restaurant, которые тоже имеют REST API.
Создание заказа состоит из такой последовательности шагов.
- Клиент делает HTTP-запрос POST /orders к сервису Order.
- Сервис Order извлекает информацию о заказчике, выполняя HTTP-запрос GET /consumers/id к сервису Consumer.
- Сервис Order извлекает информацию о ресторане, выполняя HTTP-запрос GET /restaurant/id к сервису Restaurant.
- Order Taking проверяет запрос, задействуя информацию о заказчике и ресторане.
- Order Taking создает заказ.
- Order Taking отправляет HTTP-ответ клиенту.
Поскольку эти сервисы используют HTTP, все они должны быть доступны, чтобы приложение FTGO смогло обработать запрос CreateOrder. Оно не сможет создать заказ, если хотя бы один из сервисов недоступен. С математической точки зрения доступность системной операции является произведением доступности сервисов, которые в нее вовлечены. Если сервис Order и те два сервиса, которые он вызывает, имеют доступность 99,5 %, то их общая доступность будет 99,5 %3 = 98,5 %, что намного ниже. Каждый последующий сервис, участвующий в запросе, делает операцию менее доступной.
Эта проблема не уникальна для взаимодействия на основе REST. Доступность снижается всякий раз, когда для ответа клиенту сервис должен получить ответы от других сервисов. Здесь не поможет даже переход к стилю взаимодействия «запрос/ответ» поверх асинхронных сообщений. Например, если сервис Order пошлет сервису Consumer сообщение через брокер и примется ждать ответа, его доступность ухудшится.
Если вы хотите максимально повысить уровень доступности, минимизируйте объем синхронного взаимодействия. Посмотрим, как это сделать.
3.4.2. Избавление от синхронного взаимодействия
Существует несколько способов уменьшения объема синхронного взаимодействия с другими сервисами при обработке синхронных запросов. Во-первых, чтобы полностью избежать этой проблемы, все сервисы можно снабдить исключительно асинхронными API. Но это не всегда возможно. Например, публичные API обычно придерживаются стандарта REST. Поэтому некоторые сервисы обязаны иметь синхронные API.
К счастью, чтобы обрабатывать синхронные запросы, вовсе не обязательно выполнять их самому. Поговорим о таких вариантах.
Использование асинхронных стилей взаимодействия
В идеале все взаимодействие должно происходить в асинхронном стиле, описанном ранее в этой главе. Представьте, к примеру, что клиент приложения FTGO применяет для создания заказов асинхронный стиль взаимодействия вида «запрос/асинхронный ответ». Чтобы создать заказ, он отправляет сообщение с запросом сервису Order. Затем этот сервис асинхронно обменивается сообщениями с другими сервисами и в итоге возвращает клиенту ответ (рис. 3.16).
Клиент и сервис общаются асинхронно, отправляя сообщения через каналы. Ни один из участников этого взаимодействия не блокируется в ожидании ответа.
Такая архитектура была бы чрезвычайно устойчивой, потому что брокер буферизирует сообщения до тех пор, пока их потребление не станет возможным. Но проблема в том, что у сервисов часто есть внешний API, который использует синхронный протокол вроде REST и, как следствие, обязан немедленно отвечать на запросы.
Если у сервиса есть синхронный API, доступность можно улучшить за счет репликации данных. Посмотрим, как это работает.
Репликация данных
Одним из способов минимизации синхронного взаимодействия во время обработки запросов является репликация данных. Сервис хранит копию (реплику) данных, которые ему нужны для обработки запросов. Чтобы поддерживать реплику в актуальном состоянии, он подписывается на события, публикуемые сервисами, которым эти данные принадлежат. Например, сервис Order может хранить копию данных, принадлежащих сервисам Consumer и Restaurant. Это позволит ему обрабатывать запросы на создание заказов, не обращаясь к этим сервисам. Такая архитектура показана на рис. 3.17.
Сервисы Consumer и Restaurant публикуют события всякий раз, когда их данные меняются. Сервис Order подписывается на эти события и обновляет свою реплику.
В некоторых случаях репликация данных — это хорошее решение. Например, в главе 5 описывается, как сервис Order реплицирует данные сервиса Restaurant, чтобы иметь возможность проверять элементы меню. Один из недостатков этого подхода связан с тем, что иногда он требует копирования больших объемов данных, что неэффективно. Например, если у нас много заказчиков, хранить реплику данных, принадлежащих сервису Consumer, может оказаться непрактично. Еще один недостаток репликации кроется в том, что она не решает проблему обновления данных, принадлежащих другим сервисам.
Чтобы решить эту проблему, сервис может отсрочить взаимодействие с другими сервисами до тех пор, пока он не ответит своему клиенту. Речь об этом пойдет далее.
Завершение обработки после возвращения ответа
Еще один способ устранения синхронного взаимодействия во время обработки запросов состоит в том, чтобы выполнять эту обработку в виде следующих этапов.
- Сервис проверяет запрос только с помощью данных, доступных локально.
- Он обновляет свою базу данных, в том числе добавляет сообщения в таблицу OUTBOX.
- Возвращает ответ своему клиенту.
Во время обработки запроса сервис не обращается синхронно ни к каким другим сервисам. Вместо этого он шлет им асинхронные сообщения. Данный подход обеспечивает слабую связанность сервисов. Как вы увидите в следующей главе, этот процесс часто реализуется в виде повествования.
Представьте, что сервис Order действует таким образом. Он создает заказ с состоянием PENDING и затем проверяет его, обмениваясь асинхронными сообщениями с другими сервисами. На рис. 3.18 показано, что происходит при вызове операции createOrder(). Цепочка событий выглядит так.
- Сервис Order создает заказ с состоянием PENDING.
- Сервис Order возвращает своему клиенту ответ с ID заказа.
- Сервис Order шлет сообщение ValidateConsumerInfo сервису Consumer.
- Сервис Order шлет сообщение ValidateOrderDetails сервису Restaurant.
- Сервис Consumer получает сообщение ValidateConsumerInfo, проверяет, может ли заказчик размещать заказ, и отправляет сообщение ConsumerValidated сервису Order.
- Сервис Restaurant получает сообщение ValidateOrderDetails, проверяет корректность элементов меню и способность ресторана доставить заказ по заданному адресу и отправляет сообщение OrderDetailsValidated сервису Order.
- Сервис Order получает сообщения ConsumerValidated и OrderDetailsValidated и меняет состояние заказа на VALIDATED.
И так далее…
Сервис Order может получить сообщения ConsumerValidated и OrderDetailsValidated в любом порядке. Чтобы знать, какое из них он получил первым, он меняет состояние заказа. Если первым пришло сообщение ConsumerValidated, состояние заказа меняется на CONSUMER_VALIDATED, а если OrderDetailsValidated — на ORDER_DETAILS_VALIDATED. Получив второе сообщение, сервис Order присваивает заказу состояние VALIDATED.
После проверки заказа сервис Order выполняет оставшиеся шаги по его созданию, о которых мы поговорим в следующей главе. Замечательной стороной этого подхода является то, что сервис Order сможет создать заказ и ответить клиенту, даже если сервис Consumer окажется недоступным. Рано или поздно сервис Consumer восстановится и обработает все отложенные сообщения, что позволит завершить проверку заказов.
Недостаток возвращения ответа до полной обработки запроса связан с тем, что это делает клиент более сложным. Например, когда сервис Order возвращает ответ, он дает минимальные гарантии по поводу состояния только что созданного заказа. Он отвечает немедленно, еще до проверки заказа и авторизации банковской карты клиента. Таким образом, чтобы узнать о том, успешно ли создан заказ, клиент должен периодически запрашивать информацию или же сервис Order должен послать ему уведомительное сообщение. Несмотря на всю сложность этого подхода, во многих случаях стоит предпочесть его, особенно из-за того, что он учитывает проблемы с управлением распределенными транзакциями, которые мы обсудим в главе 4. В главах 4 и 5 я продемонстрирую эту методику на примере сервиса Order.
Резюме
- Микросервисная архитектура является распределенной, поэтому межпроцессное взаимодействие играет в ней ключевую роль.
- К развитию API сервиса необходимо подходить тщательно и осторожно. Легче всего вносить обратно совместимые изменения, поскольку они не влияют на работу клиентов. При внесении ломающих изменений в API сервиса обычно приходится поддерживать как старую, так и новую версию, пока клиенты не обновятся.
- Существует множество технологий IPC, каждая со своими достоинствами и недостатками. Ключевое решение на стадии проектирования — выбор между синхронным удаленным вызовом процедур и асинхронными сообщениями. Самыми простыми в использовании являются синхронные протоколы вроде REST, основанные на вызове удаленных процедур. Но в идеале, чтобы повысить уровень доступности, сервисы должны взаимодействовать с помощью асинхронного обмена сообщениями.
- Чтобы предотвратить лавинообразное накопление сбоев в системе, клиент, использующий синхронный протокол, должен быть способен справиться с частичными отказами — тем, что вызываемый сервис либо недоступен, либо проявляет высокую латентность. В частности, при выполнении запросов следует отсчитывать время ожидания, ограничивать количество просроченных запросов и применять шаблон «Предохранитель», чтобы избежать обращений к неисправному сервису.
- Архитектура, использующая синхронные протоколы, должна содержать механизм обнаружения, чтобы клиенты могли определить сетевое местонахождение экземпляров сервиса. Проще всего остановиться на механизме обнаружения, который предоставляет платформа развертывания: на шаблонах «Обнаружение на стороне сервера» и «Сторонняя регистрация». Альтернативный подход — реализация обнаружения сервисов на уровне приложения: шаблоны «Обнаружение на стороне клиента» и «Саморегистрация». Этот способ требует бо’льших усилий, но подходит для ситуаций, когда сервисы выполняются на нескольких платформах развертывания.
- Модель сообщений и каналов инкапсулирует детали реализации системы обмена сообщениями и становится хорошим выбором при проектировании архитектуры этого вида. Позже вы сможете привязать свою архитектуру к конкретной инфраструктуре обмена сообщениями, в которой обычно используется брокер.
- Ключевая трудность при обмене сообщениями связана с их публикацией и обновлением базы данных. Удачным решением является применение шаблона «Публикация событий»: сообщение в самом начале записывается в базу данных в рамках транзакции. Затем отдельный процесс извлекает сообщение из базы данных, используя шаблон «Опрашивающий издатель» или «Отслеживание транзакционного журнала», и передает его брокеру.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 30% на предзаказ книги по купону — Микросервисы
habr.com
Путаница в отношении потоков, и если асинхронные методы действительно асинхронны в С# — c#
Это немного непонятно для меня, вероятно, потому, что определение асинхронности в моей голове не выстраивается.
Хорошо, что вы просите разъяснений.
На мой взгляд, поскольку в основном я использую UI dev, асинхронный код — это код, который не запускается в потоке пользовательского интерфейса, а в другом потоке.
Эта вера распространена, но ложна. Нет требования, чтобы асинхронный код работал на любом втором потоке.
Представьте, что вы готовите завтрак. Вы помещаете тост в тостер, и пока вы ждете, когда тост попсует, вы просматриваете почту со вчерашнего дня, оплачиваете некоторые счета, и, эй, выскочил тост. Вы закончите оплатить этот счет, а затем перелейте его в тост.
Где вы там наняли второго рабочего, чтобы посмотреть ваш тостер?
Вы этого не сделали. Темы — это рабочие. Асинхронные рабочие процессы могут выполняться в одном потоке. Точка асинхронного рабочего процесса заключается в том, чтобы не нанимать больше рабочих, если вы можете избежать этого.
Если у меня длинная работа, связанная с ЦП (скажем, она делает много жесткой математики), то выполнение этой задачи асинхронно должно блокировать некоторые потоки правильно? Что-то должно действительно выполнять математику.
Здесь я дам вам тяжелую проблему. Здесь находится столбец из 100 номеров; пожалуйста, добавьте их вручную. Таким образом, вы добавляете первое ко второму и суммируете. Затем вы добавляете общее количество в третье и получаете общее количество. Тогда, о, черт, вторая страница цифр отсутствует. Помните, где вы были, и сделайте тосты. Ах, когда тост был тостов, письмо пришло с остальными номерами. Когда вы закончите смазывать тосты, продолжайте добавлять эти цифры и не забудьте съесть тост в следующий раз, когда у вас будет свободный момент.
Где находится часть, где вы наняли другого работника для добавления чисел? Вычислительная дорогостоящая работа не обязательно должна быть синхронной и не должна блокировать поток. То, что делает вычислительную работу потенциально асинхронной, — это возможность остановить ее, вспомнить, где вы были, пойти на что-то еще, запомнить, что делать после этого, и возобновить, где вы остановились.
Теперь, безусловно, можно нанять второго работника, который ничего не делает, кроме как добавить номера, а затем уволен. И вы могли бы спросить, что рабочий «вы закончили?» и если ответ отрицательный, вы можете пойти сэндвичем, пока они не закончатся. Таким образом,
qaru.site