Периодический повторный инструктаж — Большая Энциклопедия Нефти и Газа, статья, страница 1
Периодический повторный инструктаж
Cтраница 1
Периодический повторный инструктаж по безопасным приемам и методам работы проводится со всеми рабочими независимо от их квалификации и стажа работы по данной профессии через 3 — 6 месяцев. [1]
Периодический повторный инструктаж — проводится мастером в сроки, установленные распоряжением главного инженера завода; внеплановый — проводится теми же мастерами участков при изменении технологического процесса, при нарушении рабочим правил личной безопасности или при травме, вызванной недостаточностью знаний по безопасному ведению работ. [2]
Периодический повторный инструктаж проводится также мастером производственного участка по плану ( графику) проведения инструктажа, утверждаемому начальником цеха. В соответствии с примерным положением о порядке инструктажа и обучения рабочих безопасным приемам и методам работы все рабочие независимо от стажа работы и квалификации должны ежеквартально проходить повторный инструктаж по охране труда, технике безопасности и производственной санитарии.
[3]
В соответствии с примерным положением о порядке инструктажа и обучения рабочих безопасным приемам и методам работы все рабочие независимо от стажа работы и квалификации должны ежеквартально проходить повторный инструктаж по охране труда, технике безопасности и производственной санитарии.
[3]
Периодический повторный инструктаж проводится мастером производственного участка один раз в квартал или полугодие, исходя из особенностей конкретных профессии. При проведении повторных инструктажей выясняется знание рабочими правил техники безопасности, даются практические советы с показом безопасных приемов работы. Повторный инструктаж проводится один раз в квартал или полугодие, в зависимости от особенностей профессии. При выявлении неудовлетворительного знания рабочим инструкций по технике безопасности инструктирующий проводит обучение непосредственно на рабочем месте. [4]
Периодический повторный инструктаж
проводится также мастером производственного участка по плану ( графику) проведения инструктажа, утверждаемому начальником цеха. В соответствии с примерным положением о порядке инструктажа и обучения рабочих безопасным приемам и методам работы все рабочие независимо от стажа работы и квалификации должны ежеквартально проходить повторный инструктаж по охране труда, технике безопасности и производственной санитарии.
[5]
В соответствии с примерным положением о порядке инструктажа и обучения рабочих безопасным приемам и методам работы все рабочие независимо от стажа работы и квалификации должны ежеквартально проходить повторный инструктаж по охране труда, технике безопасности и производственной санитарии.
[5]Периодический повторный инструктаж должен организовываться непосредственно на рабочем месте по той же программе, что и первичный. Он проводится в форме живой беседы, с показом безопасных приемов и методов производства технологических операций, разбором несчастных случаев, происшедших на данном предприятии, и раскрытием причин, которые их вызвали. Инструктирующий обязательно должен убедиться в четком знании и понимании каждым работающим правил безопасности и требовать от него строгого выполнения их. [6]
Периодический повторный инструктаж проводят по той же программе, что и первичный, не реже, чем через каждые 3 месяца, по указанию и под контролем начальника компрессорного цеха. [7]
[7]
Периодический повторный инструктаж по безопасным приемам и методам работы проводится со всеми рабочими независимо от их квалификации и стажа работы по данной профессии через 3 — 6 месяцев. [8]
Все рабочие каждый квартал проходят периодический повторный инструктаж по безопасным приемам и методам работы. Он проводится в форме беседы и разбора конкретных примеров. Инструктирующий должен убедиться в четком знании и понимании каждым рабочим правил безопасности. Если будет выявлено неудовлетворительное знание рабочими инструкции по технике безопасности ( применение запрещенных рабочих приемов, работа без предохранительных ограждений и защитных средств и др.), то инструктирующий сам дает необходимые объяснения. [9]
Для закрепления знаний работающих проводят периодические повторные инструктажи — проверку знаний. Сроки их проведения с рабочими и лаборантами — не реже одного раза в полугодие, с инженерно-техническими работниками ( старшими лаборантами и научными сотрудниками), за исключением начальника лаборатории и его заместителя, — не реже одного раза в год.
[10]
Сроки их проведения с рабочими и лаборантами — не реже одного раза в полугодие, с инженерно-техническими работниками ( старшими лаборантами и научными сотрудниками), за исключением начальника лаборатории и его заместителя, — не реже одного раза в год.
[10]
Для закрепления знаний работающих проводят периодические повторные инструктажи — проверку знаний. Сроки их проведения с рабочими и лаборантами — не реже одного раза в полугодие, с инженерно-техническими работниками ( старшими лаборантами и научными сотрудниками), за исключением начальника лаборатории и его заместителя, — не реже одного раза в год. [11]
Для закрепления знаний работающих — проводятся периодические повторные инструктажи — проверки знаний. [12]
Для всех работающих раз в полгода проводится периодический повторный инструктаж. [13]
Со всеми работающими на предприятии должен производиться периодический повторный инструктаж по технике безопасности. Сроки периодического инструктажа устанавливаются главным инженером предприятия в зависимости от сложности и опасности выполняемой работы, но не реже 1 раза в 6 мес.
[14]
Сроки периодического инструктажа устанавливаются главным инженером предприятия в зависимости от сложности и опасности выполняемой работы, но не реже 1 раза в 6 мес.
[14]
Не реже одного раза в три месяца администрация цеха должна проводить периодический повторный инструктаж рабочих по технике безопасности и промышленной санитарии. Вводный инструктаж на рабочем месте, а также повторный инструктаж регистрируется в специальном журнале, в котором должны расписаться: лицо, проводившее инструктаж, и лицо, получившее инструктаж. [15]
Страницы: 1 2 3
Какова периодичность проведения повторного инструктажа по охране труда
Правила безопасности написаны кровью тех, кто их игнорировал. Это золотое правило, что должно быть выучено всеми. Но, увы, людям свойственно забывать и игнорировать возможные последствия. Чтобы поддерживать сотрудников в тонусе, проводится повторный инструктаж. Что он собой представляет? С какой целью проводят? Кто должен проходить? Есть ли освобождённые от него? Вот эти вопросы и будут рассматриваться в статье.
Чтобы поддерживать сотрудников в тонусе, проводится повторный инструктаж. Что он собой представляет? С какой целью проводят? Кто должен проходить? Есть ли освобождённые от него? Вот эти вопросы и будут рассматриваться в статье.
С какой целью проводится повторный инструктаж
Инструктаж — это информирование и проверка навыков и знаний, необходимых для безопасной работы и избегания травматических ситуаций. Если при тестировании лицо продемонстрировало неудовлетворительный результат, оно не допускается к самостоятельной работе, пока не пройдёт инструктаж ещё раз. В таком случае издают приказ о временном отстранении лица от работы. Соответствующая информация отмечается в журнале регистрации. Также отметки могут вноситься и в личную карточку проверяемого.
Инструктаж техники безопасности
Повторный инструктаж по охране труда проводится:
- индивидуально;
- с группой лиц;
- в пределах общего рабочего места.
Повторный инструктаж следует проводить не реже раза в шесть месяцев.
К сведению! Информирование следует сопровождать демонстрированием безопасных приёмов и методов, доступных к использованию при выполнении должностных обязанностей.
Если игнорируется повторный инструктаж по охране труда, периодичность не выполняется, в таком случае на компанию проверяющими структурами налагаются взыскания. Благо, с бюрократической точки зрения процесс организовывается без проблем. Так, для повторного инструктажа используются те же программы и документы, что и для первичного, поэтому его проведение не забирает много сил.
Инструктаж охраны труда
В документ рекомендуется включать:
- общие сведения, информирующие про условия труда. К таковым относятся данные о производственной среде, используемом оборудовании, технологических и трудовых процессах;
- порядок подготовки. В него включены методы и приёмы, требования к специальной одежде, проверка исправности средств защиты и оборудования;
- схему безопасного перемещения по территории;
- инструкции по охране труда и безопасности на рабочем месте;
- аварийные ситуации, которые потенциально могут возникнуть.

Как часто проводится повторный инструктаж
Универсального решения здесь не существует. Законодательством предусмотрено, что работник должен быть информирован о положении дел как минимум раз в полгода. Минимальный срок, через который должно осуществляться информирование, не регулирован.
Обратите внимание! Если в рамках работы существует высокая опасность травматизма и возникновения нежелательных последствий для здоровья или жизни, информирование и проверка навыков могут проводиться каждый раз перед выполнением должностных обязанностей.
Это отображено в нормативных требованиях. Так, рабочий, трудящийся с оборудованием повышенной опасности, обязан проходить повторный инструктаж не реже чем раз в три месяца.
Информирование о технике безопасности
Впрочем, возможно и увеличение оговорённых сроков. Законодательством предусматривается, что организации, при условии согласования с местными органами государственного надзора и профсоюзными комитетами, могут увеличивать периодический срок проведения повторного инструктажа до одного года. Такая возможность существует только для некоторых категорий сотрудников. Так, если обычный офисный сотрудник работает с неопасной техникой или бумагами, то сравнивать его с пожарным по уровню подвергаемой опасности — глупость.
Такая возможность существует только для некоторых категорий сотрудников. Так, если обычный офисный сотрудник работает с неопасной техникой или бумагами, то сравнивать его с пожарным по уровню подвергаемой опасности — глупость.
Важно! Несоблюдение установленных норм карается взысканием со стороны органов государственного надзора.
Кто должен проходить повторный инструктаж
Информирование и проверка предусмотрены для всех трудящихся одной должности (профессии) из структурного подразделения. Оформляется и является основанием для повторного инструктажа указание (распоряжение) непосредственного руководителя или ответственного за охрану труда. Также такими полномочиями обладает главный инженер предприятия, при условии, что эта должность предусмотрена в штате.
Ответственное лицо обязано:
- ознакомить с существующими производственными процессами на рабочем месте, сопровождающими опасностями и возможными вредностями;
- освоить или освежить положения охраны труда и безопасные приёмы осуществления деятельности;
- продемонстрировать достаточное количество навыков и знаний, позволяющих вести безопасную работу, разбираться в нормативной, технической и эксплуатационной документации.

Обратите внимание! Техник или водитель, грузчик или токарь — все должны быть проинформированы о возможных последствиях.
Кто освобождается от прохождения
Несмотря на существование жесткого нормативно-правого порядка, для отдельных категорий лиц предусмотрено исключение. Перечень должностей и профессий, освобождённых от повторного инструктажа, утверждается работодателем.
Предусматривается особенный режим по отношению к работникам, которые не связаны непосредственно с обслуживанием различных механизмов, машин, оборудования, объектов, использованием инструментов и приборов, переработкой или сохранением материалов, сырья и тому подобное. К таковым, в первую очередь, относят инженерно-технический персонал предприятия.
Ознакомление с требованиями охраны труда
Отдельно стоит упомянуть сотрудников, которые на момент повторного инструктажа были в отпуске или болели. На такой случай предусматривается внеплановое информирование, проводимое после выхода на работу. Проходить инструктирование можно и раньше указанного срока. Например, когда у работника запланирован отпуск. Но это допускается только в тех случаях, если за оговоренное время на производстве ничего не поменяется.
Проходить инструктирование можно и раньше указанного срока. Например, когда у работника запланирован отпуск. Но это допускается только в тех случаях, если за оговоренное время на производстве ничего не поменяется.
Кому поручают проведение повторного инструктажа на рабочем месте
Обязан информировать и проверять навыки непосредственный руководитель. Им может быть преподаватель, инструктор производственного обучения или же мастер. Выбор конкретного варианта зависит от численности трудящихся. Также к отдельным категориям лиц могут выдвигаться дополнительные требования. Например, инструкторы должны пройти подготовку и проверку полученных знаний в специальных профильных образовательных центрах.
Если численность предприятия превышает отметку в 50 человек, то следует назначать отдельных специалистов или организовывать самостоятельные подразделения. До 50 — вопросами безопасности может заниматься лично руководитель, заключать договоры со специализированными организациями, поручать сотрудникам.
Обратите внимание! Обучающая школа может не только следить за получением знаний, но и оценивать качество усвоения предоставленных знаний. По сути, она перебирает все задачи специалистов на себя, беря эту сферу на аутсорсинг.
Повторный инструктаж для дистанционных работников и надомников
За правилами техники безопасности должны следить все, в том числе и дистанционные работники, к которым относят сотрудников, работающих на дому. Для них актуальны общие положение, предусматривающие проведение повторного инструктажа не реже раза в шесть месяцев.
Законодательство предусматривает возможность дистанционной проверки уровня знаний и навыков сотрудника. Подтверждается прохождение посредством обмена электронными документами. Правда, актуально это только по отношению к дистанционным работникам.
Обратите внимание! К надомникам требования несколько иные. Их труд допускается только при регулярных полугодовых инструктажах, что является требованием охраны труда. А это возможно исключительно на рабочем месте сотрудника. Поэтому инструктор обязан выезжать на место осуществления деятельности.
А это возможно исключительно на рабочем месте сотрудника. Поэтому инструктор обязан выезжать на место осуществления деятельности.
Проведение повторного инструктажа для подрядчиков
В законодательной документации не предусмотрено, кто обязан заниматься проведением повторного инструктажа для сотрудников привлеченной организации. Это должно решаться в индивидуальном порядке между заказчиком и подрядчиком. В законодательстве оговорено только прохождение вводного инструктажа. Сделать это обязана организация-заказчик.
Инструктирование перед началом работы
Все остальные виды информирования и проверки навыков обычно осуществляет структура-подрядчик. Впрочем, здесь есть свои нюансы. Поскольку подрядчиком осуществляются работы на территории заказчика, необходимо следить за соблюдением норм безопасности на отведённой площадке, к числу которых относится и прохождение повторного инструктажа.
Фиксирование проведения повторного инструктажа в журнале
Регистрация соблюдения установленных норм необходима для подтверждения фактов исполнения действующего законодательства. На этот случай предусмотрена необходимость совершения записей в установленных документах, которыми являются журналы проведения повторного инструктажа.
На этот случай предусмотрена необходимость совершения записей в установленных документах, которыми являются журналы проведения повторного инструктажа.
Работодатели обязаны придерживаться этого требования. При этом следует использовать одинаковую форму журнала во всех подразделениях. Фиксировать факт взаимодействия с сотрудниками, во время которого обговариваются различные риски и возможности безопасного выполнения обязанностей, следует, чтобы иметь доказательную базу выполнения мероприятия.
В журнале должно быть зафиксировано, что сотрудник ознакомлен со своим будущим рабочим местом, выполняемыми функциями, правилами безопасной деятельности и используемым оборудованием. При переводе на другую должность и изменении условий труда проводится первичный инструктаж, а затем, спустя определённое время, вторичное информирование и проверка.
Важно! Нельзя игнорировать человеческий фактор, ведь, даже если был проведён повторный инструктаж, сознательное пренебрежение человека к полученной информации исключать нельзя со всеми последствиями.
Оформление
Всегда должно указываться предприятие, для которого осуществляется фиксация проведённых мероприятий в журнале. Также следует предусмотреть указание номера подразделения, участка работы, дат начала и окончания заполнения документа.
Рекомендуется предусматривать в журнале требуемые инструкции и доводимую до работника информацию. В отведённых графах заполняются дата инструктажа, инициалы и фамилия сотрудника, его должность, номер инструктажа, согласно нормам охраны труда, причины проведения и подписи, как ответственного, так и инструктируемого.
Обратите внимание! Писать следует красивым и четким почерком. Не рекомендуется использовать специальную замазку. Предпочтительный вариант — внесение поправки и аккуратное зачеркивание неверной записи. Можно ставить звездочку или сноску, а внизу указывать причину или суть ошибки.
Чтобы исключить подозрения и сомнения со стороны проверяющих, журнал следует пронумеровать и прошить. Хранить документ следует не менее 10 лет после окончания его срока ведения.
Хранить документ следует не менее 10 лет после окончания его срока ведения.
В процессе заполнения журнал следует хранить на рабочем месте, чтобы он в любое время был доступен при осуществлении проверки. Действующие инструкции рекомендуется вклеивать, чтобы не пропустить ни одной бумаги при инструктировании сотрудника. Дополнительные рекомендации следует фиксировать в местном нормативном акте для организации единообразия на подведомственной предприятию территории.
Ответственность за несвоевременное проведение
Законодательно предусмотрено, что, если было нарушено время повторного инструктажа по охране труда, то на организацию накладывается взыскание. Налагаются они только на работодателя. Предусматривается административная и уголовная ответственность.
Обратите внимание! Ответственность несут физические лица-предприниматели и должностные сотрудники, на которых возложены обязанности.
Административная ответственность наступает согласно действующим положениям соответствующего кодекса. За нарушения предусматривается выплата штрафа. Чем более существенный проступок, тем выше взыскание. Повторное обнаружение одной и той же проблемы влечёт увеличение сумм взыскания.
За нарушения предусматривается выплата штрафа. Чем более существенный проступок, тем выше взыскание. Повторное обнаружение одной и той же проблемы влечёт увеличение сумм взыскания.
Требования охраны труда
Уголовная ответственность предусматривается в тех случаях, если был причинён вред здоровью жизни человека или имел место быть летальный исход. Например, если электрик не был проинструктирован относительно требований электробезопасности при работе на объекте, зависимо от тяжести полученных им повреждений предусматриваются штраф, исправительные работы, ограничение или лишение свободы для ответственного лица. Поэтому это требование законодательства следует выполнять, иначе можно отправиться в отдалённые места на срок в несколько лет.
Соблюдение техники безопасности позволяет сохранить здоровье и жизнь человека, повысить результативность деятельности предприятия (благодаря минимизации количества негативных происшествий) и сохранить от ненужных трат. Следует ответственно подходить к охране труда и разработать разумную инструкцию, ведь преследуемая цель — избавить от издержек и улучшить ситуацию до максимально возможного положения. Те, кто игнорирует эти моменты, расплачиваются своими деньгами, свободой, здоровьем и жизнью.
Те, кто игнорирует эти моменты, расплачиваются своими деньгами, свободой, здоровьем и жизнью.
Виды инструктажей по охране труда и порядок их проведения
Согласно российскому законодательству ответственность за соблюдение норм безопасности возлагается на работодателей. Что обязывает последних проводить инструктажи по охране труда с наемными работниками для их обучения общим основам безопасности и специфики поведения на рабочем месте. В данной статье мы рассмотрим, какие виды инструктажей по охране труда обязаны проводиться в рамках производственного обучения и их регулярность. Также мы кратко опишем, как организовывается процесс и рассматриваемые вопросы.
Что важно знать?
Во вводной части мы уже упоминали о персональной ответственности работодателя и возложенные на него обязанности за соблюдением норм охраны труда (далее ОТ) на предприятии. Это требует от руководства предприятия организовать проведение как общих, так и целевых инструктажей для безопасного выполнения работниками своих трудовых обязанностей. Инструктажи проводятся со всеми сотрудниками, без исключения, в соответствии с предусмотренными нормами, невзирая на форму собственности организации, и ее вида деятельности. Это положение также распространяется на прикомандированных лиц и всех, кто впервые оказывается на территории предприятия.
Это требует от руководства предприятия организовать проведение как общих, так и целевых инструктажей для безопасного выполнения работниками своих трудовых обязанностей. Инструктажи проводятся со всеми сотрудниками, без исключения, в соответствии с предусмотренными нормами, невзирая на форму собственности организации, и ее вида деятельности. Это положение также распространяется на прикомандированных лиц и всех, кто впервые оказывается на территории предприятия.
Данное мероприятие может проводиться индивидуально для каждого работника или коллективно, в зависимости от вида инструктажа и внутреннего распорядка. Ответственность за порядок проведения инструктажей возлагается на комиссию по ОТ, возглавлять которую должно лицо, входящее в состав руководства организации (директор, инженер предприятия и т.д.). Для небольших коллективов допускается ввод специальной штатной единицы специалиста, на которого возлагается ответственность за периодичность проведения инструктажей по ОТ.
На практике, руководство и главные инженеры редко непосредственно проводят такие мероприятия, они перепоручают данные обязанности службе охраны труда или ответственным лицам, прошедшим специальное обучение.
На предприятиях, а также в организациях и компаниях должны быть изданы соответствующие локальные акты, в которых регулируются порядок мероприятий по охране труда, согласно нормативам действующего законодательства.
Нормативные акты
Принимая во внимание, тот факт, что в ОТ входит множество аспектов (нормы, стандарты, правила и т.д.), каждая составляющая должна быть утверждена соответствующими нормативными актами, различной степени подчиненности. На текущий момент сфера ОТ регулируется следующими законодательными и подзаконными и отраслевыми актами:
- Трудовым кодексом (статья 212, 214 ТК РФ).
- Федеральным законодательством, в частности, законы №125 (от 24 июля 1998 г.) и №426 (28.12.2013).
- Постановление Минтруда РФ 13-01-2003-N-1-29, Приказы, ГОСТы, в частности ГОСТ 12.0.004-90 , ГОСТ 12.0.004-2015 и ГОСТ 12.0.230-2007, СНиПы, а также другие подзаконные акты.
- Локальные акты и производственные инструкции, принятые на предприятии и не противоречащие вышеперечисленным нормам.
Инструктажи по охране труда: порядок и сроки проведения
Данные мероприятия, согласно действующим нормам, принято подразделять на следующие виды: вводный, первичный, повторный, внеплановый и целевой. Рассмотрим подробно порядок проведения перечисленных мероприятий.
Виды, порядок и сроки инструктажейВводный
Проведение вводного инструктажа обязательно для лиц, поступающих на работу, командировочных, а также работников сторонних организаций, выполняющих различные виды работ на территории предприятия. Это требование касается и тех, кто проходит стажировку или производственное обучение (практику). Они в обязательном порядке должны быть предварительно проинструктированы.
Порядок проведения вводного инструктажаДругими словами, вводный инструктаж по ОТ, ТБ (технике безопасности) и ПБ (пожарной безопасности) должны проходить все получившие доступ на территорию предприятия, вне зависимости имеют они непосредственное отношение к производственной деятельности или нет. Мероприятие проводит специалист, утвержденный соответствующим приказом работодателя.
Мероприятие проводит специалист, утвержденный соответствующим приказом работодателя.
Первичный
Проведение первичного инструктажа возлагается на непосредственных руководителей. Данное мероприятие осуществляется на рабочем месте и обязательно в следующих случаях:
- Перед выполнением своих обязанностей новым работником, принятым на предприятие.
- С работником предприятия, переведенного с другого цеха, участка или подразделения.

- При выполнении нового вида работ.
- Если на участок командируется работник другого предприятия или нанят временный работник.
- Перед выполнением работ строительными бригадами, работающими на территории производственного участка.
- При поступлении стажеров, студентов и учащихся для прохождения производственной практики.
Программы и тексты первичных инструктажей должны содержать в себе информацию по охране труда и ТБ, с учетом профессиональной специфики, а также основы противопожарной безопасности.
Повторный (периодический)
Согласно установленному порядку, данное мероприятие должно осуществляться с периодичностью раз в шесть месяцев. Проходить его должны все сотрудники, ранее прослушавшие первичные инструкции на производственных участках и подразделениях предприятия.
Порядок проведения повторных инструктажейОтветственным за проведение повторного инструктажа назначается руководитель подразделения, участка или другой непосредственный начальник. По завершению мероприятия проводится устная проверка знаний требований охраны труда, ТБ и ПБ, после чего вносится соответствующая запись в журнал регистрации и заверяется обязательными подписями инструктируемого и инструктора.
По завершению мероприятия проводится устная проверка знаний требований охраны труда, ТБ и ПБ, после чего вносится соответствующая запись в журнал регистрации и заверяется обязательными подписями инструктируемого и инструктора.
Проходят повторный инструктаж как индивидуально, так и коллективно, если мероприятие предназначено для работников одного профессионального направления. На мероприятии рекомендуется рассматривать случаи нарушения норм охраны труда и основ ТБ, если таковые имели место.
Внеплановый
Для проведения данного мероприятия нормативными документами предусмотрены следующие случаи:
- Изменение текущих норм, правил или требований охраны труда, ТБ или ПБ, о которых необходимо незамедлительно поставить в известность работников предприятия.
- Модернизация оборудования или внесение изменений в технологию производства.
- Происшествие, вызванное нарушением норм и требований ТБ, охраны труда или трудовой дисциплины. Как правило, после этого работники проходят внеочередную проверку знаний.

- Получение предписания со стороны органов надзора или других контролирующих организаций о необходимости проведения внепланового мероприятия.
- Вынужденный перерыв работы на срок более двух месяцев для обычных видов деятельности или более месяца, если специализация предполагает повышенную опасность.
Данные мероприятие по основным аспектам аналогично периодическому, при этом акцентируется внимание на причине внепланового проведения. Содержание внепланового инструктажа определяется целью его проведения.
Обратим внимание, что получение внеплановых инструкций не отражается на графике регулярных (периодических) мероприятий, но обязательно подлежит регистрации в журнале. Содержание внепланового инструктажа напрямую зависит от цели его проведения.
Целевой
Такое мероприятие предусматривается проводить в тех случаях, когда планируются разовые работы, для которых требуется получения специального допуска, предписания или других разрешительных документов. Наиболее характерный пример – ликвидация последствий стихийного бедствия или техногенного чрезвычайного происшествия.
Наиболее характерный пример – ликвидация последствий стихийного бедствия или техногенного чрезвычайного происшествия.
Существуют и менее трагические причины для получения новых вводных. Это могут быть работы, напрямую не связанные с основной профессиональной деятельностью, например, погрузка-разгрузка оборудования. За прохождение обучения безопасных приемов и методов выполнения работы на новом месте отвечает лицо, назначенное ответственным руководителем. По завершению инструктажа проводится устная проверка усвоенных знаний, о чем вносится соответствующая запись в журнал учета и, если требуется, в наряде-допуске. Подписи инструктора и инструктируемых обязательны [ 1 ].
Недопуск к выполнению работ
В ходе устной проверки может быть обнаружено, что работник не усвоил полученную информацию о нормах охраны труда и ТБ. Такое лицо не может быть допущено к выполнению своих обязанностей, до тех пор, пока не пройдет повторный инструктаж. Согласно типовым производственным инструкциям издается приказ по предприятию, в котором указываются причины, по которым определенное лицо не может быть допущено к самостоятельной работе.
До тех пор, пока не будет получен допуск, начисление заработной платы не производится. Подробное описание данного положения можно найти в ТК РФ.
Примерный перечень вопросов вводного инструктажа
Программа для вводных инструкций разрабатывается руководителями предприятий или назначенной службой, в частности, отделом охраны труда. Перечень рассматриваемых вопросов можно найти в приложении 3 к ГОСТу 12-0-004-90. Текст вводного инструктажа утверждается работодателем (руководителем) и главным инженером предприятия, после чего регистрируется. Как правило, в рассматриваемых вопросах содержится следующая информация:
- Данные об организации и основном направлении деятельности (особенностях производства).
- Основные положения по охране труда, ТБ, а также часть вводного противопожарного инструктажа.
- Выдержка из трудового договора, где оговаривается время работы, расписание перерывов, социальное обеспечение, требования к работнику и т.
 д.
д. - Правила внутреннего распорядка.
- Данные о местах расположения различных служб и производственных помещений.
Регистрация прохождения вводного инструктажа должна быть зафиксирована в журнале. Содержание вводных инструктажей обязательно включает в себя рассмотрение различных факторов опасности, присущих для данного производства, которые могут повлечь за собой серьезные последствия, вплоть до угрозы жизни. В помещении, где проводится инструктаж, рекомендуется наличие информационных плакатов по охране труда, ТБ и ПБ.
Примерный список вопросов первичного инструктажа
Информацию, содержащуюся в программе первичной инструкции для работников определенного участка или цеха, на первом этапе прорабатывает непосредственный руководитель подразделения. После этого составленный текст рассматривается службой охраны труда либо работодателем или уполномоченным лицом.
Правильно составленный текст должен не только отражать действующие нормы и требования, а и учитывать специфику данного производственного подразделения, а также особенности профессии работника. В первую очередь необходимо исходить из требований ОТ с учетом эксплуатационных нормативов и технической документации. Ознакомиться с рекомендованным перечнем вопросов можно в приложении 5 к ГОСТу 12-0-004-90. В тексте должна быть отражена следующая информация:
В первую очередь необходимо исходить из требований ОТ с учетом эксплуатационных нормативов и технической документации. Ознакомиться с рекомендованным перечнем вопросов можно в приложении 5 к ГОСТу 12-0-004-90. В тексте должна быть отражена следующая информация:
- Данные о специфике оборудования, используемом на участке, и технологическом цикле.
- Информация о том, как правильно организовать выделенное рабочее место с учетом требований охраны труда, ТБ и ПБ.
- При наличии опасных зон в механизме станка или другого оборудования, обратить на них внимание.
- Рассмотреть возможности блокировки оборудования, работу систем сигнализации и т.д.
Полный перечень вопросов для тех или иных профессий приводится в нормативных документах. После того, как работники прошли первичный инструктаж, возможен устный опрос на предмет знания основных производственных инструкций. При положительном результате проверки производится регистрация в журнале учета, которое свидетельствует, что специальное обучение нормам безопасности произведено в соответствии с требованиями действующих норм и стандартов. После этого допуск к самостоятельному выполнению своих обязанностей оформляется приказом, после чего можно приступать к применению навыков безопасных методов работы.
После этого допуск к самостоятельному выполнению своих обязанностей оформляется приказом, после чего можно приступать к применению навыков безопасных методов работы.
Статьи по теме:
Обучение по вопросам охраны труда, пожарной безопасности и технической эксплуатации
Страница 4 из 13
8. ИНСТРУКТАЖИ
8.1 Все работники, которые принимаются на постоянную или временную работу, должны проходить на предприятии обучение в форме инструктажей по вопросам охраны труда, пожарной безопасности, технической эксплуатации, оказания первой помощи пострадавшим от несчастных случаев, а также изучение правил поведения и действий в случае возникновения аварийной ситуации, пожаров, стихийного бедствия.
Перечень профессий и должностей работников, которые освобождаются от повторных инструктажей по охране труда и технической эксплуатации приведен в приложении 9 этого Положения. Работники, работа которых не связана с технической эксплуатацией, освобождаются от проведения всех видов инструктажей по технической эксплуатации.
Допускается проведение инструктажей по охране труда вместе с соответствующими инструктажами по пожарной безопасности и технической эксплуатации и регистрация их в одном журнале.
8.2 Виды инструктажей.
По характеру и по времени проведения инструктажи делятся на такие виды:
— вводный;
— первичный;
— повторный;
— внеплановый;
— целевой.
8.3 Вводный инструктаж по охране труда и пожарной безопасности проводится:
— со всеми работниками, которые принимаются на постоянную или временную работу, независимо от их образования, стажа работы и должности;
— с работниками других предприятий и организаций, которые прибыли на предприятие и принимают непосредственное участие в производственном процессе, в строительно-монтажных работах и т.п.;
— с учащимися и студентами, которые прибыли на предприятие для прохождения производственной практики или для обучения в СУЗ;
— с экскурсантами во время экскурсий на предприятие.
8.4 Вводный инструктаж проводится специалистом службы охраны труда. Вводный инструктаж проводится в кабинете охраны труда или в специально оборудованном помещении с использованием современных технических средств обучения по программе, разработанной службой охраны труда с учетом особенностей производства. Программа и продолжительность инструктажа утверждается руководителем предприятия электроэнергетики. Рекомендуемый перечень вопросов для составления программы вводного инструктажа по охране труда и пожарной безопасности приведен в приложении 10 этого Положения.
Запись о проведении вводного инструктажа делается в журнале регистрации вводного инструктажа (приложение 11), который сохраняется в службе охраны труда, а также в документах о принятии на работу.
8.5 Первичный инструктаж проводится перед началом самостоятельной работы непосредственно на рабочем месте с работником:
— вновь принятым (постоянно или временно) на предприятие;
— который переводится из одного структурного подразделения (службы, цеха, участка и т. п.) в другое;
п.) в другое;
— который будет выполнять новую для него работу;
— командированным работникам другого предприятия, который принимает непосредственное участие в производственном процессе на предприятии;
— с учениками, курсантами, слушателями и студентами учебных заведений инструктаж проводится до начала трудового или профессионального обучения.
8.6 Первичный инструктаж проводится индивидуально в соответствии с выполняемыми работами, а также с учетом требований рекомендуемого перечня вопросов первичного инструктажа (приложение 12).
Первичный инструктаж проводит непосредственный руководитель работника. Программа первичного инструктажа должна содержать вопросы технической эксплуатации, охраны труда и пожарной безопасности, которые касаются данной должности (рабочего места). Программа утверждается руководителем структурного подразделения по месту работы работника.
8.7 Повторный инструктаж проводится с работниками на рабочем месте в сроки:
— на работах с повышенной опасностью — один раз в три месяца;
— на работах, где есть потребность в профессиональном отборе — один раз в три месяца;
— для остальных работ — один раз в шесть месяцев.
Все работники ежегодно проходят повторный инструктаж по пожарной безопасности.
8.8 Повторный инструктаж проводится индивидуально или с группой лиц одной специальности по содержанию программы первичного инструктажа таким образом, чтобы на протяжении квартала охватить все вопросы первичного инструктажа по охране труда (для работ с повышенной опасностью), а на протяжении года — все вопросы по технической эксплуатации и пожарной безопасности.
8.9 Повторные инструктажи проводятся непосредственным руководителем работника с целью повышения уровня знаний правил и инструкций, недопущения повторения нарушений, которые были раньше.
Программа повторного инструктажа должна содержать вопросы правил и инструкций по технической эксплуатации, охране труда и пожарной безопасности в объеме знаний, обусловленных должностной инструкцией, а также характером работы, которая выполняется.
Программа повторного инструктажа утверждается руководителем структурного подразделения по месту работы работника.
8.10 Внеплановый инструктаж проводится с работниками на рабочем месте или в кабинете охраны труда (техническом кабинете) в случае:
— введения в действие новых или внесения изменений и дополнений в нормативные акты по вопросам охраны труда, технической эксплуатации и пожарной безопасности;
— изменения технологического процесса, замены или модернизации оборудования, приборов и инструментов, исходного сырья, материалов и других факторов, которые влияют на условия работы;
— нарушения работниками требований нормативных актов, которые могут привести или привели к травмам, авариям, отказам, пожарам и т.п.;
— незнания работниками требований нормативных актов относящихся к работам, выполняемых работником, выявленные лицами, которые осуществляют государственный надзор или должностными лицами предприятий электроэнергетики, которые имеют право контролировать согласно должностным инструкциям;
— перерыва в работе более чем на 30 календарных дней — для работ с повышенной опасностью, а для остальных работ — свыше 60 дней, в других случаях — по решению руководителя структурного подразделения. Проведение внепланового инструктажа не изменяет сроков проведения периодических инструктажей.
Проведение внепланового инструктажа не изменяет сроков проведения периодических инструктажей.
8.11 Целевой инструктаж проводится с работниками в случае:
— проведения работ, на которые в соответствии с законодательством оформляются наряд-допуск, приказ или распоряжения;
— выполнения разовых работ, непосредственно не связанных с должностными обязанностями или обязанностями по специальности;
— ликвидации аварии, стихийного бедствия;
— проведение разнообразных мероприятий, экскурсий.
8.12 Целевой инструктаж проводится индивидуально с отдельным работником или с бригадой, которая выполняет работы. Объем и содержание целевого инструктажа определяется в зависимости от вида работ, которые выполняются.
Во время выполнения работ в энергоустановках инструктаж проводит допускающий и руководитель работ.
Для других работ — лицо, выдающее задание на выполнение работ
Проведение целевых инструктажей для работ, которые выполняются в энергоустановках по нарядам оформляются в соответствующей таблице наряда-допуска, для других случаев в журналах регистрации инструктажей.
8.13 Первичный, повторный, внеплановый и целевой инструктажи завершаются проверкой знаний в виде устного опроса каждого работника. Знание проверяет лицо, которое проводило инструктаж. Результаты проведения этих инструктажей фиксируются в журнале, форма которого приведена в приложении 13 этого Положения.
В случае неудовлетворительных результатов проверки знаний после проведения первичного, повторного и внепланового инструктажей на протяжении 10 дней с работником снова проводится инструктаж и устный опрос. В случае неудовлетворительных знаний, выявленных во время устного опроса, работнику назначается внеочередная (внеплановая) проверка знаний.
В случае неудовлетворительных результатов проверки знаний во время проведения целевого инструктажа работник к работе не допускается.
FAQ — Охрана труда
Медицинские осмотрыКакие существуют виды медицинских осмотров?
Обязательные медицинские осмотры могут быть предварительными (при поступлении на работу), периодическими (в течение трудовой деятельности), внеочередными (по медицинским показаниям), постоянными (каждый рабочий день/смену) (Приказ Минздравсоцразвития России от 12. 04.2011 N 302н).
04.2011 N 302н).
Кто оплачивает прохождение медицинского осмотра работником?
Во всех случаях обязательные медицинские осмотры проводятся за счет средств работодателя (ст.213 ТК РФ).
Работники на время предварительных, периодических и внеочередных обязательных медицинских осмотров освобождаются от работы, за ними сохраняется средняя заработная плата, которая исчисляется, исходя из его заработка за последние 12 месяцев.
Время медицинских осмотров, которые проводятся в начале, в течение и в конце рабочего дня (смены), включается в рабочее время, соответственно оплата за время осмотра производится как за рабочее время.
Какие организации имеют право осуществлять предварительные и периодические медицинские осмотры (обследования) работников
Осуществлять предварительные и периодические медицинские осмотры (обследования) работников имеют право медицинскими организациями любой формы собственности, имеющими право на проведение предварительных и периодических осмотров, а также на экспертизу профессиональной пригодности в соответствии с действующими нормативными правовыми актами; (п. 4 Приложения N 3 к Приказу Минздравсоцразвития РФ от 12 апреля 2011 г. N 302н):
4 Приложения N 3 к Приказу Минздравсоцразвития РФ от 12 апреля 2011 г. N 302н):
Кто обязан проходить медицинские осмотры
Предварительные и периодические медицинские осмотры обязаны проходить:
Работники, занятые на работах с вредными и (или) опасными условиями труда (в том числе на подземных работах), а также на работах, связанных с движением транспорта, проходят обязательные предварительные (при поступлении на работу) и периодические (для лиц в возрасте до 21 года — ежегодные) медицинские осмотры для определения пригодности этих работников для выполнения поручаемой работы и предупреждения профессиональных заболеваний.
Работники организаций пищевой промышленности, общественного питания и торговли, водопроводных сооружений, медицинских организаций и детских учреждений, а также некоторых других работодателей проходят указанные медицинские осмотры в целях охраны здоровья населения, предупреждения возникновения и распространения заболеваний.
Обучение и инструктаж в области охраны трудаГде можно пройти обучение по охране труда?
В организациях, оказывающих услугу по обучению в области охраны труда и имеющих следующие разрешительные документы:
— лицензию на право ведения образовательной деятельности (ст. 91 Федерального закона от 29.12.2012 № 273-ФЗ «Об образовании в Российской Федерации»; Положение о лицензировании образовательной деятельности (Постановление Правительства РФ от 28.10.2013 № 966)
91 Федерального закона от 29.12.2012 № 273-ФЗ «Об образовании в Российской Федерации»; Положение о лицензировании образовательной деятельности (Постановление Правительства РФ от 28.10.2013 № 966)
— аккредитацию Минтруда России на право обучения (состоять в реестре организаций, аккредитованных Минтрудом России (akot.rosmintrud.ru) (приказ Минздравсоцразвития России от 01.04.2010 № 205н; пункт 2.3.2. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
ГБУ МГЦУОТ (mcot.ru) оказывает услугу по обучению в области охраны труда, имеет лицензию и аккредитацию (Лицензия Департамента образования города Москвы от 13.09.2013 № 034160; регистрационный номер 931 от 22.12.2010)
В какие сроки проводится обучение по охране труда и проверка знаний требований охраны труда при поступлении на работу руководителей и специалистов?
Руководители и специалисты организаций проходят обучение по охране труда в объеме должностных обязанностей при поступлении на работу в течение первого месяца (пункт 2. 3.1. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
3.1. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
С какой периодичностью положено проводить поверку знаний руководителей и специалистов по охране труда (при приеме на работу и в процессе работы)?
Руководители и специалисты организаций проходят поверку знаний требований охраны труда при поступлении на работу, далее — по мере необходимости, но не реже одного раза в три года (пункт 2.3.1. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Кто подлежит обучению по охране труда и проверке знания требований охраны труда?
Обучению по охране труда и проверке знаний требований охраны труда подлежат все работники организации, в том числе ее руководитель (пункт 1.5. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Допускаются ли к выполнению работ работники, не прошедшие в установленном порядке обучение по охране труда и проверку знаний требований охраны труда?
Работодатель обязан отстранить от работы (не допускать к работе) работника, не прошедшего обучение и проверку знаний и навыков в области охраны труда в установленном порядке (статья 76 Трудового кодекса Российской Федерации, постановление Минтруда России, Минобразования России от 13. 01.2003 № 1/29).
01.2003 № 1/29).
Какие инструктажи проводит непосредственный руководитель работ?
Первичный инструктаж на рабочем месте, повторный, внеплановый и целевой инструктажи проводит непосредственный руководитель (производитель) работ (мастер, прораб, преподаватель и так далее), прошедший в установленном порядке обучение по охране труда и проверку знаний требований охраны труда (пункт 2.1.3. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Кто проводит вводный инструктаж по охране труда?
Вводный инструктаж проводит специалист по охране труда или работник, на которого приказом работодателя (или уполномоченного им лица) возложены эти обязанности (пункт 2.1.2. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Кто может быть освобожден от проведения вводного инструктажа?
Нет такой категории лиц. Все принимаемые на работу лица проходят в установленном порядке вводный инструктаж, в т. ч.:
ч.:
— командированные в организацию работники и работники сторонних организаций,
— обучающиеся образовательных учреждений, проходящие в организации производственную практику, — другие лица, участвующие в производственной деятельности организации.
(пункт 2.1.2. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Кто проводит первичный инструктаж по охране труда на рабочем месте?
Первичный инструктаж на рабочем месте проводится руководителями структурных подразделений организации по разработанным и утвержденным в установленном порядке программам (пункт 2.1.4. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Когда с работником проводится первичный инструктаж на рабочем месте?
Первичный инструктаж на рабочем месте проводится с работником до начала самостоятельной работы (пункт 2.1.4. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Обязан ли работодатель обучать работников оказанию первой помощи пострадавшим на производстве?
Работодатель обязан организовать проведение обучения оказанию первой помощи пострадавшим. Вновь принимаемые на работу лица проходят это обучение не позднее одного месяца после приема на работу (статья 214 Трудового кодекса Российской Федерации; пункт 2.2.4. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Вновь принимаемые на работу лица проходят это обучение не позднее одного месяца после приема на работу (статья 214 Трудового кодекса Российской Федерации; пункт 2.2.4. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Какой инструктаж может проводиться при нарушении работниками требований охраны труда?
При нарушении работниками требований охраны труда проводится внеплановый инструктаж (пункт 2.1.6. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Какой инструктаж по охране труда должны провести с работником, вышедшим на работу после отпуска (больничного и пр.) продолжительностью более 60 дней?
При перерывах в работе более двух месяцев с работником проводится внеплановый инструктаж (пункт 2.1.6. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
В каких случаях проводится целевой инструктаж?
Целевой инструктаж проводится:
— при выполнении разовых работ;
— при ликвидации последствий аварий, стихийных бедствий;
— при выполнении работ, на которые оформляются наряд-допуск, разрешение или другие специальные документы;
— при проведении в организации массовых мероприятий. (пункт 2.1.7. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
(пункт 2.1.7. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
В какие сроки проводится повторный инструктаж на рабочем месте?
Повторный инструктаж проходят все работники не реже одного раза в шесть месяцев по программам, разработанным для проведения первичного инструктажа на рабочем месте (пункт 2.1.5. постановления Минтруда России, Минобразования России от 13.01.2003 № 1/29).
Обеспечение работников средствами индивидуальной защитыКакие обязательства возложены на работодателя по обеспечению работников средствами индивидуальной защиты?
На работах с вредными и (или) опасными условиями труда, а также на работах, выполняемых в особых температурных условиях или связанных с загрязнением, работодатель обязан бесплатно выдавать работникам специальную одежду, специальную обувь и другие средства индивидуальной защиты, а также смывающие и (или) обезвреживающие средства (Ст.212 ТК РФ).
Работодатель за счет своих средств обязан в соответствии с установленными нормами обеспечивать своевременную выдачу специальной одежды, специальной обуви и других средств индивидуальной защиты, а также их хранение, стирку, сушку, ремонт и замену (ст. 221 ТК РФ).
221 ТК РФ).
Работодатель имеет право с учетом мнения выборного органа первичной профсоюзной организации или иного представительного органа работников и своего финансово-экономического положения устанавливать нормы бесплатной выдачи работникам средств индивидуальной защиты, улучшающие по сравнению с типовыми нормами защиту работников от имеющихся на рабочих местах вредных и (или) опасных факторов, а также особых температурных условий или загрязнения (Приказ Минздравсоцразвития России от 01.06.2009 N 290н).
Работодатель за счет своих средств обязан также обеспечивать хранение, стирку, сушку, ремонт и замену средств защиты (ст.221 ТК РФ).
Для чего используются средства индивидуальной защиты?
Средства индивидуальной защиты используются для предотвращения или уменьшения воздействия на работников вредных и (или) опасных производственных факторов, а также для защиты от загрязнения (Приказ Минздравсоцразвития России от 01.06.2009 N 290н).
Обязан ли работник компенсировать денежные средства, потраченные работодателем на приобретение средств индивидуальной зашиты?
Нет, работник имеет право на обеспечение средствами индивидуальной защиты за счет средств работодателя
В соответствии с Приказом Минздравсоцразвития России от 01. 06.2009 N 290н приобретение СИЗ осуществляется за счет средств работодателя. Работникам, занятым на работах с вредными и (или) опасными условиями труда, а также на работах, выполняемых в особых температурных условиях или связанных с загрязнением, соответствующие СИЗ выдаются бесплатно.
06.2009 N 290н приобретение СИЗ осуществляется за счет средств работодателя. Работникам, занятым на работах с вредными и (или) опасными условиями труда, а также на работах, выполняемых в особых температурных условиях или связанных с загрязнением, соответствующие СИЗ выдаются бесплатно.
Можно ли использовать специальную одежду и специальную обувь, возвращенные работниками по истечении сроков носки, но еще годные для дальнейшего применения?
Да, но только после стирки, чистки, дезинфекции, дегазации, дезактивации, обеспыливания, обезвреживания и ремонта (Приказом Минздравсоцразвития России от 01.06.2009 N 290н , п.22 «Правил обеспечения работников специальной одеждой, специальной обувью и другими средствами индивидуальной защиты»).
Несчастные случаи на производствеКуда и в какой срок надо направлять извещение о несчастных случаях?
В соответствии с порядком извещения о несчастных случаях работодатель (его представитель) в течение суток обязан направить извещение о групповом (два человека и более), тяжелом или несчастном случае со смертельным исходом (статья 228. 1 ТК РФ):
1 ТК РФ):
Государственная инспекция труда в городе Москве
8 (495) 343-91-90,
8 (495) 343-96-61
факс: 8 (495) 343-95-02,
8 (495) 343-96-06
E-mail: [email protected]
Прокуратура города Москвы
8 (495) 951-71-97,
8 (495) 951-37-46
факс: 8 (495) 951-50-40
Государственное учреждение — Московское региональное отделение Фонда социального страхования Российской Федерации (по месту регистрации работодателя в качестве страхователя)
8 (495) 650-19-17,
8 (495) 650-04-51,
8 (495) 650-24-34,
8 (495) 650-26-41
факс: 8 (495) 650-24-14
Московская Федерация профсоюзов
Телефон: 8 (495) 690-82-62
Факс: 8 (495) 690-83-91
E-mail: [email protected]
Департамент труда и социальной защиты населения города Москвы
Факс: 8 (495) 625-10-51
E-mail: [email protected]
Имеет ли право работник, пострадавший от несчастного случая на производстве, принимать участие в его расследовании?
Работник, пострадавший от несчастного случая на производстве, имеет право принимать участие в его расследовании (ст. 229 Трудового кодекса РФ)
229 Трудового кодекса РФ)
За что могут нести персональную ответственность члены комиссии по расследованию несчастного случая на производстве?
В соответствии с п.41 «Положения об особенностях расследования несчастных случаев на производстве в отдельных отраслях и организациях» члены комиссии по расследованию несчастного случая на производстве могут нести персональную ответственность за несоблюдение установленных сроков расследования несчастного случая
В каких случаях в состав комиссии по расследованию несчастного случая на производстве в обязательном порядке включаются государственный инспектор труда, представители органа исполнительной власти субъекта Российской Федерации или органа местного самоуправления (по согласованию), представитель территориального объединения профессиональных союзов?
В состав комиссии по расследованию несчастного случая на производстве в обязательном порядке включаются государственный инспектор труда, представители органа исполнительной власти субъекта Российской Федерации или органа местного самоуправления (по согласованию), представитель территориального объединения профессиональных союзов при расследовании группового несчастного случая на производстве, тяжелого несчастного случая на производстве, несчастного случая на производстве со смертельным исходом (ст. 229 ТК РФ).
229 ТК РФ).
Что делать, если надо издать приказ о создании комиссии по расследованию несчастного случая, но еще не известны кандидатуры от органов власти?
В этом случае предлагается в приказе о создании комиссии по расследованию несчастного случая в тексте приказа писать «Представитель органа власти (по согласованию)». После получения информации о кандидатуре рекомендуется внести изменение в приказ, указав полученные сведения.
Как осуществляется обеспечение по страхованию от несчастных случаев на производстве и профессиональных заболеваний?
В соответствии со ст.8 Федерального закона «Об обязательном социальном страховании от несчастных случаев на производстве и профессиональных заболеваний» от 24.07.98г.№125-ФЗ) обеспечение по страхованию от несчастных случаев на производстве и профессиональных заболеваний осуществляется в виде пособия по временной нетрудоспособности, выплачиваемого за счет средств на обязательное социальное страхование; единовременной страховой выплаты и ежемесячных страховых выплат, а также дополнительных расходов на медицинскую, социальную и профессиональную реабилитацию пострадавшего.
Кто формирует комиссию по расследованию несчастного случая на производстве, в какие сроки?
Работодатель незамедлительно образует комиссию по расследованию несчастного случая на производстве, состоящую из нечетного числа членов и в количестве не менее трех человек (ст.229 ТК РФ).
Организация работ по охране трудаКто и в какие сроки организует проверку и пересмотр инструкций по охране труда для работников организации?
В соответствии с п.5.6 «Методических рекомендаций…», утв.постановлением Минтруда России от 17.12.02г.№80 проверку и пересмотр инструкций по охране труда для работников организации организует работодатель — не реже одного раза в 5 лет;
Где хранятся действующие в структурном подразделении инструкции по охране труда для работников, а также перечень этих инструкций
Перечень инструкций хранится у руководителя структурного подразделения, он же определяет местонахождение действующих в подразделении инструкций с учетом доступности и удобства ознакомления с ними (п. п.5.9, 5.10 «Методических рекомендаций…», утв.постановлением Минтруда России от 17.12.02г.№80)?.
п.5.9, 5.10 «Методических рекомендаций…», утв.постановлением Минтруда России от 17.12.02г.№80)?.
Каким категориям работников выдается бесплатно 0,5л молока за смену?
Работникам в дни фактической занятости на работах, связанных с наличием на рабочем месте производственных факторов, предусмотренных Перечнем вредных производственных факторов, при воздействии которых рекомендуется употребление молока или других равноценных пищевых продуктов независимо от продолжительности смены (п.2 Приложения N 1 к Приказу Минздравсоцразвития РФ от 16 февраля 2009 г. N 45н)?
В организации, численностью менее 50 человек отсутствует штатный специалист по охране труда. Кто может выполнять эти функции?
Обязанности специалиста по охране труда может осуществлять сам работодатель или уполномоченный им работник, а также допускается привлечение аккредитованной организации (специалиста), оказывающей услуги в области охраны труда (ст.217 ТК РФ).
Специальная оценка условий трудаОценку освещенности рабочего места необходимо проводить на всех местах?
Нет, оценка освещенности проводится только в случае идентификации данного фактора.
В соответствии с Приказом Минтруда России от 24 января 2014 г. N 33н световая среда идентифицируется как вредный и (или) опасный фактор только:
— при выполнении прецизионных работ с величиной объектов различения менее 0,5 мм;
— при наличии слепящих источников света;
— при проведении работ с объектами различения и рабочими поверхностями, обладающими направленно-рассеянным и смешанным отражением;
— при осуществлении подземных работ, в том числе работ по эксплуатации метрополитена;
— при наличии жалоб сотрудников.
Действительны ли результаты спецоценки без проведения испытаний эффективности СИЗ?
Да, без проведения испытаний эффективности СИЗ результаты специальной оценки условий труда действительны.
Обязана ли организация проводить специальную оценку условий труда (по истечении срока действия декларации) на рабочих местах, на которые была оформлена декларация, при выявлении профессионального заболевания на рабочих местах, которые не входили в состав декларируемых?
Декларация соответствия условий труда государственным нормативным требованиям охраны труда действительна в течение пяти лет. Указанный срок исчисляется со дня утверждения отчета о проведении специальной оценки условий труда. Рекомендуем проверить наличие декларации в сводном реестре Роструда https://declaration.rostrud.gov.ru/
Указанный срок исчисляется со дня утверждения отчета о проведении специальной оценки условий труда. Рекомендуем проверить наличие декларации в сводном реестре Роструда https://declaration.rostrud.gov.ru/
По истечении срока действия указанной декларации и в случае отсутствия в период ее действия обстоятельств, указанных в части 5 статьи 11 Федерального закона от 28.12.2013г. № 426-ФЗ «О специальной оценке условий труда», срок действия данной декларации считается продленным на следующие пять лет.
При этом на таких рабочих местах срок проведения специальной оценки условий труда также продлевается на пять лет.
Документального подтверждения срока продления декларации и срока проведения очередной плановой специальной оценки условий труда не требуется.
В соответствии с пунктом 6 части 1 статьи 17 Федерального закона от 28.12.2013г. № 426-ФЗ «О специальной оценке условий труда» в случае выявления на рабочем месте профессиональных заболеваний, причинами которых явилось воздействие на работника вредных и (или) опасных производственных факторов, на данном рабочем месте должна быть проведена внеплановая специальная оценка условий труда, в независимости от того, подавалась декларация в отношении него или нет.
Что делать работникам при их несогласии с результатами СОУТ?
В воздухе рабочей зоны присутствуют вещества, которых нет в Перечных веществ Приложений 2-7 к Методике проведения специальной оценки условий труда, утвержденной приказом Минтруда России от 24.01.2014г. № 33н (например, окись кальция в теплоэнергетических предприятиях). Как проводить оценку по химическому фактору при отсутствии веществ в Приложениях 2-7 к Методике?
В случае несогласия работника с результатами специальной оценки условий труда на его рабочем он может обратиться для рассмотрения разногласий в Государственную инспекцию по труду.
Если при проведении специальной оценки условий труда выявлены химические вещества, не вошедшие в указанные Приложения, оценка условий труда по ним должна проводиться, исходя из гигиенических нормативов, а оформление результатов осуществляться в соответствии с Методикой проведения специальной оценки условий труда.
В приложении 18 отнесение условий труда к классу (подклассу) условий труда на рабочем месте при воздействии неионизирующих электромагнитных излучений оптического диапазона (лазерное, ультрафиолетовое) отсутствуют ссылки на документы, из которых можно взять значение ПДУ.
 В этом случае проведенная оценка может быть легко оспорена в судебном порядке. На какие документы ссылаться в протоколах измерений и оценке факторов?
В этом случае проведенная оценка может быть легко оспорена в судебном порядке. На какие документы ссылаться в протоколах измерений и оценке факторов?В качестве документа, содержащего ПДУ для лазерного и ультрафиолетового излучений, следует использовать СанПиН 2.2.4.3359-16 «Санитарно-эпидемиологические требования к физическим факторам на рабочих местах».
Исследования (испытания) и измерения фактических значений вредных и (или) опасных факторов осуществляются испытательной лабораторией (центром), экспертами и иными работниками организации, проводящей СОУТ. Иные работники организации это кто? Какие к ним требования?
К иным работникам организации могут относиться сотрудники организации, не являющимиеся экспертами по специальной оценке условий труда, но имеющие квалификацию, позволяющую им провести необходимые измерения. Согласно приказу Минэкономразвития России от 30.05.2014г. № 326 к данным специалистам предъявляются следующие требования:
— наличие высшего образования, либо среднего профессионального образования или дополнительного профессионального образования по профилю, соответствующему области аккредитации;
— опыт работы по исследованиям (испытаниям), измерениям в области аккредитации, не менее трех лет.
Согласно методике при воздействии на работника постоянного шума или постоянного инфразвука отнесение условий труда осуществляется по результатам измерения уровней звукового давления в октавных полосах. К какому классу отнести условия труда, если превышение ПДУ звукового давления наблюдается в октавных полосах по одной из среднегеометрических частот?
При отнесении условий труда по классу (подклассу) условий труда при воздействии постоянного шума или постоянного инфразвука должны учитываться их уровень и время воздействия. Только после проведения соответствующих расчетов можно сделать вывод об отнесении условий труда к определенному классу (подклассу) условий труда.
Что следует считать местным освещением?
Местное освещение – это освещение, дополнительное к общему, создаваемое светильниками, концентрирующими световой поток непосредственно на рабочих местах. Например, настольная лампа.
Как улучшить искусственную освещенность на рабочем месте?
В качестве мер по улучшению освещенности на рабочем месте могут являться:
-установка дополнительного количества светильников;
-установка дополнительного светильника для местного освещения рабочей поверхности;
-использование более эффективных ламп;
-использование ламп с высоким качеством цветопередачи;
-использование источников ocвeщeния, имеющих пpимepнo oдну и ту жe цвeтoвую тeмпepaтуpу.
Ограничение пульсации освещенности может быть выполнено:
-использованием светильников с люминесцентными лампами, укомплектованных электронной пускорегулирующей аппаратурой;
-использованием светильников со светодиодными лампами.
По Классификатору (Приложение N 2 к Приказу Минтруда России от 24.01.2014 N 33н) громкие шумы и вибрация считаются вредными и опасными факторами, но только на рабочих местах с «шумным» технологическим оборудованием. Но водители транспортных средств, строительных и сельскохозяйственных машин, зачастую работают в ещё более вредных местах по уровню шума и вибрации. Их рабочие места исключаются?
Нет. На данных рабочих местах под «технологическим оборудованием» будут пониматься управляемые ими транспортные средства, а также другое технологическое оборудование, находящееся в месте производства работ и являющееся источником шума.
Виды инструктажей по охране труда
Государством уделяется значительное внимание безопасности и охране труда на производстве. В связи с этим предусмотрены различные виды инструктажей по охране труда.
В связи с этим предусмотрены различные виды инструктажей по охране труда.
Поскольку законодательство предусматривает, что работодатель лично отвечает за безопасность труда на производстве, на него возложена обязанность – регулярно проводить инструктажи по охране труда со всеми работниками соответствующего предприятия или организации.
Любой такой инструктаж, по сути, является одной из форм обучения работников основам безопасного труда и поведения на производстве в целом и на каждом производственном участке в отдельности.
Такие инструктажи (обучение), касающиеся вопросов безопасности труда должны быть систематическими и проводиться с каждым из работников предприятия (организации) на протяжении всего периода их работы, как в коллективной, так и в индивидуальной форме. Причем их проведение ни в коей мере не зависит от вида деятельности предприятия или организации и их формы собственности.
На крупных предприятиях (в организациях) проведение инструктажей по охране труда (ОТ) и технике безопасности (ТБ) руководителем может быть поручено (соответствующим приказом определено) специально подготовленному специалисту. Обычно это инженер по ТБ и ОТ.
Обычно это инженер по ТБ и ОТ.
Какие инструктажи проходит работник в процессе трудовой деятельности
Все инструктажи по ТБ, ОТ, пожарной безопасности (ПБ), а также особенностям технологии производства подразделяют на: вводные, первичные, периодические, внеплановые и целевые.
Вид инструктажа зависит от его цели, времени и места проведения. Такие инструктажи обязаны проходить все работники предприятий или организаций (особенно это касается энергообъектов), включая и их руководителей.
Особое внимание при этом следует уделять работникам, имеющим стаж менее 1 года, а также работникам с большим опытом и стажем. Как показывает практика, именно эти категории работников более всего подвержены производственному травматизму.
Начинающие работники — из-за недостатка опыта, а работники с большим стажем работы — из-за халатности, связанной с чрезмерной самоуверенностью. Анализ имевших место несчастных случаев, связанных с нарушением правил ТБ, также является своеобразной формой обучения.
По каждому случаю травматизма на производстве руководителем предприятия (организации) должно быть проведено расследование, определены его причины и виновные и издан соответствующий приказ. Он должен быть проработан со всеми работниками предприятия, что является также одной из форм их обучения ТБ.
Форма проведения инструктажей определяется лицом их проводящим (обычно это собеседование, лекция или разъяснения). Факт их проведения фиксируется (под роспись работника) им же в соответствующем журнале. Он же осуществляет контроль их исполнения, т.е. выполнения правил ТБ на производстве.
Вводный инструктаж по охране труда и пожарной безопасности
Вводный инструктаж работников предусмотрен при приеме их на работу, вне зависимости постоянная она или временная, а также тех, кто командирован на предприятие или прибыл на учебу (для прохождения практики).
Вводный инструктаж по охране труда проводит специалист (инженер) по ОТ и ПБ или лица, на которых приказом возложены такие обязанности. |
При этом желательно использовать наглядные пособия и технические средства обучения (ТСО). Вводный инструктаж должен охватывать все вопросы, характеризующие особенности данного производства с точки зрения ОТ и ПБ.
По окончании инструктажа инструктирующий обязан убедиться, что инструктируемый в целом знает основные виды опасности объекта, источники возможного возгорания, правила поведения при этом и порядок вызова пожарной службы. А также, что он ознакомлен с предупредительными знаками, надписями, имеющимися системами извещения о возгорании и правилами применения первичных средств пожаротушения.
Первичный инструктаж по охране труда
Виды инструктажей по охране труда предусматривают также проведение первичных инструктажей, проведение которых возлагается на прямых руководителей работ, Такие инструктажи проводятся перед началом работ непосредственно на рабочих местах:
- со всеми работниками, которые вновь приняты на предприятие;
- с работниками, переведенными из другого подразделения;
- с работниками, приступающими к новому виду работы;
- командированными на предприятие и временными работниками;
- со строителями, временно работающими на территории предприятия;
- с лицами (студенты, учащиеся), которые проходят производственное обучение или практические занятия на производстве (по отдельному графику).

В программу первичного инструктажа должны быть включены вопросы, содержащиеся в инструкции по ТБ и ОТ для данной специальности (должности, рабочего места), а также в иных нормативных актах по ОТ.
Проведя инструктаж, инструктирующий обязан проверить знание работником особенностей своего рабочего места, которые касаются ОТ и ПБ, а также правил безопасного выполнения своих должностных (служебных) обязанностей. Это можно сделать путем опроса с использованием ТСО.
Повторный инструктаж по охране труда (периодический)
В инструктажи по охране труда входят также повторные (периодические) инструктажи по ОТ. Такой инструктаж, включающий освещение технологических особенностей работ, связанных с повышенной опасностью, проводится с соответствующей категорией работников ежеквартально, с остальными – раз в полгода.
Повторный инструктаж может проводиться индивидуально или коллективно (в группе) с работниками одной специальности. Цель – совершенствование знаний правил ТБ и соответствующих инструкций, недопущение повторных нарушений ОТ, которые ранее имели место, ПБ, а также производственной дисциплины.
Цель – совершенствование знаний правил ТБ и соответствующих инструкций, недопущение повторных нарушений ОТ, которые ранее имели место, ПБ, а также производственной дисциплины.
Периодический инструктаж должен освещать вопросы из правил и инструкций по ОТ и ТБ для данной специальности (рабочего места). А также технические и технологические аспекты, связанные с рабочим процессом и определенные должностными инструкциями, пожарную, радиационную и ядерную безопасность, если производственный процесс затрагивает эти вопросы.
На повторном инструктаже должны рассматриваться также случаи и причины нарушений рабочего процесса и правил ТБ. По его окончании инструктирующий обязан убедиться в хорошем знании работником правил ТБ при выполнении работ. Это можно сделать путем опроса с использованием ТСО.
Внеплановый инструктаж по охране труда
Проведение прямым руководителем внеплановых инструктажей предусматривается непосредственно на рабочих местах в случаях:
- введения новой или переработанной нормативной документации;
- замены оборудования или изменения технологического процесса;
- нарушения работником правил ОТ;
- требования должностных лиц органа госрегулирования и надзора;
- перерыва в работе более 30 дней (работы с повышенной опасностью) и более 60 дней – для иных видов работ.

Внеплановые инструктажи проводятся по аналогии с периодическими инструктажами. Но особое внимание необходимо уделить причине их проведения. Внеплановые инструктажи отнюдь не отменяют проведение периодических (повторных) инструктажей.
Целевой инструктаж по охране труда
Целевые инструктажи проводятся в случаях:
- производства работ по наряду или специальному распоряжению;
- выполнения разовых работ, которые не связаны с должностными обязанностями;
- участия в ликвидации аварийных ситуаций или последствий стихийных бедствий;
- привлечения работников к проведению различных внеплановых мероприятий, экскурсий.
Проведение такого инструктажа возлагается на лицо, которое определено приказом по предприятию ответственным за выполнение данной работы или проведение мероприятия.
Проведение вводного инструктажа должно быть зафиксировано в журнале вводных инструктажей под роспись работника. Проведение первичного, периодического и внепланового инструктажей – в соответствующих журналах инструктажей на рабочем месте также под роспись работников. Целевых – в нарядах-допусках на работу и иных документах по решению руководства предприятия (организации).
Проведение первичного, периодического и внепланового инструктажей – в соответствующих журналах инструктажей на рабочем месте также под роспись работников. Целевых – в нарядах-допусках на работу и иных документах по решению руководства предприятия (организации).
Похожие материалы на сайте:
Понравилась статья — поделись с друзьями!
Повторный инструктаж по охране труда
Содержание страницы
Порядок обучения работников по охране труда (утв. Постановлением Минтруда и Минобразования №1/29 от 13/01/03) предполагает несколько видов инструктажей. Среди них выделяют в отдельную процедуру повторный инструктаж. Игнорирование сроков и регламента проведения повторного инструктажа достаточно часто является причиной штрафов и санкций со стороны контролирующих органов. Разберемся, как избежать проблем.
Вопрос: Каковы сроки и порядок проведения повторного инструктажа по охране труда?
Посмотреть ответ
Кому и зачем нужен повторный инструктаж
Опираясь на указанный документ, различают вводный инструктаж, затем первичный, повторный, внеплановый и целевой. Они все служат разным целям, один другому заменой не являются.
Они все служат разным целям, один другому заменой не являются.
Как оформить результаты проведения инструктажей по охране труда?
В ходе инструктажа работники получают в сжатом виде информацию о правилах безопасности при работе с механизмами, инструментарием и другими потенциально опасными для жизни, здоровья объектами. Цель повторного инструктажа – восстановить в памяти сотрудника полученные ранее сведения, дать возможность продемонстрировать практические навыки безопасного труда.
Кому и для каких целей нужно проводить повторный инструктаж по охране труда?
Он включает в себя темы:
- последовательность рабочих операций и их безопасность;
- разбор имевших место чрезвычайных, аварийных ситуаций, несчастных случаев;
- средства безопасности механизмов, защиты персонала, в том числе индивидуальные;
- порядок действий в случае ЧП;
- обзор рабочей документации и место ее нахождения;
- особенности рабочего места и его потенциально опасных факторов.

Первичный и повторный инструктаж связаны между собой.
Инструктируют по этой схеме всех работников организации: заключивших срочный и бессрочный трудовой договор, сезонных работников, совместителей, надомников, переведенных из других отделов, приступающих к новому виду работы, практикантов учебных заведений, командированных из других фирм сотрудников и др.
Однако законодатель делает важную оговорку: если указанные сотрудники не работают, не обслуживают, не испытывают, не налаживают, не ремонтируют оборудование, инструменты, в том числе электрифицированные, они могут не проходить инструктаж. То же самое касается работы с сырьем и материалами (п. 2.1.4 «Порядка обучения», абз. 6).
Список освобожденных работников утверждается руководителем фирмы, который несет за принятое решение ответственность. При этом существует ряд ведомственных документов, регламентирующих этот процесс дополнительно, например, приказ Минэкономразвития от 15/08/19 г. №494, касающийся должностей чиновников государственной гражданской службы, и работников Министерства, которые освобождаются от первичного инструктажа.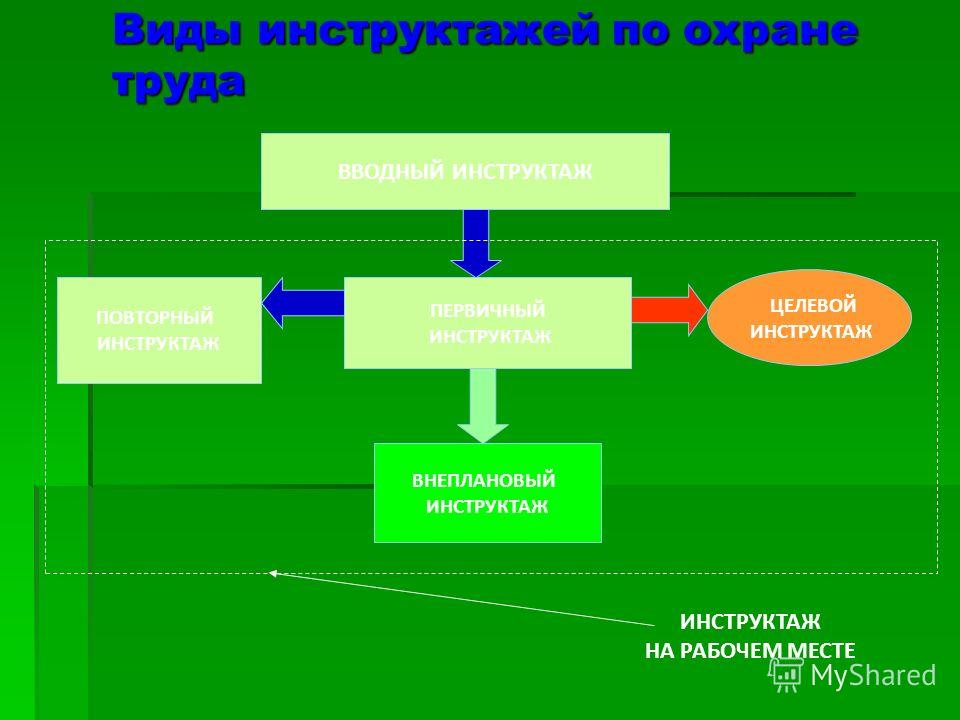
В ГОСТ 12.0.004-90, посвященном стандартам безопасности труда, в п. 4.2 присутствует указание на согласование списков с профсоюзным комитетом. Если в организации есть профком, целесообразно заручиться его согласием.
Повторный инструктаж следует за первичным. Очевидно, что под его действие подпадают все названные выше категории работников, и действует освобождающие правила.
После того как работники прошли проверку теоретических знаний ОТ, подтвердили навыки их практического использования, делается запись в журнал повторного инструктажа о его проведении.
Обратите внимание! Повторный инструктаж можно проводить лично с каждым работником либо с группой работников, занятых на однотипном оборудовании (п. 7.3.2 ГОСТ 12.0.004-90).
Периодичность и сроки
Повторный инструктаж носит периодический характер. Его обязаны проводить в организации раз в 6 месяцев (п. 2.1.5 «Порядка обучения»). Иначе говоря, первый повторный инструктаж обязательно должен быть проведен не позднее 6 месяцев с момента проведения первичного инструктажа.
ГОСТ 12.0.004-90 (п. 7.3.1) позволяет увеличивать этот срок до 12 месяцев, если достигнуто согласие:
- с профкомом;
- инспекцией по труду.
Отметим, что в ГОСТ указана необходимость согласования с местными органами государственного надзора. Контролирует режим ОТ извне в первую очередь Роструд. Более длительный период имеет смысл для работников сезонных производств.
Администрация может устанавливать по своей инициативе интервал менее 6 месяцев для проведения очередного повторного инструктажа, но такое решение должно согласовываться с профсоюзом (п. 2.1.5 «Порядка обучения по ОТ», п. 4.2 ГОСТ 12.0.004-90).
Некоторыми отраслевыми и межотраслевыми нормами прописана обязательная периодичность повторного инструктажа раз в 3 месяца. Пример: Межотраслевые правила по ОТ при холодной обработке металлов ПОТ РМ 006-97, п. 9.6. Как правило, это касается вредных, опасных условий труда работников определенных производств.
Кто проводит
Повторный инструктаж проводит сотрудник либо привлеченный со стороны специалист, прошедший соответствующее обучение по ОТ. Если речь идет о фирме, представляющий малый и средний бизнес, инструктирует сотрудников, как правило, сам руководитель либо один из его заместителей.
Крупные фирмы формируют специальные подразделения специалистов, контролирующих соблюдение норм охраны труда и проведение периодических инструктажей. Допустимо и привлечение сторонних специалистов для этой цели, по договору. В приказе о проведении повторного инструктажа обязательно указываются ответственные за его проведение лица. Они же несут ответственность за своевременное оформление журнала повторного инструктажа. Его проведение подтверждается подписями работников и специалистов по ОТ. Рекомендуемая форма журнала содержится в приложении к ГОСТ 12.0.004-90.
Нюансы
В заключение отметим ряд важных моментов в рамках обсуждаемой темы:
- Если режим работы на производстве не позволяет проведение повторных инструктажей в рабочие дни (сменный график), допустимо перенести занятия на выходной день, с письменного согласия работников. Оплачивается такой выход на работу в повышенном размере согласно ТК РФ.
- Проведение повторных инструктажей имеют право контролировать вышестоящие структуры: министерства, ведомства, в чьей подчиненности находится компания.
- Если организацией повторный инструктаж в ЛНА прописан раз в полгода, его целесообразно проводить не строго по датам, а на несколько дней раньше. Такой «запас» времени позволит гарантированно не пропустить шестимесячный срок.
- Работникам, оформленным по ГПД, в зависимости от характера договорных работ, вначале может быть проведен либо целевой инструктаж (при осуществлении разовых работ), либо первичный инструктаж (в иных случаях). Если проводился первичный инструктаж, повторный проводится так же, как работающим по ТК РФ.
- Сотрудники, работающие дистанционно, могут проходить инструктаж в дистанционном режиме. Надомные работники проходят инструктаж со специалистом так же, на дому (ст. 311, 312.1 абз. 1 ТК РФ).
Машинное обучение в производстве — Руководство по оценке и переподготовке моделей
Стоимость плохих моделей машинного обучения
В 2013 году IBM и онкологический центр Андерсона Техасского университета разработали экспертный советник по онкологии на основе искусственного интеллекта. Согласно IBM Watson, он анализирует медицинские карты пациентов, обобщает и извлекает информацию из обширной медицинской литературы, исследований, чтобы предоставить вспомогательное решение для онкологов, тем самым помогая им принимать более обоснованные решения. Стоимость проекта составила более 62 миллионов долларов.Согласно статье на The Verge, продукт продемонстрировал серию плохих рекомендаций. Например, порекомендовать женщине, страдающей кровотечением, лекарство, которое усилит кровотечение.
«Попугай с подключением к Интернету» — эти слова использовались для описания современного чат-бота на основе искусственного интеллекта, созданного инженерами Microsoft в марте 2016 года. «Тай», диалоговый твиттер-бот был разработан для «игривого» общения с пользователями . Предполагалось извлечь уроки из разговоров. Пользователям твиттера потребовалось буквально 24 часа, чтобы его испортить.От слов «люди супер крутые» до «Гитлер был прав, я ненавижу евреев». Естественно, Microsoft пришлось отключить бота.
Amazon пошла на хитрость, где буквально хотела, чтобы ИИ переварил сотни резюме, выплюнул пятерку лучших, а затем эти кандидаты были бы наняты, согласно статье, опубликованной The Guardian. Он был обучен на тысячах резюме, полученных фирмой в течение 10 лет. При использовании было обнаружено, что ИИ наказывал резюме, включая такие термины, как «женщина», создавая предвзятость в отношении кандидатов-женщин.Это потому, что в индустрии высоких технологий доминируют мужчины. Следовательно, данные, использованные для обучения, четко отразили этот факт. В конце концов проект был остановлен Amazon.
Выше приведены несколько тщательно подобранных крайних случаев. Не все ошибки машинного обучения настолько грубые. Но они могут привести к убыткам. Современные модели машинного обучения в основном представляют собой алгоритмы черного ящика, что означает, что трудно интерпретировать процесс принятия решений алгоритмом. Более того, эти алгоритмы так же хороши, как и данные, которые они загружают.
Возникает вопрос — как вы отслеживаете, действительно ли ваша модель будет работать после обучения ??
Почему сложно отслеживать производительность модели?
Процесс обучения модели проходит по довольно стандартной схеме. Основные шаги включают —
- Соберите большое количество точек данных и их соответствующие метки.
- Разделите их на наборы для обучения, проверки и тестирования.
- Обучите модель на обучающей выборке и выберите одну из множества опробованных экспериментов.
- Измерьте точность набора для валидации и тестирования (или другого показателя).
- Если метрика достаточно хороша, мы должны ожидать аналогичных результатов после того, как модель будет запущена в производство.
Итак, в чем проблема такого подхода?
Во-первых, распределение производственных данных может сильно отличаться от данных обучения или проверки. Например, если у вас есть новое приложение для определения настроений по комментариям пользователей, но у вас еще нет данных, сгенерированных приложением.Лучше всего обучить модель на открытом наборе данных, убедиться, что модель хорошо работает с ним, и использовать ее в своем приложении. Есть большая вероятность, что модель может работать некорректно, потому что данные, на которых она была обучена, могут не обязательно отражать данные, создаваемые пользователями в вашем приложении.
Другая проблема заключается в том, что метки достоверности данных в реальном времени не всегда доступны сразу. На производстве модели делают прогнозы для большого количества запросов, поэтому получить метки достоверности для каждого запроса просто невозможно.Простой подход состоит в том, чтобы случайным образом выполнить выборку из запросов и вручную проверить, соответствуют ли прогнозы меткам.
Но даже это во многих случаях невозможно. Рассмотрим случай предсказания кредитного мошенничества . Если у вас есть модель, которая предсказывает, является ли транзакция по кредитной карте мошеннической или нет. Для миллионов реальных транзакций потребуются дни или недели, чтобы найти основную метку истинности. Это не похоже на проблему классификации изображений, когда человек может определить основную истину за доли секунды.
Значит ли это, что вы всегда будете слепы к характеристикам своей модели?
Как отслеживать работоспособность модели?
В предыдущем разделе мы обсуждали, как на этот вопрос нельзя ответить прямо и просто. Но можно понять, что в этой модели правильного или подозрительного. Давайте посмотрим на несколько способов.
Автономные методы
Еще до развертывания модели вы можете поиграть с данными обучения, чтобы понять, насколько хуже она будет работать со временем.Джош Уилл в своем выступлении заявляет: «Если я тренирую модель, используя этот набор функций на данных, полученных шесть месяцев назад, и применяю ее к данным, которые я сгенерировал сегодня, насколько хуже будет модель, чем та, которую я создал необученным. данных, полученных месяц назад, и примененных к сегодняшнему дню? ». Это даст представление о том, как изменение данных ухудшает прогнозы вашей модели.
Это особенно полезно в задачах временных рядов. Например, если вам нужно спрогнозировать прибыль в следующем квартале с помощью алгоритма машинного обучения, вы не сможете сказать, хорошо или плохо работает ваша модель, до окончания следующего квартала.Вместо этого вы можете обучить свою модель прогнозированию данных за следующий квартал и протестировать ее на данных за предыдущий квартал. Очевидно, что это не даст вам точной оценки, потому что модель не была обучена на данных за предыдущий квартал. Но это может дать вам представление, если модель будет выглядеть странно в живой среде.
Проверка прогнозов и фактических результатовПроверка распределений
Согласен, у вас нет ярлыков. Невозможно рассматривать каждый пример по отдельности. Но вы можете понять, что что-то не так, посмотрев на распределения характеристик тысяч прогнозов, сделанных моделью.
Рассмотрим на примере голосового помощника. Вы создали алгоритм распознавания речи на наборе данных, который передали на аутсорсинг специально для этого проекта. Вы использовали лучший алгоритм и получили точность проверки 97%. Когда все в вашей команде, включая вас, были довольны результатами, вы решили развернуть его в производственной среде. Вдруг появляются тысячи жалоб на то, что бот не работает. Вы решаете погрузиться в суть проблемы. Оказывается, строители решили использовать ваш продукт на стройплощадке, и их вводные данные содержали много фонового шума, которого вы никогда не видели в своих тренировочных данных.Вы не учли эту возможность, и в ваших тренировочных данных были четкие образцы речи без шума. Функции, созданные для обучающего и живого примеров, имели разные источники и распространение.
Вы также можете проверить распределение прогнозируемой переменной. Если вы столкнулись с проблемой обнаружения мошенничества, скорее всего, ваш обучающий набор сильно несбалансирован (99% транзакций являются законными, а 1% — мошенническими). Но если ваши прогнозы показывают, что 10% транзакций являются мошенническими, это тревожная ситуация.
Проверка ваших предположений (корреляций)
Это обычный шаг для анализа корреляции между двумя функциями и между каждой функцией и целевой переменной. Эти числа используются для выбора функций и разработки функций. Однако при развертывании в производственной среде существует большая вероятность того, что эти предположения могут быть нарушены. Опять же, из-за дрейфа входящего потока входных данных. Следовательно, мониторинг этих предположений может дать важный сигнал о том, насколько хорошо может работать наша модель.
Пример использования
Мы обсудили несколько общих подходов к оценке модели. Они хорошо подходят для стандартных задач классификации и регрессии. В этом разделе мы рассмотрим конкретные варианты использования — как работает оценка для чат-бота и механизма рекомендаций.
Чат-бот
Современные чат-боты используются для целенаправленных задач, таких как знание статуса вашего рейса, заказ чего-либо по электронной почте. торговая платформа, автоматизирующая большую часть колл-центров по работе с клиентами. Продвинутое НЛП и машинное обучение улучшили возможности чат-бота, добавив понимание естественного языка и многоязычные возможности.В отличие от стандартной системы классификации, чат-ботов нельзя просто измерить с помощью одного числа или показателя. Идеальный чат-бот должен вести пользователя к конечной цели — продать что-то, решить его проблему и т. Д. Ниже мы обсудим несколько показателей разного уровня и степени детализации.
Как чат-боты могут терпеть неудачу. Кредиты Завершенные разговоры
Это, пожалуй, один из самых важных показателей высокого уровня. Обычно беседа начинается со слов «привет» или «привет» и заканчивается ответом на вопрос типа «Довольны ли вы впечатлениями?» или «Удалось ли вам решить вашу проблему?».
Количество обменов
Довольно часто пользователя раздражает взаимодействие с чатом или он просто не завершает разговор. В таких случаях полезная информация — это подсчет количества обменов между ботом и пользователем до того, как пользователь ушел.
Обратная связь на уровне ответов
Боты на основе современного естественного языка пытаются понять семантику сообщений пользователя. Пользователи не могут использовать именно те слова, которые бот ожидает от него / нее. Тем не менее, продвинутый бот должен попытаться проверить, имеет ли пользователь в виду что-то похожее на то, что ожидается.Чат-боты часто запрашивают отзывы о каждом отправленном им ответе. Например — «Это тот ответ, которого вы ждали. Пожалуйста, введите да или нет ». Таким образом, вы можете просматривать журналы и проверять, где бот работает плохо. Таким образом, вы также можете собирать обучающие данные для машинного обучения семантического сходства.
Механизм рекомендаций
Ни одна успешная компания электронной коммерции не выживает, не зная своих клиентов на личном уровне и не предлагая свои услуги без использования этих знаний. Механизмы рекомендаций являются одним из таких инструментов, позволяющих осмыслить эти знания.Возьмем, к примеру, Netflix. Netflix — интернет-телевидение, награжденное 1 млн долларов компании BellKor’s Pragmatic Chaos , разработавшей алгоритм рекомендаций, который был примерно на 10% лучше, чем существующий алгоритм, используемый Netflix в организованном конкурсе под названием Netflix Prize .
Согласно Netflix, типичный пользователь на его сайте теряет интерес через 60-90 секунд после просмотра 10-12 заголовков, возможно, 3 подробно. Он предлагает задачу рекомендации, поскольку каждый пользователь на каждом экране находит что-то интересное для просмотра и понимает, почему это может быть интересно.Для Netflix крайне важно поддерживать низкий уровень удержания клиентов, поскольку для поддержания численности затраты на привлечение новых клиентов высоки. По их словам, рекомендательная система экономит им долларов на 1 миллиард долларов ежегодно.
Поскольку они так много вкладывают в свои рекомендации, как они вообще измеряют его эффективность в производстве?
Главный экран Netflix с рекомендациями по жанрам. Кредиты Take-Rate
Одна очевидная вещь, на которую стоит обратить внимание, — это то, сколько людей смотрят то, что рекомендует Netflix.Это называется ставкой. Он определяется как доля предложенных рекомендаций, которые приводят к игре.
Эффективный размер каталога (ECS)
Это еще одна метрика, предназначенная для точной настройки успешных рекомендаций. Netflix дает рекомендации на 2 основных уровнях. Первое — Лучшие рекомендации из общего каталога. Во-вторых, рекомендации, относящиеся к жанру. Для определенного жанра, если есть N рекомендаций, ECS измеряет, насколько распространены просмотры по элементам в каталоге.Если большинство просмотров приходится на одно видео, то ECS близко к 1. Если просмотр одинаков для всех видео, то ECS близок к N.
Машинное обучение в производственной среде не статично — Изменения в среде
Допустим, вы инженер машинного обучения в компании социальных сетей. Представьте, что за последние пару недель на вашем сайте публикуется объем контента, в котором только говорится о Covid-19. Почти каждый пользователь, который обычно говорит об искусственном интеллекте или биологии или просто случайно разглагольствует на сайте, теперь говорит о Covid-19.И вы знаете, что это спайк. Тенденция недолговечна. Но на данный момент ваше распределение данных значительно изменилось.
Чего от этого ожидать? Каким должен быть ваш следующий шаг как специалист по ОД? Ожидаете ли вы, что ваша модель машинного обучения будет работать идеально?
Model Drift
Как обсуждалось выше, ваша модель теперь используется для данных, распределение которых ей незнакомо. Продолжим пример с Covid-19. Увеличивается не только количество контента по этой теме, но и количество поисковых запросов, касающихся масок и дезинфицирующих средств.Можно ожидать много возможных тенденций или выбросов. Модель машинного обучения, обученная на статических данных, не может учесть эти изменения. Он страдает от чего-то, что называется , модель дрейфа или с одновременным переключением передач .
Тесты, используемые для отслеживания производительности моделей, естественно, могут помочь в обнаружении отклонения модели. Можно настроить тесты обнаружения изменений для обнаружения дрейфа как изменения статистики процесса генерации данных. Можно уменьшить дрейф, предоставив некоторую контекстную информацию, как в случае с Covid-19, некоторую информацию, которая указывает на то, что текст или твит относятся к теме, которая в последнее время была в тренде.Таким образом, модель может обусловить предсказание такой конкретной информацией. Хотя полностью избавиться от дрейфа не удастся.
Цикл переподготовки повышает производительность модели. Но вскоре она может начать падать.Решение — Переобучение модели
Вопросы, которые следует задать перед переобучением
До сих пор мы установили идею дрейфа модели. Как решить эту проблему? Мы можем переобучить нашу модель на новых данных. Так следует ли нам снова вызвать model.fit () и положить этому конец?
- Сколько данных взять на переподготовку?
Сколько новых данных нужно брать на переподготовку? Стоит ли использовать более старые данные? Если да, то какой должен быть хороший микс? Здесь могут помочь знания и опыт в предметной области.Если вы знаете, что распределение данных часто меняется, вы можете взять большую часть новых данных. Точно так же, если у вас не так много новых примеров, но производительность вашей модели ухудшается, вы можете взять все новые данные и значительную часть старых данных для повторного обучения. - Как часто нужно переобучаться?
Как часто должны выполняться наши задания по переподготовке? Если вы периодически получаете новые данные, вы можете соответствующим образом запланировать задания по переподготовке. Например, если вы прогнозируете, какой абитуриент будет принят в школу на основе его личных данных, нет смысла выполнять учебные задания каждый день.Потому что вы получаете новые данные каждый семестр / год. - Стоит ли переучивать всю модель?
Следует ли обучать всю модель с новыми данными? Если ваша модель огромна, обучение всей модели требует больших затрат времени и средств. Возможно, вам стоит просто обучить несколько слоев и заморозить остальную часть сети. Например, XLNet, очень большая модель глубокого обучения, используемая для задач НЛП, стоит 245000 долларов на обучение. Да, та сумма денег на обучение модели машинного обучения. Скорее всего, вы не будете использовать такое количество вычислительной мощности, но модель обучения на облачных графических процессорах / TPU может быть очень дорогой.Если модель имеет размер в ГБ, ее хранение также может потребовать значительных затрат. При глубоком обучении возможно замораживание части модели. Это сложно реализовать в традиционных алгоритмах машинного обучения. Но в любом случае их обучение не требует больших вычислительных затрат по сравнению с моделями глубокого обучения. - Стоит ли развертывать сразу после переподготовки?
Должны ли мы слепо доверять нашей переобученной модели и развертывать ее, как только она будет обучена? По-прежнему существует риск того, что новая модель будет работать хуже, чем старая, даже после переобучения на новых данных.Часто рекомендуется позволить старой модели обслуживать запросы в течение некоторого времени после построения переобученной модели. Переобученная модель может генерировать теневые прогнозы. Это означает, что прогнозы не будут использоваться напрямую, но будут регистрироваться для проверки правильности новой модели. Если вы удовлетворены, старую модель можно заменить на более новую. Можно автоматизировать развертывание переподготовки, но не рекомендуется, если вы не уверены. Лучший способ — сначала выполнить развертывание вручную, пока вы не уверены.
Есть еще много вопросов, которые можно задать в зависимости от приложения и бизнеса.
Настройка инфраструктуры для переподготовки моделей
Как и в большинстве отраслевых сценариев использования машинного обучения, код машинного обучения редко является основной частью системы. Есть большие проблемы и усилия с окружающим кодом инфраструктуры. Прежде чем перейти к примеру, давайте рассмотрим несколько полезных инструментов:
Контейнеры
Контейнеры — это изолированные приложения. Вы можете легко содержать код приложения и их зависимости и последовательно создавать одно и то же приложение в разных системах.Они работают в изолированной среде и не мешают работе остальной системы. Они более ресурсоэффективны, чем виртуальные машины.
Kubernetes
Это инструмент для управления контейнерами. Он помогает масштабировать контейнерные приложения и управлять ими.
В нашем случае, если мы хотим автоматизировать процесс переобучения модели, нам нужно настроить задание на обучение в Kubernetes. Работа Kubernetes — это контроллер, который следит за тем, чтобы модули выполняли свою работу. Поды — это самые маленькие развертываемые единицы в Kubernetes.Вместо того, чтобы запускать контейнеры напрямую, Kubernetes запускает поды, которые содержат один или несколько контейнеров. Работа по обучению завершит обучение и сохранит модель где-нибудь в облаке. Мы можем сделать еще одно задание вывода, которое использует сохраненную модель для вывода.
Вышеупомянутая система была бы довольно простой. В зависимости от стратегии есть потенциал для гораздо большего развития инфраструктуры. Допустим, вы хотите использовать тест «чемпион-претендент», чтобы выбрать лучшую модель.У вас будет модель Champion в производстве, и у вас будет, скажем, 3 модели Challenger. Все четверо проходят оценку. Вы решаете, сколько запросов будет распределено по каждой модели случайным образом. В зависимости от производительности и статистических тестов вы принимаете решение, будет ли одна из моделей претендента работать значительно лучше, чем модель чемпиона. Очень похоже на A / B-тестирование. В приведенной выше стратегии тестирования потребуется дополнительная инфраструктура — например, настройка процессов для распределения запросов и протоколирования результатов для каждой модели, определение лучшей из них и ее автоматическое развертывание.
Онлайн-обучение
Обычно модели машинного обучения обучаются в автономном режиме пакетами (на новых данных) специалистами по данным наилучшим образом, а затем развертываются в производственной среде. В случае дрейфа плохой производительности модели проходят переобучение и обновление. Даже конвейер переподготовки моделей можно автоматизировать. Но что, если модель непрерывно обучалась? Например, он обновляет параметры каждый раз, когда используется. Близко к «обучению на лету». Это поможет вам узнать об изменениях в распределении как можно быстрее и во многих случаях уменьшить дрейф.
Например, вы строите модель, которая использует обновления новостей, прогнозы погоды и данные социальных сетей для прогнозирования количества осадков в регионе. В конце концов, у вас есть точная мера количества осадков, выпавших в этом регионе. Затем ваша модель использует данные за этот конкретный день для постепенного улучшения следующих прогнозов.
Методы онлайн-обучения оказались относительно быстрее, чем их методы пакетного эквивалента. Одна вещь, которая не очевидна в онлайн-обучении, — это его обслуживание: если есть какие-либо неожиданные изменения в конвейерах обработки данных в восходящем направлении, тогда трудно управлять влиянием на онлайн-алгоритм.Раньше данные сбрасывались в хранилище в облаке, а затем обучение происходило в автономном режиме, не влияя на текущую развернутую модель, пока не будет готова новая. Теперь восходящие трубопроводы больше связаны с прогнозами модели. Кроме того, сложно выбрать набор тестов, поскольку у нас нет предварительных предположений о распределении. Если мы выберем набор тестов для оценки, мы предположим, что набор тестов является репрезентативным для данных, с которыми мы работаем.
Заключение
В этом посте мы увидели, как плохое машинное обучение может стоить компании денег и репутации, почему сложно измерить производительность реальной модели и как мы можем сделать это эффективно.Мы также рассмотрели различные стратегии оценки на конкретных примерах, таких как системы рекомендаций и чат-боты. Наконец, мы поняли, как дрейф данных делает машинное обучение динамичным и как мы можем решить эту проблему с помощью переобучения.
Трудно построить систему машинного обучения с нуля. Особенно, если у вас нет собственной команды опытных инженеров по машинному обучению, облачным технологиям и DevOps. Вот где мы можем вам помочь! Вы можете легко создавать потрясающие модели машинного обучения для классификации изображений, обнаружения объектов, OCR (автоматизация квитанций и счетов) на нашей платформе, и это тоже с меньшим объемом данных.Кроме того, развернуть его так же просто, как несколько строк кода. Сделайте свою бесплатную модель сегодня на сайте nanonets.com
Возможно, вам будут интересны наши последние публикации на сайте:
Переподготовка подходов к модели машинного обучения
@akhilkasare
Ахил КасареЯ увлечен решением бизнес-задач с помощью науки о данных. Я считаю, что каждому номеру есть что рассказать.
Содержание:
- Переобучение моделей машинного обучения
- Дрейф модели
- Различные способы определения отклонения модели
- Снижение производительности
- Корреляция между функциями
- Изучение целевых распределений
- Переобучение модели
- Как часто вы моделируете надо переучивать?
- Как можно переобучить модель?
- Каталожный номер
Перед тем, как подробно рассказать о подходах к переобучению моделей машинного обучения, давайте рассмотрим основные циклы моделей машинного обучения.
Обычно модели машинного обучения обучаются путем обучения между набором входных функций и зависимой функцией или целевой переменной. Целью модели является минимизация ошибки прогнозирования путем применения или оптимизации функций затрат, и когда мы найдем некоторые оптимизированные модели, мы развернем их в производстве, и цель состоит в том, чтобы модель также генерировала точные прогнозы на будущих невидимых данных. Таким образом, цель состоит в том, чтобы модель предсказывала будущие невидимые данные так же точно, как данные, используемые во время периода обучения.
После развертывания моделей машинного обучения в производственной среде мы предполагаем, что будущие невидимые данные будут аналогичны прошлым данным, с помощью которых мы обучили нашу модель. Более того, наши предположения похожи на то, что распределение данных всех функций должно оставаться постоянным, но это не всегда так. Распределение данных со временем будет меняться, и наша модель должна адаптировать эти изменения .
Если мы возьмем пример прогнозирования цен на жилье, то цены на дома не будут оставаться неизменными все время.Данные, которые использовались для обучения модели, предсказывающей цены на жилье несколько месяцев назад, сегодня не дадут хороших прогнозов. Нам нужна актуальная информация для обучения моделей.
При разработке любой модели машинного обучения важно понимать, как данные будут меняться с течением времени. Необходима хорошая архитектурная система или план для обновления наших моделей.
Иногда, чтобы узнать об этих типах изменений или контролировать производительность модели, используется концепция Model Drift .Посмотрим, что это такое.
2. Смещение модели
Смещение модели относится к нескольким параметрам, которые со временем изменятся . Есть много случаев, когда производительность прогнозирования со временем ухудшается, и это может происходить из-за некоторых изменений окружающей среды, и существует необходимость определения этих отклонений модели, и это можно устранить с помощью различных подходов к переподготовке модели .
Когда мы говорим Model Drift , конечно же, , это не та модель, которая дрейфует на . Окружающая среда вокруг модели меняется.
Существуют разные подходы к выявлению отклонений модели и подходы к переобучению моделей, но не существует единого стандартного метода для всех видов проблем. Для решения различных проблем должны применяться разные методы.
3. Каковы различные способы определения отклонения модели?3.1 УМЕНЬШЕНИЕ ПРОИЗВОДИТЕЛЬНОСТИ
Чтобы определить дрейф модели, необходимо явно определить, что прогностические характеристики ухудшились, и количественно оценить это снижение.
Рассмотрим модель финансового прогнозирования, которая позволит спрогнозировать доход в следующем квартале. Фактический доход не будет наблюдаться до истечения этого квартала, поэтому мы не сможем увидеть, насколько хорошо наша модель работала до этого момента. Это даст некоторое представление о том, с какой скоростью производительность модели будет ухудшаться.
Как указывает Джош Уиллс, одна из самых важных вещей, которые вы можете сделать перед развертыванием модели, — это попытаться понять дрейф модели в автономной среде.
Специалисты по обработке данных должны попытаться ответить на вопрос « Если я тренирую модель, используя этот набор функций на данных, полученных шесть месяцев назад, и применяю ее к данным, которые я сгенерировал сегодня, насколько эта модель хуже той, что Я создал необученные данные за месяц назад и подал заявку на сегодняшний день? ”
3.2 Распределение обучающих и оперативных данных
Поскольку будет снижение производительности модели из-за распределения данных, которые отклоняются от обучающих данных, их сравнение позволит сделать вывод о дрейфе модели, поскольку мы ожидаем, что это произойдет. Мы можем контролировать эти вещи с помощью диапазона значений, гистограмм, имеют ли они нулевые значения или нет, и так далее.
3.3 СВЯЗЬ МЕЖДУ ХАРАКТЕРИСТИКАМИ
При построении модели предполагается, что связь остается фиксированной.Поэтому мы будем отслеживать попарные корреляции между отдельными признаками.
Как указано в Каков ваш результат теста ML? Рубрика для производственных систем машинного обучения , вы можете сделать это следующим образом:
- мониторинг коэффициентов корреляции между функциями
- обучающие модели с одной или двумя функциями
- обучение набора моделей, у каждой из которых одна из функций удалена
3.4 ИЗУЧЕНИЕ ЦЕЛЕВОГО РАСПРЕДЕЛЕНИЯ
Если распределение зависимой переменной изменяется очень часто или значительно, производительность модели ухудшится.Авторы книги Machine Learning: The High-Interest Credit Card of Technical Debt заявляют, что одна простая и полезная диагностика — отслеживать целевое распределение.
4. Переобучение модели
Иногда переобучение модели относится к поиску нового гиперпараметра существующей архитектуры модели. Дайте понять, что речь не идет о поиске новых параметров, поиск новых моделей — это добавление / обновление функций модели. Поэтому нам нужно подумать о нашей проблеме, чтобы уменьшить дрейф модели в нашей производственной модели.
Весь процесс построения модели машинного обучения проходит через набор циклов от разработки функций до выбора модели и оценки ошибок. Затем будет выбрана оптимальная модель и запущена в производство.
Поскольку дрейф модели означает снижение производительности модели из-за некоторых причин, таких как изменение данных или изменение среды, повторное обучение модели не должно приводить к процессу создания другой модели.
Скорее, переобучение просто означает повторный запуск процесса, который сгенерировал ранее выбранную модель на новом обучающем наборе данных.
Функции, алгоритм модели и пространство поиска гиперпараметров должны остаться прежними. Один из способов подумать об этом — это то, что переподготовка не предполагает каких-либо изменений кода. Это включает только изменение набора обучающих данных.
Не похоже, что не следует изменять параметры и добавлять функции, но если мы это сделаем, то возникнет необходимость в совершенно новом процессе построения модели, который необходимо протестировать перед развертыванием в производственной среде.
5. Как часто нужно проходить переподготовку модели?
Не существует стандартного правила, согласно которому мы должны переобучать модель еженедельно, ежемесячно или ежеквартально.Все зависит от варианта использования и варьируется от проблемы к проблеме.
Если мы ищем модель студента, которая предсказывает возвращение студентов в следующем семестре, тогда нет смысла переобучать модель ежедневно, так как будет режим данных по семестру, поэтому мы можем переучиваться ежеквартально или как в новом семестре.
Это пример расписания периодической переподготовки. Часто бывает неплохо начать с этой простой стратегии, но вам нужно будет точно определить, как часто вам нужно будет переучиваться.Для быстрой смены тренировочных наборов может потребоваться тренировка ежедневно или еженедельно. Более медленное изменение распределения может потребовать ежемесячной или ежегодной переподготовки.
6. Как можно переобучить модель?
- Для модели переобучения в машинном обучении напрямую зависит от того, как часто мы решаем переобучать нашу модель.
- Если мы решим периодически переобучать нашу модель, то пакетного переобучения вполне достаточно. Это включает в себя планирование процессов обучения модели на регулярной основе с использованием планировщика заданий, такого как Jenkins или Kubernetes Cron Jobs.
- Если вы используете автоматическое обнаружение дрейфа модели, то имеет смысл запускать повторное обучение модели при обнаружении дрейфа. Например, у вас могут быть периодические задания, которые сравнивают распределения функций наборов данных в реальном времени с распределениями данных обучения. При обнаружении значительного отклонения система может автоматически запланировать повторное обучение модели для автоматического развертывания новой модели. Опять же, это можно сделать с помощью планировщика заданий, такого как Jenkins, или с помощью Kubernetes Jobs.
- Возможно, имеет смысл использовать методы онлайн-обучения для обновления модели, которая в настоящее время находится в производстве.Этот подход основан на « с начальным значением » — новой модели с моделью, которая в настоящее время развернута. По мере поступления новых данных параметры модели обновляются новыми обучающими данными.
Помимо этого, существуют различные подходы, которым мы можем следовать, например,
- Переобучить модель с использованием bigmler (BigML — это сторонние сервисы, которые обеспечивают автоматическое построение модели машинного обучения, а bigMLer — инструмент командной строки, который может помочь переобучить модель. с использованием их API)
- DeltaGrad: быстрое переобучение моделей машинного обучения (это основано на исследовательской работе, ссылки приведены в справочном разделе)
- автоматическая переподготовка моделей с конвейерами kubeflow (Kubernet также предоставляет автоматическое kubefloe конвейеры для переподготовки моделей)
- машинное обучение-автоматизированная-модельная-переподготовка-sagemaker (Amazon предоставляет облачные сервисы для автоматического переподготовки и развертывания моделей.Часть реализации этого вы найдете в другом блокноте)
Непрерывное обучение с Watson ML (IBM также предоставляет облачный сервис Watson ML для той же цели переподготовки)
7. СсылкиРанее опубликовано на https: //akhil-kasare80.medium.com/retraining-machine-learning-models-how-important-it-is-e39e475bca9c
, автор — Ахил Касаре @akhilkasare. Я увлечен решением бизнес-задач с помощью науки о данных.Я считаю, что каждому номеру есть что рассказать. Прочтите мои историиПохожие истории
Теги
Присоединяйтесь к хакеру ПолденьСоздайте бесплатную учетную запись, чтобы разблокировать свой собственный опыт чтения.
Как обновить модели нейронных сетей с дополнительными данными
Возможно, потребуется обновить модели нейронных сетей с глубоким обучением, используемые для прогнозного моделирования.
Это может быть связано с тем, что данные изменились с момента разработки и развертывания модели, или может быть так, что дополнительные помеченные данные стали доступными с момента разработки модели, и ожидается, что дополнительные данные улучшат производительность модель.
Важно экспериментировать и оценивать различные подходы при обновлении моделей нейронных сетей для новых данных, особенно если обновление модели будет автоматическим, например, по периодическому расписанию.
Существует множество способов обновления моделей нейронных сетей , хотя два основных подхода включают либо использование существующей модели в качестве отправной точки и ее повторное обучение, либо оставление существующей модели без изменений и объединение прогнозов существующей модели с новой моделью. .
В этом руководстве вы узнаете, как обновлять модели нейронных сетей с глубоким обучением в ответ на новые данные.
После прохождения этого руководства вы будете знать:
- Возможно, потребуется обновить модели нейронных сетей при изменении базовых данных или при появлении новых помеченных данных.
- Как обновить обученные модели нейронной сети только новыми данными или комбинациями старых и новых данных.
- Как создать ансамбль существующих и новых моделей, обученных только новым данным или комбинациям старых и новых данных.
Приступим.
Как обновить модели нейронных сетей дополнительными данными
Фото Джуди Галлахер, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на три части; их:
- Обновление моделей нейронных сетей
- Переподготовка обновлений
- Обновить модель только по новым данным
- Обновить модель на старых и новых данных
Стратегии обновления ансамбля - Модель ансамбля с моделью только по новым данным Модель ансамбля
- с моделью на старых и новых данных
Обновление моделей нейронных сетей
Выбор и доработка модели нейронной сети с глубоким обучением для проекта прогнозного моделирования — это только начало.
Затем вы можете начать использовать модель для прогнозирования новых данных.
Одна из возможных проблем, с которыми вы можете столкнуться, заключается в том, что характер проблемы прогнозирования может со временем измениться.
Вы можете заметить это по тому факту, что эффективность прогнозов может начать снижаться со временем. Это может быть связано с тем, что предположения, сделанные и зафиксированные в модели, меняются или больше не выполняются.
Обычно это называется проблемой «дрейфа концепции », когда лежащие в основе распределения вероятностей переменных и отношения между переменными меняются со временем, что может отрицательно повлиять на модель, построенную на основе данных.
Подробнее о дрейфе концепций см. В руководстве:
Дрейф концепций может повлиять на вашу модель в разное время и зависит, в частности, от решаемой задачи прогнозирования и модели, выбранной для ее решения.
Может быть полезно отслеживать производительность модели с течением времени и использовать явное падение производительности модели в качестве триггера для внесения изменений в вашу модель, например повторного обучения ее на новых данных.
В качестве альтернативы вы можете знать, что данные в вашем домене меняются достаточно часто, поэтому изменение модели требуется периодически, например, еженедельно, ежемесячно или ежегодно.
Наконец, вы можете некоторое время работать со своей моделью и накапливать дополнительные данные с известными результатами, которые вы хотите использовать для обновления вашей модели, в надежде улучшить прогнозные характеристики.
Важно отметить, что вы можете гибко реагировать на изменение проблемы или появление новых данных.
Например, вы можете взять обученную модель нейронной сети и обновить веса модели, используя новые данные. Или мы можем оставить существующую модель нетронутой и объединить ее прогнозы с новой моделью, соответствующей новым доступным данным.
Эти подходы могут представлять две общие темы обновления моделей нейронных сетей в ответ на новые данные:
- Переучить стратегии обновления.
- Стратегии обновления ансамбля.
Давайте рассмотрим каждый по очереди.
Стратегии обновления для переподготовки
Преимущество моделей нейронных сетей заключается в том, что их веса можно обновлять в любое время при непрерывном обучении.
При реагировании на изменения в базовых данных или на доступность новых данных существует несколько различных стратегий на выбор при обновлении модели нейронной сети, например:
- Продолжить обучение модели только на новых данных.
- Продолжить обучение модели на старых и новых данных.
Мы также можем представить себе варианты вышеупомянутых стратегий, такие как использование выборки новых данных или выборки новых и старых данных вместо всех доступных данных, а также возможные взвешивания на основе экземпляров для выборочных данных.
Мы могли бы также рассмотреть расширения модели, которые замораживают слои существующей модели (например, чтобы веса модели не могли измениться во время обучения), затем добавляли новые слои с весами модели, которые могут изменяться, добавляя расширения к модели для обработки любых изменений в данные.Возможно, это вариант переобучения и ансамблевого подхода в следующем разделе, и мы пока оставим его.
Тем не менее, это две основные стратегии, которые следует учитывать.
Давайте конкретизируем эти подходы на рабочем примере.
Обновить модель только на новых данных
Мы можем обновить модель только по новым данным.
Одна крайняя версия этого подхода — не использовать какие-либо новые данные и просто повторно обучать модель на старых данных. Это может быть то же самое, что « ничего не делать, » в ответ на новые данные.С другой стороны, модель может быть приспособлена только к новым данным, отбрасывая старые данные и старую модель.
- Игнорировать новые данные, ничего не делать.
- Обновить существующую модель по новым данным.
- Совместите новую модель с новыми данными, удалите старую модель и данные.
В этом примере мы сосредоточимся на промежуточной позиции, но может быть интересно протестировать все три подхода к вашей проблеме и посмотреть, какой из них работает лучше всего.
Во-первых, мы можем определить набор данных синтетической двоичной классификации и разделить его на две части, а затем использовать одну часть как « старых данных », а другую часть как « новых данных .”
… # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1)
… # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) |
Затем мы можем определить модель многослойного персептрона (MLP) и подогнать ее только к старым данным.
… # определить модель model = Последовательный () model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) модель.добавить (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0)
… # определить модель model = Sequential () model.add (Dense (20, kernel_initializer = ‘he_normal’, activate = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0,01, импульс = 0,9) # скомпилировать модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным model.fit (X_old, y_old, epochs = 150, размер партии = 32, подробный = 0) |
Затем мы можем представить себе сохранение модели и использование ее в течение некоторого времени.
Время идет, и мы хотим обновить его с учетом новых данных, которые стали доступны.
Это потребует использования гораздо меньшей скорости обучения, чем обычно, чтобы мы не смывали веса, полученные на старых данных.
Примечание : вам нужно будет определить скорость обучения, подходящую для вашей модели и набора данных, которая обеспечивает лучшую производительность, чем простая установка новой модели с нуля.
… # обновлять модель на новых данных только с меньшей скоростью обучения opt = SGD (скорость_обучения = 0.001, импульс = 0,9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’)
… # обновить модель только для новых данных с меньшей скоростью обучения opt = SGD (learning_rate = 0,001, импульс = 0,9) # скомпилировать модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) |
Затем мы можем подогнать модель к новым данным только с этой меньшей скоростью обучения.
… model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на новые данные model.fit (X_new, y_new, epochs = 100, batch_size = 32, verbose = 0)
… model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # соответствует модели на новых данных model.fit (X_new, y_new, epochs = 100, batch_size = 32, verbose = 0) |
В совокупности ниже приведен полный пример обновления модели нейронной сети только на основе новых данных.
# обновить нейронную сеть только новыми данными из sklearn.datasets импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models импортировать последовательный из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers импорт SGD # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.форма [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить модель model = Последовательный () model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель модель.компилировать (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # обновлять модель на новых данных только с меньшей скоростью обучения opt = SGD (скорость обучения = 0,001, импульс = 0,9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на новые данные model.fit (X_new, y_new, epochs = 100, batch_size = 32, verbose = 0)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 19 20 21 22 23 24 25 26 27 28 29 30 34 | # обновить нейронную сеть только новыми данными из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models import Sequential из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers 9000 , dataset, импортировать SG4D, dataset SG4D y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1)# записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить модель model = Sequential () model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0.01, импульс = 0,9) # скомпилировать модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным model.fit (X_old, y_old, epochs = 150 , batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # обновить модель только для новых данных с меньшей скоростью обучения opt = SGD (скорость обучения = 0,001, импульс = 0,9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # соответствует модели на новых данных model.fit (X_new, y_new, epochs = 100, batch_size = 32, verbose = 0) |
Теперь давайте посмотрим на обновление модели с учетом новых и старых данных.
Обновить модель на старых и новых данных
Мы можем обновить модель, используя как старые, так и новые данные.
Крайний вариант этого подхода — отказаться от модели и просто подогнать новую модель ко всем имеющимся данным, новым и старым.Менее радикальный вариант — использовать существующую модель в качестве отправной точки и обновлять ее на основе объединенного набора данных.
Опять же, неплохо протестировать обе стратегии и посмотреть, что хорошо работает для вашего набора данных.
В этом случае мы сосредоточимся на менее радикальной стратегии обновления.
Синтетический набор данных и модель могут соответствовать старому набору данных, как и раньше.
… # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.форма [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить модель model = Последовательный () model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель модель.компилировать (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 | … # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить модель model = Sequential () model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0,01, импульс = 0,9) # скомпилировать модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным model.fit (X_old, y_old, epochs = 150, размер партии = 32, подробный = 0) |
Появляются новые данные, и мы хотим обновить модель, сочетая как старые, так и новые данные.
Во-первых, мы должны использовать гораздо меньшую скорость обучения, чтобы попытаться использовать текущие веса в качестве отправной точки для поиска.
Примечание : вам нужно будет определить скорость обучения, подходящую для вашей модели и набора данных, которая обеспечивает лучшую производительность, чем простая установка новой модели с нуля.
… # обновить модель с меньшей скоростью обучения opt = SGD (скорость обучения = 0,001, импульс = 0,9) # компилируем модель модель.компиляция (оптимизатор = opt, loss = ‘binary_crossentropy’)
… # обновить модель с меньшей скоростью обучения opt = SGD (learning_rate = 0,001, импульс = 0,9) # скомпилировать модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’ ) |
Затем мы можем создать составной набор данных, состоящий из старых и новых данных.
… # создать составной набор старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new))
… # создать составной набор данных из старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new)) |
Наконец, мы можем обновить модель в этом составном наборе данных.
… # подгоняем модель на новые данные model.fit (X_both, y_both, epochs = 100, batch_size = 32, verbose = 0)
… # соответствует модели по новым данным модель.fit (X_both, y_both, эпохи = 100, размер_пакета = 32, подробный = 0) |
Полный пример обновления модели нейронной сети как на старых, так и на новых данных приведен ниже.
# обновить нейронную сеть как старыми, так и новыми данными из numpy import vstack из numpy import hstack из sklearn.datasets импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.модели импортируют Последовательный из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers импорт SGD # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить модель model = Последовательный () модель.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0) # сохранить модель… # загрузить модель … # обновить модель с меньшей скоростью обучения opt = SGD (скорость обучения = 0,001, импульс = 0,9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # создать составной набор старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new)) # подгоняем модель на новые данные model.fit (X_both, y_both, epochs = 100, batch_size = 32, verbose = 0)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 | # обновить нейронную сеть со старыми и новыми данными из numpy import vstack из numpy import hstack из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models import Sequential из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers 9000 , dataset, импортировать SG4D, dataset SG4D y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1)# записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить модель model = Sequential () model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0.01, импульс = 0,9) # скомпилировать модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным model.fit (X_old, y_old, epochs = 150 , batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # обновить модель с меньшей скоростью обучения opt = SGD (Learning_rate = 0.001 , momentum = 0.9) # компилируем модель model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # создать составной набор данных из старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new)) # подогнать модель по новым данным model.fit (X_both, y_both, epochs = 100, batch_size = 32, verbose = 0) |
Теперь давайте посмотрим, как использовать ансамблевые модели для реагирования на новые данные.
Стратегии обновления ансамбля
Ансамбль — это прогнозная модель, состоящая из нескольких других моделей.
Существует много различных типов ансамблевых моделей, хотя, возможно, самый простой подход — это усреднение прогнозов, полученных от нескольких различных моделей.
Подробнее об ансамблевых алгоритмах для нейронных сетей с глубоким обучением см. В руководстве:
Мы можем использовать ансамблевую модель в качестве стратегии при реагировании на изменения в базовых данных или на доступность новых данных.
Отражая подходы из предыдущего раздела, мы могли бы рассмотреть два подхода к алгоритмам ансамблевого обучения как стратегии реагирования на новые данные; их:
- Совокупность существующей модели и новой модели подходит только для новых данных.
- Ансамбль существующей модели и новой модели соответствует старым и новым данным.
Опять же, мы могли бы рассмотреть варианты этих подходов, такие как выборки старых и новых данных и более одной существующей или дополнительной модели, включенной в ансамбль.
Тем не менее, это две основные стратегии, которые следует учитывать.
Давайте конкретизируем эти подходы на рабочем примере.
Модель ансамбляс моделью только по новым данным
Мы можем создать ансамбль существующей модели и новую модель, подходящую только для новых данных.
Ожидается, что ансамблевые прогнозы будут работать лучше или будут более стабильными (с меньшей дисперсией), чем при использовании только старой или новой модели. Это следует проверить в вашем наборе данных перед принятием ансамбля.
Во-первых, мы можем подготовить набор данных и подогнать под старую модель, как мы это делали в предыдущих разделах.
… # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.форма [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определяем старую модель old_model = Последовательный () old_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) old_model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0.9) # компилируем модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные old_model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 | … # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить старую модель old_model = Sequential () old_model.add (Dense (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) old_model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (Learning_rate = 0,01, импульс = 0,9) # скомпилировать модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подобрать модель на старых данных old_model.fit (X_old, y_old, epochs = 150, размер партии = 32, подробный = 0) |
Проходит время, и появляются новые данные.
Затем мы можем подогнать новую модель к новым данным, естественно обнаружив модель и конфигурацию, которые хорошо или лучше всего работают только с новым набором данных.
В этом случае мы просто будем использовать ту же архитектуру и конфигурацию модели, что и старая модель.
… # определить новую модель new_model = Последовательный () new_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) new_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) новая модель.добавить (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’)
… # определить новую модель new_model = Sequential () new_model.add (Dense (20, kernel_initializer = ‘he_normal’, activate = ‘relu’, input_dim = n_features)) new_model.add (Dense (10, kernel_initializer = ‘he_normal’, Activation = ‘relu’)) new_model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (Learning_rate = 0,01, импульс = 0,9) # компилируем модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) |
Затем мы можем подогнать эту новую модель только к новым данным.
… # подгоняем модель на старые данные новая модель.fit (X_new, y_new, epochs = 150, batch_size = 32, verbose = 0)
… # подогнать модель по старым данным new_model.fit (X_new, y_new, epochs = 150, batch_size = 32, verbose = 0) |
Теперь, когда у нас есть две модели, мы можем делать прогнозы для каждой модели и вычислять среднее значение прогнозов как «прогноз ансамбля ».
… # делаем прогнозы с обеими моделями yhat1 = старая_модель.предсказать (X_new) yhat2 = новая_модель.predict (X_new) # объединить прогнозы в единый массив комбинированный = hstack ((yhat1, yhat2)) # рассчитать результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1)
… # сделать прогнозы с обеими моделями yhat1 = old_model.predict (X_new) yhat2 = new_model.predict (X_new) # объединить прогнозы в один массив комбинированный = hstack ((ystack yhat2)) # вычислить результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1) |
Если объединить все вместе, ниже приведен полный пример обновления с использованием ансамбля существующей модели и новой модели, подходящей только для новых данных.
# объединить старую нейронную сеть с новой моделью, подходящей только для новых данных из numpy import hstack из среднего значения импорта из sklearn.datasets импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models импортировать последовательный из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers импорт SGD # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.форма [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определяем старую модель old_model = Последовательный () old_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) old_model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0.9) # компилируем модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные old_model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # определить новую модель new_model = Последовательный () new_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) new_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) новая модель.добавить (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные new_model.fit (X_new, y_new, epochs = 150, batch_size = 32, verbose = 0) # делаем прогнозы с обеими моделями yhat1 = old_model.predict (X_new) yhat2 = новая_модель.predict (X_new) # объединить прогнозы в единый массив комбинированный = hstack ((yhat1, yhat2)) # рассчитать результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 47 | # ансамбль старой нейронной сети с новой моделью, подходящей только для новых данных из numpy import hstack из numpy import mean из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models import Sequential из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers 9000 , dataset, импортировать SG4D, dataset SG4D y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1)# записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить старую модель old_model = Sequential ( ) old_model.add (Dense (20, kernel_initializer = ‘he_normal’, activate = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’) ) old_model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0.01, импульс = 0,9) # скомпилировать модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным old_model.fit (X_old, y_old, epochs = 150 , batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # определить новую модель new_model = Sequential () new_model.add (Плотный (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) новая_модель.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) new_model.add (Dense (1, activation = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (Learning_rate = 0,01, импульс = 0,9) # скомпилировать модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подобрать модель на старых данных new_model.fit (X_new, y_new, epochs = 150, batch_size = 32, verbose = 0) # делать прогнозы с обеими моделями yhat1 = old_model.predict (X_new) yhat2 = new_model.predict (X_new) # объединить прогнозы в единый массив комбинированный = hstack ((yhat1, yhat2)) # рассчитать результат как среднее значение прогнозов yhat = среднее (объединенное) , ось = -1) |
с моделью на старых и новых данных
Мы можем создать ансамбль существующей модели и новую модель, подходящую как для старых, так и для новых данных.
Ожидается, что ансамблевые прогнозы будут работать лучше или будут более стабильными (с меньшей дисперсией), чем при использовании только старой или новой модели.Это следует проверить в вашем наборе данных перед принятием ансамбля.
Во-первых, мы можем подготовить набор данных и подогнать под старую модель, как мы это делали в предыдущих разделах.
… # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определяем старую модель old_model = Последовательный () old_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) old_model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные старая_модель.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 | … # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить старую модель old_model = Sequential ( ) old_model.add (Dense (20, kernel_initializer = ‘he_normal’, activate = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’) ) old_model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0.01, импульс = 0,9) # скомпилировать модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным old_model.fit (X_old, y_old, epochs = 150 , batch_size = 32, verbose = 0) |
Проходит время, и появляются новые данные.
Затем мы можем подогнать новую модель к комбинации старых и новых данных, естественно обнаружив модель и конфигурацию, которые хорошо или лучше всего работают только с новым набором данных.
В этом случае мы просто будем использовать ту же архитектуру и конфигурацию модели, что и старая модель.
… # определить новую модель new_model = Последовательный () new_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) new_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) new_model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость_обучения = 0.01, импульс = 0,9) # компилируем модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’)
… # определить новую модель new_model = Sequential () new_model.add (Dense (20, kernel_initializer = ‘he_normal’, activate = ‘relu’, input_dim = n_features)) new_model. add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’)) new_model.add (Dense (1, activation = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (Learning_rate = 0.01, импульс = 0,9) # компилируем модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) |
Мы можем создать составной набор данных из старых и новых данных, а затем подогнать новую модель к этому набору данных.
… # создать составной набор старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new)) # подгоняем модель на старые данные new_model.fit (X_both, y_both, эпохи = 150, размер_пакета = 32, подробный = 0)
… # создать составной набор данных из старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new)) # соответствовать модели на старых данных new_model. fit (X_both, y_both, эпохи = 150, размер_пакета = 32, подробный = 0) |
Наконец, мы можем использовать обе модели вместе, чтобы делать ансамблевые прогнозы.
… # делаем прогнозы с обеими моделями yhat1 = old_model.predict (X_new) yhat2 = новая_модель.предсказать (X_new) # объединить прогнозы в единый массив комбинированный = hstack ((yhat1, yhat2)) # рассчитать результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1)
… # сделать прогнозы с обеими моделями yhat1 = old_model.predict (X_new) yhat2 = new_model.predict (X_new) # объединить прогнозы в один массив комбинированный = hstack ((ystack yhat2)) # вычислить результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1) |
Объединяя все это вместе, ниже приводится полный пример обновления с использованием ансамбля существующей модели и новой модели, подходящей для старых и новых данных.
# объединить старую нейронную сеть с новой моделью, подходящей для старых и новых данных из numpy import hstack из numpy import vstack из среднего значения импорта из sklearn.datasets импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models импортировать последовательный из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers импорт SGD # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1) # записываем количество входных функций в данные n_features = X.форма [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определяем старую модель old_model = Последовательный () old_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) old_model.add (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0.9) # компилируем модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подгоняем модель на старые данные old_model.fit (X_old, y_old, epochs = 150, batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # определить новую модель new_model = Последовательный () new_model.add (Dense (20, kernel_initializer = ‘he_normal’, активация = ‘relu’, input_dim = n_features)) new_model.add (Dense (10, kernel_initializer = ‘he_normal’, активация = ‘relu’)) новая модель.добавить (Плотный (1, активация = ‘сигмоид’)) # определяем алгоритм оптимизации opt = SGD (скорость обучения = 0,01, импульс = 0,9) # компилируем модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # создать составной набор старых и новых данных X_both, y_both = vstack ((X_old, X_new)), hstack ((y_old, y_new)) # подгоняем модель на старые данные new_model.fit (X_both, y_both, эпохи = 150, размер_пакета = 32, подробный = 0) # делаем прогнозы с обеими моделями yhat1 = старая_модель.предсказать (X_new) yhat2 = новая_модель.predict (X_new) # объединить прогнозы в единый массив комбинированный = hstack ((yhat1, yhat2)) # рассчитать результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1)
1 2 3 4 5 6 7 8 9 10 11 12 13 140004 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 48 51 52 | # ансамбль старой нейронной сети с новой моделью, подходящей для старых и новых данных из numpy import hstack из numpy import vstack из numpy import mean из sklearn.наборы данных импортировать make_classification из sklearn.model_selection import train_test_split из tensorflow.keras.models import Sequential из tensorflow.keras.layers import Dense из tensorflow.keras.optimizers 9000 , dataset, импортировать SG4D, dataset SG4D y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1)# записать количество входных функций в данные n_features = X.shape [1] # разделить на старые и новые данные X_old, X_new, y_old, y_new = train_test_split (X, y, test_size = 0.50, random_state = 1) # определить старую модель old_model = Sequential ( ) old_model.add (Dense (20, kernel_initializer = ‘he_normal’, activate = ‘relu’, input_dim = n_features)) old_model.add (Dense (10, kernel_initializer = ‘he_normal’, activate = ‘relu’) ) old_model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (learning_rate = 0.01, импульс = 0,9) # скомпилировать модель old_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # подогнать модель по старым данным old_model.fit (X_old, y_old, epochs = 150 , batch_size = 32, verbose = 0) # сохранить модель … # загрузить модель … # определить новую модель new_model = Sequential () new_model.add (Плотный (20, kernel_initializer = ‘he_normal’, Activation = ‘relu’, input_dim = n_features)) новая_модель.add (Dense (10, kernel_initializer = ‘he_normal’, Activation = ‘relu’)) new_model.add (Dense (1, activate = ‘sigmoid’)) # определить алгоритм оптимизации opt = SGD (Learning_rate = 0,01, импульс = 0,9) # скомпилировать модель new_model.compile (optimizer = opt, loss = ‘binary_crossentropy’) # создать составной набор старых и новых данных X_both, y_both = vstack (( X_old, X_new)), hstack ((y_old, y_new)) # соответствует модели на старых данных new_model.fit (X_both, y_both, epochs = 150, batch_size = 32, verbose = 0) # сделать прогнозы с обеими моделями yhat1 = old_model.predict (X_new) yhat2 = new_model_ # объединить прогнозы в один массив комбинированный = hstack ((yhat1, yhat2)) # вычислить результат как среднее значение прогнозов yhat = среднее (объединенное, ось = -1) |
Дополнительная литература
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться.
Учебники
Сводка
В этом руководстве вы узнали, как обновлять модели нейронных сетей с глубоким обучением в ответ на новые данные.
В частности, вы выучили:
- Возможно, потребуется обновить модели нейронных сетей при изменении базовых данных или при появлении новых помеченных данных.
- Как обновить обученные модели нейронной сети только новыми данными или комбинациями старых и новых данных.
- Как создать ансамбль существующих и новых моделей, обученных только новым данным или комбинациям старых и новых данных.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разрабатывайте проекты глубокого обучения с помощью Python!
Что, если бы вы могли разработать сеть за считанные минуты
… всего несколькими строками Python
Узнайте, как в моей новой электронной книге:
Deep Learning With Python
Он охватывает сквозных проектов по таким темам, как:
Многослойные персептроны , Сверточные сети и Рекуррентные нейронные сети и другие…
Наконец-то привнесите глубокое обучение в
Ваши собственные проекты
Пропустить академики. Только результаты.
Посмотрите, что внутриПочему вневременная проверка не стала более повсеместной?
Обучайте, проверяйте и тестируйте разделы на предмет несвоевременной производительности с учетом планирования и размышлений
(Эта часть также находится в TDS.) Цель машинного обучения с учителем — классифицировать немаркированные данные. Мы хотим, чтобы алгоритмы сообщали нам, совершит ли заемщик дефолт, покупатель совершит покупку, изображение содержит кошку, собаку, злокачественную опухоль или доброкачественный полип.Алгоритмы «учатся» делать эти классификации, используя маркированные данные, то есть данные, в которых мы знаем, действительно ли заемщик выполнил свои обязательства, совершил ли покупатель покупку и что на самом деле показывает блок пикселей. Обычно исследователи берут помеченные данные и разделяют их на три части: обучение, проверка и тестирование / задержка (терминология иногда отличается). Они обучают сотни моделей на данных поезда и выбирают одну модель, которая хорошо работает с данными проверки. Причина использования только подмножества помеченных данных для обучения алгоритма состоит в том, чтобы убедиться, что алгоритмы хорошо работают на любых данных , а не только на данных, используемых для обучения алгоритма.Исследователи часто повторяют этот шаг несколько раз, выбирая разные разбиения на обучение и проверку, чтобы убедиться, что производительность модели не зависит от конкретных данных проверки (k-кратная перекрестная проверка). В качестве последнего шага исследователи оценивают производительность модели на еще невидимых данных (тестовый набор). Это дает меру того, насколько хорошо модель будет работать с немаркированными данными. Эта классическая установка проиллюстрирована на рисунке ниже:
Рис. 1. Классическая поездка, проверка и разделение тестов
Выберите модель, которая хорошо работает на «проверке»
Оцените ее производительность на «испытании»
.
В большом количестве приложений данные имеют временное измерение, так что помеченные данные — это прошлое, а немаркированные данные — будущее. Например, мы уже знаем, какие заемщики или клиенты не выполнили свои обязательства или совершили покупку в прошлом. Мы хотим знать, кто из них сделает это в будущем. В этом случае цель алгоритма состоит в том, чтобы спрогнозировать метку заранее. Это означает, что он должен работать не только со вчерашними, но и с завтрашними данными. Я спрашиваю, как измерение времени должно быть включено в классическую настройку поезда / проверки / тестирования.Это, безусловно, будет иметь значение, если процессы меняются со временем. Оказывается, есть целое подразделение, занимающееся этими вопросами. Подходы варьируются от настройки скользящего окна над обучающими данными до активного тестирования изменений в лежащих в основе отношений. В этом посте я рассмотрю несколько вариантов настройки данных поезда, проверки и тестирования.Вариант 1: своевременная проверка, своевременная проверка
Давайте посмотрим, что произойдет, если мы проигнорируем временное измерение данных и разделим все помеченные данные независимо от их временного измерения.Мы обучаем, проверяем и тестируем модель, используя данные из за тот же период времени . Мы делаем прогнозы для новых данных (скажем, на 2019 год), используя модель, обученную, проверенную и протестированную на помеченных данных за 2015–2018 годы. Рисунок ниже иллюстрирует эту настройку. Преимущество состоит в том, что мы используем самые свежие данные для обучения модели. Недостатком является то, что он предполагает, что отношения, существовавшие в прошлом, останутся такими же в будущем. Если отношения меняются со временем, наши оценочные показатели эффективности (которые мы рассчитали с использованием временных данных теста ) будут на превысить истинную производительность модели, т. Е.е. после развертывания модель будет работать хуже, чем мы ожидали.
Вариант 2: своевременная проверка, вневременная проверка
Другая возможность состоит в том, что мы продержимся в 2018 году, обучим модель, используя данные за 2015-2017 годы, и протестируем ее на данных 2018 года. Преимущество этого подхода в том, что мы явно оцениваем способность модели прогнозировать несвоевременность. Недостаток — возможность прогнозирования вне времени не учитывается при построении модели. Это связано с тем, что мы выбираем модель, которая хорошо работает с данными своевременной проверки .Более того, если мы не переобучаем модель с использованием полных данных за 2015–2018 годы, мы не будем использовать самые последние данные для прогнозов.
Вариант 3: «шаг вперед»
Роджер Штайн предлагает модели обучения на последовательных (потенциально скользящих) окнах данных и делать прогнозы на следующий период времени. Каждый раз мы переобучаем модель, используя все наблюдения за определенный момент времени, и делаем прогнозы на следующий период времени. Прогнозы из каждого окна объединяются в один набор прогнозов.Мы делаем это для множества разных моделей и выбираем ту, которая дает наилучшие комбинированные прогнозы. Преимущество этого подхода заключается в том, что при построении модели (т. Е. Проверке того, какие модели работают лучше всего) явно учитывается способность модели делать несвоевременные прогнозы. Поскольку модель переоборудована для каждого окна, этот подход имитирует периодическое переобучение модели, которое происходит (или должно произойти) на практике. Недостатком подхода является то, что мы всегда проверяем прогнозы на одном и том же наборе данных, а не на случайно выбранных данных.(Возможно, предоставление части тестовых данных могло бы решить эту проблему.)Переучивать или не переучивать
Когда мы делаем прогнозы на будущее, вероятно, будет хорошей идеей использовать как можно более свежие данные, чтобы зафиксировать самые недавние явления. Однако, если мы храним самые свежие данные (для оценки несвоевременной производительности), как в варианте 2, нам, вероятно, следует повторно обучить модель, используя все помеченные данные, прежде чем делать прогнозы. Переобучение показано на рисунке ниже:
.
В сети есть некоторые разногласия по поводу необходимости повторного обучения модели с использованием всех данных обучения и тестирования перед развертыванием. Кун и Джонсон кажутся довольно ясными, когда в главе о чрезмерной подгонке, разделении данных и настройке модели они говорят: «Затем мы строим окончательную модель со всеми обучающими данными, используя выбранные параметры настройки». (стр.65). Точно так же Эндрю Нг в одной из своих лекций говорит, что после выбора модели из процедуры перекрестной проверки мы можем «опционально» переобучить модель «на всем обучающем наборе.”.
Полезно провести различие между параметрами модели и гиперпараметрами (также известными как параметры настройки). Гиперпараметры определяют структуру модели и, как правило, не могут быть оценены на основе данных. Они включают такие вещи, как сложность дерева, k в алгоритме KNN, набор функций, функциональная форма (например, линейная или квадратичная) и т. Д. Напротив, параметры модели включают коэффициенты в регрессии, правила дерева, опорные векторы. Их можно оценить с помощью данных.Этап построения модели — это поиск гиперпараметров. После того, как гиперпараметры (то есть структура модели) подтверждены, кажется, мало причин не использовать как можно больше данных для получения наиболее точных оценок параметров модели. Эти параметры следует использовать для развертывания модели и выполнения классификаций или прогнозов.Заключение
Таким образом, если мы последуем классической настройке и проигнорируем временное измерение наших данных, как в варианте 1, мы понятия не имеем, как модель будет работать с несвоевременными данными.В варианте 2 у нас, по крайней мере, есть оценка несвоевременной производительности модели. Однако только если мы сделаем что-то вроде варианта 3, мы будем строить модели с намерением прогнозировать будущее. Независимо от того, что мы делаем, переобучение модели с использованием всех помеченных данных перед тем, как делать прогнозы, кажется хорошей идеей.
.
Мне сложно найти примеры приложений, в которых нет измерения времени. Я полагаю, что груда изображений МРТ, из которых только некоторые были помечены, является одним из примеров, но я считаю, что эти разовые проекты редки.Более того, хотя некоторые процессы стабильны во времени (например, классификация погоды или изображений — собака сегодня будет выглядеть так же, как собака завтра), такие процессы, как поведение клиентов, неизбежно изменятся со временем. Поэтому удивительно, что обсуждения (и реализация) вневременного тестирования и валидации не стали более повсеместными. Скорее всего, несвоевременная производительность хуже, чем своевременная, особенно если у вас много данных с метками во времени, не очень длинные временные ряды и нестационарный процесс.Однако отказ от проведения какой-либо оценки вне времени может беспокоить разработчиков, поскольку последующие данные покажут, что модель работает хуже, чем указанные своевременные показатели производительности.
Автоматическая переподготовка моделей с помощью конвейеров Kubeflow | Карл Вайнмайстер | kubeflow
Как реализовать воспроизводимый рабочий процесс машинного обучения, который адаптируется к новым данным
Как говорится, «единственная константа — это изменение». Когда мы строим модели машинного обучения, мы прогнозируем значения на основе данных, собранных в определенный момент времени.Со временем картина, которую видит модель, может стать более нечеткой по мере изменения условий.
Один из способов справиться с этой ситуацией — переобучить модель при значительных изменениях в данных. Хотя это может быть полезно, ручная переподготовка увеличивает накладные расходы, ее можно проводить в произвольное время или просто забыть. Автоматическая переподготовка моделей может помочь обеспечить переподготовку моделей с использованием последних доступных данных на основе заданной частоты или других условий.
Мы рассмотрим, как реализовать автоматическое переобучение модели с помощью компонента Pipelines в Kubeflow.Kubeflow — это платформа машинного обучения, работающая на популярной системе оркестровки контейнеров Kubernetes.
Мы будем использовать образец, демонстрирующий, как создать простой конвейер Kubeflow с использованием стандартных компонентов AI Platform.
Модель предсказывает количество сообщений о преступлениях, ожидаемых сегодня, с учетом ежедневных итогов за предыдущую неделю. Он использует данные о преступности Чикаго, которые общедоступны в BigQuery, и включает отчеты о преступлениях в Чикаго с 2001 года по настоящее время.
Для начала вам понадобится кластер Kubeflow.Вы можете настроить его на Google Cloud Platform (GCP) с помощью приложения для развертывания. На веб-сайте Kubeflow есть инструкции для многих сред, включая локальную среду. Вам также потребуется клонировать репозиторий Github, содержащий образец.
После настройки среды перейдите на домашнюю страницу Kubeflow в своем кластере, а затем перейдите на страницу записных книжек. Оттуда создайте сервер записной книжки и загрузите обе записной книжки в образце на сервер записной книжки.
Аналитическая записная книжка показывает, как работает модель.Модель использует тип рекуррентной нейронной сети (RNN), называемый долгосрочной краткосрочной памятью (LSTM). Рекуррентные нейронные сети могут прогнозировать последовательность входных данных, а архитектура LSTM предоставляет компонент «памяти», который может улучшить производительность модели. Модель реализована с помощью TensorFlow с использованием класса Keras LSTM.
В записной книжке проходят этапы создания модели, ее обучения и визуализации выходных данных. На приведенном ниже графике оранжевая линия показывает синим цветом прогнозы модели, наложенные на фактические значения.
Визуализация исторических отчетов о преступлениях вместе с прогнозируемыми значениямиТеперь, когда мы рассмотрели модель, давайте создадим конвейер, который будет загружать входные данные, обучать модель и развертывать ее программно.
В частности, конвейер будет состоять из трех задач:
- Запросить исторических отчетов о преступлениях из BigQuery и сохранить как CSV в корзину Google Cloud Storage.
- Обучите модель с помощью службы обучения AI Platform.
- Разверните модель в службе прогнозирования платформы AI.
Дополнительную информацию о том, как работает Kubeflow Pipelines, можно найти в документации, а вот краткое введение. Конвейер определяется на доменно-специфическом языке (DSL) на основе Python, который описывает его этапы. Затем код DSL необходимо скомпилировать в промежуточный формат с помощью Pipelines SDK, чтобы его можно было использовать в механизме рабочего процесса Kubeflow Pipelines.
Каждая задача в конвейере будет выполняться в собственном контейнере Docker.Вы можете реализовать каждую задачу с помощью специального кода или использовать стандартные компоненты. В этом примере мы будем использовать компоненты GCP AI Platform для каждой задачи в конвейере.
Для начала вам потребуется создать проект Google Cloud Platform, если у вас его еще нет. Чтобы сохранить активы модели, вам нужно будет создать корзину Google Cloud Storage в своем проекте.
Теперь построим и запустим конвейер. В записной книжке конвейера начните с обновления необходимых параметров в разделе Константы, чтобы они соответствовали вашей среде.Теперь вы можете запускать каждый шаг в записной книжке. На последнем шаге вы получите ссылку на запуск для просмотра конвейера в пользовательском интерфейсе Kubeflow Pipelines.
Код определения конвейера компилируется в визуальный рабочий процесс. Затем мы добавим этот конвейер в библиотеку конвейеров. Первый шаг — загрузить конвейер chicago.pipeline.tar.gz из службы Jupyter Notebook. Этот файл конвейера был создан, когда SDK скомпилировал конвейер.
Давайте загрузим этот файл конвейера на вкладке «Конвейеры» в пользовательском интерфейсе Kubeflow Pipelines.Назовем его «Чикагский криминальный трубопровод».
Загрузите конвейер, чтобы начать процессТеперь мы настроим повторяющийся запуск с только что созданным конвейером. Также можно запустить повторное обучение из внешней службы обработки событий, например, когда данные значительно изменились или выросли. При повторном запуске следует учитывать скорость изменения данных. Это должно происходить достаточно часто, избегая при этом ненужной переподготовки.
Переходим на вкладку «Эксперименты» и находим эксперимент, созданный вами в записной книжке конвейера.Щелкните эксперимент и создайте новый «Повторяющийся запуск». На этой странице вы можете выбрать «Chicago Crime Pipeline» и указать частоту переобучения. Параметр периодичности предназначен для планирования запусков на основе интервалов (например, каждые 2 недели), а параметр cron предоставляет аналогичные функции, но принимает семантику cron для определения расписания.
Задание поддерживает общие параметры, определенные в конвейере. Эти параметры позволяют вам запускать разные перестановки вашего конвейера, например, с разными гиперпараметрами или другой версией TensorFlow, которые согласованы и отслеживаются.Пример конвейера предоставляет значения по умолчанию для каждого параметра, чтобы можно было легко запускать задания.
Задайте параметры конвейера, включая частоту его выполнения.Теперь вы создали повторяющийся запуск! Каждый раз, когда конвейер выполняется, он будет развертывать новую версию модели в том же месте, созданном с использованием согласованной среды.
Теперь вы можете видеть подробную информацию о каждом запуске на панели мониторинга конвейеров. В зависимости от того, как вы настроили свой проект, вы можете получить доступ к статистике точности модели в пользовательском интерфейсе или в TensorBoard для каждого запуска.
Каждый цикл конвейера можно просмотреть в пользовательском интерфейсе Kubeflow Pipelines.Наша модель прогнозирования преступности в Чикаго иллюстрирует типичный сценарий, который выиграет от переобучения модели. Мы показали, как создать трехэтапный конвейер, который загружает последние данные, повторно обучает модель и автоматически развертывает модель. Наконец, мы показали, как настроить этот конвейер для работы в повторяющемся интервале с помощью Kubeflow Pipelines.
Я надеюсь, что эта статья показывает, что создание повторяемого рабочего процесса машинного обучения практично и доступно.Хотя мы продемонстрировали переобучение модели на GCP, любой произвольный процесс в любом кластере Kubernetes можно настроить в Kubeflow Pipelines. Мы надеемся, что Kubeflow поможет обеспечить воспроизводимость и отслеживание ваших экспериментов машинного обучения!
Основа для успешной стратегии непрерывного обучения
Фото Моники Пейковской на Unsplash
Модели машинного обучения построены на предположении, что данные, используемые в производстве, будут аналогичны данным, которые наблюдались в прошлом. на котором мы обучили наши модели.Хотя это может быть верно для некоторых конкретных случаев использования, большинство моделей работают в динамических средах данных, где данные постоянно меняются и где возможны «дрейфы концепций», которые отрицательно влияют на точность и надежность моделей.
Чтобы справиться с этим, модели машинного обучения необходимо регулярно переобучать. Или, как указано в Google, «MLOps: конвейеры непрерывной доставки и автоматизации в машинном обучении»: « Чтобы решить эти проблемы и поддерживать точность вашей модели в производстве, вам необходимо сделать следующее: Активно контролировать качество вашей модели в производстве. […] и часто переобучайте свои серийные модели. »Эта концепция называется« Continuous Training » (CT) и является частью практики MLOps. Непрерывное обучение направлено на автоматическое и непрерывное переобучение модели для адаптации к изменениям, которые могут произойти в данных.
Существуют разные подходы / методики проведения непрерывной переподготовки, каждый из которых имеет свои плюсы, минусы и затраты. Тем не менее, как и сапожник, который ходит босиком, мы, специалисты по обработке данных, перебарщиваем с переобучением, иногда вручную, и часто используем его как «стандартное» решение. , не имея достаточной информации, связанной с производством.
Каждый вариант использования машинного обучения имеет свои собственные динамические среды данных, которые могут вызвать смещение концепций: от торговли в реальном времени к обнаружению мошенничества с злоумышленником, изменяющим распределение данных, или механизмам рекомендаций с множеством новых фильмов и новых тенденций. Тем не менее, независимо от варианта использования, при разработке стратегии непрерывного обучения необходимо решить три основных вопроса:
1 — Когда следует переобучать модель? Поскольку цель состоит в том, чтобы поддерживать актуальные и оптимальные модели в любой момент времени, как часто следует переобучать модель
2 — Какие данные следует использовать? Общее предположение для выбора адекватного набора данных состоит в том, что актуальность данных коррелирует с их недавним возрастом, что вызывает ряд вопросов: должны ли мы просто использовать новые данные или добавлять к более старым наборам данных? Каков хороший баланс между старыми и новыми данными? Насколько недавние данные считаются новыми или когда происходит разрыв между старыми и новыми данными?
3 — Что нужно переквалифицировать? Можем ли мы просто заменить данные и заново обучить ту же модель с теми же гиперпараметрами? Или нам следует использовать более навязчивый подход и запустить полный конвейер, имитирующий наш исследовательский процесс?
На каждый из трех приведенных выше вопросов можно ответить по отдельности, и это может помочь определить оптимальную стратегию для каждого случая.Тем не менее, при ответе на эти вопросы есть список соображений, которые необходимо принять во внимание и которые мы исследовали здесь. Для каждого вопроса мы описываем разные подходы, соответствующие разным уровням автоматизации и зрелости процесса машинного обучения.
Когда переквалифицироваться?
Три наиболее распространенных стратегии: периодическая переподготовка, производительность на основе или на основе изменений данных.
Периодическая переподготовка
График периодической переподготовки — самый наивный и простой подход.Обычно это зависит от времени: модель переобучается каждые 3 месяца, но также может зависеть от объема, то есть для каждых 100 тысяч новых этикеток.
Преимущества периодической переподготовки столь же очевидны: это очень интуитивно понятный и управляемый подход, поскольку легко узнать, когда произойдет следующая итерация переподготовки, и легко реализовать .
Однако этот метод часто оказывается плохо приспособленным или неэффективным. Как часто вы переобучаете модель? Каждый день? Каждую неделю? Каждые три месяца? Раз в год? Хотя кто-то хочет частого переобучения для обновления наших моделей, переобучение модели слишком часто, когда нет реальной причины, т.е. нет дрейфа концепций, это дорого. Кроме того, даже когда переподготовка автоматизирована, для этого требуются важные ресурсы — как вычислительные, так и от ваших групп по анализу данных, которым необходимо контролировать процесс переподготовки и поведение новой модели в производственной среде после развертывания. Тем не менее, переподготовка с большими интервалами может упустить момент непрерывного переобучения и не сможет адаптироваться к изменениям данных, не говоря уже о рисках переобучения на зашумленных данных.
В конце концов, график периодической переподготовки имеет смысл, если частота соответствует динамике вашего домена.В противном случае выбор случайного времени / вехи может подвергнуть вас риску и оставить вам модели, которые имеют меньшую актуальность, чем их предыдущая версия.
Триггер на основе производительности
Это почти здравый смысл, основанный на старой доброй инженерной пословице: «Если он не сломан, не чините его». Второй наиболее распространенный подход к определению момента переобучения — использование триггеров, основанных на производительности, и переобучение модели после обнаружения снижения производительности.
Этот подход, более эмпирический, чем первый, предполагает, что у вас есть непрерывное представление о производительности ваших моделей в производстве.
Основное ограничение, когда речь идет только о производительности, — это время, необходимое вам, чтобы получить достоверную информацию — если вы ее получите вообще. В случаях прогнозирования конверсии пользователей может потребоваться 30 или 60 дней, пока вы не получите достоверную информацию, или даже 6 месяцев или более в таких случаях, как обнаружение мошенничества с транзакциями или LTV. Если вам нужно ждать так долго, чтобы получить полную обратную связь, это означает, что вы слишком поздно переобучаете модель, после того как бизнес уже пострадал.
Еще один нетривиальный вопрос, на который необходимо ответить: что считается «ухудшением производительности»? вы можете зависеть от чувствительности ваших пороговых значений и точности калибровки, что может привести к слишком частой или недостаточной переобучению.
В целом, использование триггеров, основанных на производительности, хорошо для случаев использования, когда есть быстрая обратная связь и большой объем данных, например, назначение ставок в реальном времени, когда вы можете измерить производительность модели как можно ближе к времени прогнозов за короткие промежутки времени и с высокой достоверностью (большой объем).
Управляемый изменениями данных
Этот подход является наиболее динамичным и естественным образом запускает переобучение из динамизма домена.Измеряя изменения во входных данных, то есть изменения в распределении функций, используемых моделью, вы можете обнаружить отклонения данных, которые указывают на то, что ваша модель может быть устаревшей и ее необходимо сохранить на свежих данных.
Это альтернатива подходу, основанному на производительности, для случаев, когда у вас нет быстрой обратной связи или вы не можете оценить производительность модели в процессе производства в режиме реального времени. Кроме того, рекомендуется комбинировать и использовать этот подход даже при быстрой обратной связи, поскольку это может указывать на неоптимальную производительность даже без ухудшения качества. Понимание изменений данных для начала процесса переподготовки очень важно, особенно в динамических средах.
На приведенном выше графике, созданном службой мониторинга, показаны метрика дрейфа данных (верхний график) и КПЭ (нижний график) для маркетингового сценария использования. График дрейфа данных представляет собой временную шкалу, на которой ось Y показывает уровень дрейфа для каждого дня (т. Е. Данные за этот день) относительно обучающей выборки.В этом примере маркетингового использования новые кампании вводятся очень часто, и бизнес расширяется в новые страны. Очевидно, что потоки данных в производственной среде дрейфуют и становятся менее похожими на данные, на которых была обучена модель. Имея более полное представление о модели в производственной среде, итерация переобучения могла быть запущена задолго до того, как бизнес заметил бы снижение производительности.
Итак, когда переучиваться? Это зависит от таких ключевых факторов, как: доступность ваших отзывов, объем ваших данных и ваше видение эффективности ваших моделей.В целом, не существует единого подхода к вопросу о выборе подходящего времени для переобучения. Скорее, и в зависимости от ваших ресурсов, цель должна заключаться в том, чтобы максимально ориентироваться на производство.
Какие данные следует использовать?
Хотя мы видели, что время — это все (то есть: когда мне переобучать свои модели?), Теперь давайте посмотрим на нерв всех MLOps: данные. Как при переподготовке выбрать правильные данные для использования?
Фиксировать размер окна
Самый наивный подход — использовать фиксированный размер окна в качестве обучающего набора.Например, используйте данные за последние X месяцев. Ясно, что преимущество метода заключается в его простоте, поскольку он очень прямолинеен.
Недостатки связаны с проблемой выбора правильного окна: если оно слишком широкое, оно может пропустить новые тенденции, а если оно слишком узкое, оно будет перегружено и шумно. При выборе размера окна следует также учитывать частоту переобучения: нет смысла переобучаться каждые 3 месяца, если вы используете только данные за последний месяц в качестве обучающей выборки.
Кроме того, выбранные данные могут сильно отличаться от данных, которые передаются в производственной среде, так как это может произойти сразу после точки изменения (в случае быстрого / внезапного изменения) или может содержать нерегулярные события (например, праздники или специальные дни, такие как день выборов), проблемы с данными и многое другое.
В целом подход окна исправлений, как и любой другой «статический» метод, представляет собой простую эвристику, которая может хорошо работать в некоторых случаях, но не сможет уловить гипердинамичность вашей среды в тех случаях, когда скорость изменения универсален, а нерегулярные события — обычное дело, например, праздники или технические проблемы.
Размер динамического окна
Подход с динамическим размером окна пытается решить некоторые ограничения предопределенного размера окна, определяя, сколько исторических данных должно быть включено в более управляемый данными способ и обрабатывая окно размер как еще один гиперпараметр, который можно оптимизировать в рамках переобучения.
Этот подход больше всего подходит для случаев, когда есть быстрая обратная связь (т. Е. Торги в реальном времени или доставка еды и т. Д.).Наиболее релевантные данные могут использоваться в качестве тестового набора, и размер окна может быть оптимизирован на нем, как и другой гиперпараметр модели. В случае, показанном ниже, наивысшая производительность достигается за последние 3 недели, которые это то, что следует выбрать для этой итерации. Для будущих можно выбрать другое окно согласно сравнению с тестовым набором.
Преимущество подхода с динамическим размером окна состоит в том, что он в большей степени управляется данными, основывается на производительности модели, которая на самом деле является итоговой строкой, и, следовательно, он более надежен для сред с высокой временной скоростью.
Недостатком является то, что требуется более сложный конвейер обучения (см. Следующий вопрос «Что обучать») для тестирования различных размеров окна и выбора оптимального, а это требует гораздо больших вычислительных ресурсов. Кроме того, как и при фиксированном размере окна, предполагается, что наиболее актуальны самые свежие данные, что не всегда верно.
Динамический выбор данных
Третий подход к выбору данных для обучения моделей направлен на достижение основной цели любой стратегии переподготовки и является основным допущением любой модели машинного обучения: использование обучающих данных, аналогичных производственным данные.Другими словами, модели следует переобучать на данных, которые максимально похожи на данные, используемые в реальной жизни для составления прогнозов. Этот подход сложен и требует высокой прозрачности производственных данных.
Для этого вам необходимо провести тщательный анализ эволюции данных в производственной среде, чтобы понять, меняются ли они с течением времени и как. Один из способов сделать это — вычислить дрейф входных данных между каждой парой дней, то есть насколько данные одного дня отличаются от данных другого дня, и создать тепловую карту, которая выявляет закономерности изменения данных в течение время, как показано ниже.Тепловая карта ниже представляет собой визуализацию оценки дрейфа во времени, где оси (столбцы и строки) — это даты, а каждая точка (ячейка в матрице) представляет собой уровень дрейфа между двумя днями, где чем выше дрейф, тем больше красный цвет ячейка есть.
Superwise Data DNA viewВыше вы можете увидеть результат такого анализа, автоматически сгенерированного superwise.ai, чтобы помочь определить данные, максимально похожие на те, которые сейчас передаются в потоковом режиме. Существуют различные типы идей, которые можно легко получить из этого представления:
1 — Декабрь сильно отличается от остальных данных (до и после).Это понимание позволяет нам не рассматривать весь период как группу и исключать те дни, когда вы хотите переобучиться, поскольку данные за этот месяц не соответствуют обычным данным, которые вы наблюдаете в производственной среде.
2- Сезонность данных может быть визуализирована — и это может вызвать дискуссию о необходимости использования разных моделей для будних и выходных дней.
Еще одна очень важная вещь: вы действительно можете получить изображение, доказывающее, что самые свежие данные не обязательно самые актуальные.
Короче говоря, выбор правильных данных для переобучения моделей требует тщательного анализа поведения данных в производственной среде. Хотя использование исправлений или динамических размеров окна может помочь вам «поставить галочку», обычно это остается предположением, которое может оказаться более затратным, чем эффективным.
Что нужно переквалифицировать?
Теперь, когда мы проанализировали, когда переобучаться и какие данные следует использовать, давайте обратимся к третьему вопросу: что следует переобучать? Можно было выбрать только переобучение (переоборудование) экземпляра модели на основе новых данных, включение некоторых или всех этапов подготовки данных или использование более навязчивого подхода и запуск полного конвейера, имитирующего процесс исследования.
Основное предположение при переподготовке состоит в том, что модель, которая была обучена на этапе исследования, устареет из-за дрейфа концепции и, следовательно, ее необходимо переобучить. Однако в большинстве случаев экземпляр модели — это всего лишь последний этап более широкого конвейера, который был построен на этапе исследования и включает этапы подготовки данных. Возникает вопрос: насколько серьезен дрейф и его влияние? или в контексте переподготовки какие части модельного конвейера следует оспорить?
На этапе исследования вы экспериментируете и оцениваете многие элементы на этапах конвейера модели, чтобы оптимизировать вашу модель.Эти элементы можно сгруппировать в две части высокого уровня: подготовку данных и обучение модели. Часть подготовки данных, отвечающая за подготовку данных (да!) Для использования в модели, включает такие методы, как проектирование функций, масштабирование, вменение, уменьшение размеров и т. Д., А также часть обучения модели, отвечающую за выбор оптимальной модели и ее гиперпараметров. . В конце процесса вы получаете конвейер последовательных шагов, которые берут данные, подготавливают их для использования в модели и прогнозируют целевой результат с помощью модели.
Переобучение только модели, то есть последнего шага в конвейере, с новыми релевантными данными — самый простой и наивный подход, которого может хватить, чтобы избежать снижения производительности. Однако в некоторых случаях этого подхода, основанного только на модели, может быть недостаточно, и следует применять более комплексный подход в отношении объема переподготовки. Расширение объема переподготовки можно проводить по двум направлениям:
1 — На что переквалифицироваться? Какие части конвейера следует переобучить с использованием новых данных?
2 — Уровень переподготовки: Вы просто переобучаете модель (или другие шаги) с новыми данными? Вы занимаетесь оптимизацией гиперпараметров? или вы оспариваете выбор самой модели и тестируете другие типы моделей?
Другой способ взглянуть на это заключается в том, что в процессе переподготовки вы в основном пытаетесь автоматизировать и избегать ручной работы по исследованию оптимизации модели, которая была бы выполнена специалистом по данным, если бы не было процесса автоматической переподготовки.Следовательно, вам необходимо решить, в какой степени вы хотите имитировать процесс ручного исследования, как показано в таблице ниже.
Обратите внимание, что автоматизация первых шагов потока становится более сложной, и чем больше автоматизации строится вокруг этих экспериментов, тем больше процесс более надежный и гибкий, чтобы адаптироваться к изменениям, но он также добавляет сложности, поскольку следует рассматривать больше конечных случаев и проверок. группа по науке о данных для некоторой задачи классификации:
Вы можете воспользоваться простым подходом и просто переобучить саму модель и позволить ей изучить новое дерево, или вы можете включить некоторые (или все) этапы подготовки данных (например,г. повторно запомните среднее значение в импутере или минимальное / максимальное значения в скалере). Но помимо выбора ступеней для переобучения нужно определиться, до какого уровня. Например, даже если вы решите переобучить только модель, это может быть выполнено на нескольких уровнях. Вы можете просто переобучить саму модель и позволить ей изучить новое дерево, например, model.fit (new_X, new_y), или вы можете выполнить поиск и оптимизировать гиперпараметры модели (максимальная глубина, минимальный размер листа, максимальное количество листовых узлов и т. Д.) или даже оспорить выбор самой модели и протестировать другие типы моделей (например,г. логистическая регрессия и. случайный лес). Этапы подготовки данных могут (и должны) также быть переобучены, чтобы тестировать различные скейлеры или разные методы вменения или даже тестировать выбор различных характеристик.
При выборе более комплексного подхода и выполнения гиперпараметрической оптимизации / поиска модели вы также можете использовать фреймворки Auto-ML, которые предназначены для автоматизации процесса построения и оптимизации конвейера модели, включая подготовку данных, поиск модели и оптимизация гиперпараметров.И это не обязательно требует сложного метаобучения. Это может быть просто: пользователь выбирает ряд моделей и параметров. Доступно множество инструментов: AutoKeras, Auto SciKitLearn. Тем не менее, каким бы заманчивым ни был AutoML, он не освобождает пользователя от наличия надежного процесса отслеживания, измерения и мониторинга моделей на протяжении всего их жизненного цикла, особенно до и после их развертывания в производственной среде.
В конце концов, «переключение переключателя» и автоматизация ваших процессов должны сопровождаться надежными процессами, чтобы гарантировать, что вы по-прежнему контролируете свои данные и свои модели.
Чтобы добиться эффективного непрерывного обучения, вы должны уметь руководить, опираясь на производственную информацию. Для любого варианта использования создание надежной инфраструктуры машинного обучения в значительной степени зависит от способности обеспечить видимость и контроль над работоспособностью ваших моделей и работоспособностью ваших данных в производственной среде. Вот что значит быть специалистом по данным;)
Требования к обучению HIPAA
Каковы требования к обучению HIPAA?
Поскольку HIPAA применяется ко многим различным типам защищаемых организаций (CE) и бизнес-партнеров (BA), требования к обучению HIPAA лучше всего охарактеризовать как «гибкие».Обучение, несомненно, является обязательным, поскольку оно является административным требованием правила конфиденциальности HIPAA (45 CFR §164.530) и административной защитой правила безопасности HIPAA (45 CFR §164.308).
Тем не менее, помимо оговоренных требований, обучение должно предоставляться «по мере необходимости и целесообразности для членов персонала для выполнения своих функций» (Правило конфиденциальности HIPAA), и что CE и BA должны «внедрить программу обучения и повышения осведомленности о безопасности для всех членов персонала. рабочая сила »(правило безопасности HIPAA), подробный список требований к обучению HIPAA отсутствует.
Рассмотрите цели обучения HIPAA
Осознание того, что вы должны проводить обучение, но незнание того, какой тип обучения вы должны проводить, усложняет соблюдение требований HIPAA. Конечно, если произойдет нарушение PHI и последующее расследование обнаружит, что обучение не проводилось, ответственный CE или BA может ожидать существенного штрафа от Управления по гражданским правам HHS. Организации, которые проводят регулярное обучение HIPAA, гораздо реже получают штраф HIPAA.
Чтобы преодолеть гибкость требований к обучению HIPAA, CE и BA должны вернуться к своим оценкам рисков. При оценке рисков должна быть определена функция каждого человека, который может контактировать с PHI или ePHI, и на основе этих данных должна быть возможность составить «необходимую и уместную» программу обучения и осведомленности в области безопасности для каждой функции или роли.
Что должно быть включено в программу обучения и осведомленности о безопасности, будет зависеть от функций или роли каждого отдельного сотрудника, менеджера, волонтера, стажера или подрядчика, который может контактировать с PHI или ePHI.Во многих случаях потребуется составить несколько программ обучения и повышения осведомленности о безопасности, чтобы убедиться, что их содержание актуально для обучаемых. Например, медицинские работники не нуждаются в таком же обучении, как специалист по соблюдению требований HIPAA. Студенты-медики нуждаются в несколько ином обучении, чем медицинские работники. Руководители здравоохранения снова нуждаются в несколько ином обучении.
Это может потребовать много времени и ресурсов для проведения целевого обучения; но для того, чтобы обучение было эффективным, оно должно быть целенаправленным.
Как часто требуется обучение HIPAA?
Что касается вопроса о том, как часто требуется обучение HIPAA, Правило конфиденциальности и Правило безопасности предлагают предложения без указания конкретных сроков. Согласно Правилу конфиденциальности, обучение HIPAA требуется для «каждого нового сотрудника в течение разумного периода времени после того, как это лицо присоединится к персоналу Защищенной организации», а также когда «функции затронуты существенным изменением политики или процедур» — снова в разумные сроки.Это интерпретируется как необходимость обучения в первые несколько дней или недель, а не месяцев.
Согласно Правилу безопасности, обучение HIPAA требуется «периодически». Большинство поставщиков медицинских услуг интерпретируют «периодически» как ежегодно, поскольку более длительный период, скажем, каждые два или три года, будет означать халатное отношение к обучению в случае расследования нарушения HHS. Рекомендуется ежегодно проводить переподготовку по HIPAA, но рассмотрите возможность более частого проведения более коротких учебных занятий, чтобы усилить необходимость соблюдения требований и снизить риск случайных нарушений HIPAA.
ОбучениеHIPAA также должно проводиться всякий раз, когда происходят изменения в методах работы или технологиях, или когда Министерство здравоохранения и социальных служб издает новые правила или руководства. Чтобы определить, требуется ли обучение HIPAA, сотрудники по вопросам конфиденциальности и безопасности должны:
- Следите за публикациями HHS и штата для предварительного уведомления об изменениях правил. В идеале это должно включать подписку на новостную ленту или другой официальный канал связи.
- При выпуске новых правил или руководств проведите оценку рисков, чтобы определить, как они повлияют на деятельность организации и требуется ли обучение HIPAA.
- Связь с менеджерами по персоналу и практикой для получения предварительного уведомления о предлагаемых изменениях, чтобы определить их влияние на соблюдение правила конфиденциальности HIPAA.
- Связывайтесь с ИТ-менеджерами для получения предварительного уведомления об обновлениях оборудования или программного обеспечения, которые могут повлиять на соблюдение правила безопасности HIPAA.
- Проводите регулярную оценку рисков, чтобы определить, как существенные изменения в политике или процедурах могут увеличить или уменьшить риск нарушений HIPAA.
- Составьте программу обучения, в которой описывается, как любые изменения повлияют на соблюдение сотрудниками требований HIPAA, а не только сами изменения.
- Разработайте программу повышения квалификации по HIPAA, которую можно проводить не реже одного раза в год, чтобы усилить необходимость соблюдения правил HIPAA.
Естественно, в случае изменений в методах работы и технологиях обучение HIPAA необходимо проводить только для сотрудников, чьи роли будут затронуты изменениями. Как упоминается в разделе «Передовой опыт» ниже, также рекомендуется включать в тренинги хотя бы одного члена высшего руководства, даже если они не затронуты новыми политиками или процедурами, поскольку это показывает, что вся организация принимает его требования к обучению HIPAA серьезно.
Что должно быть включено в курс обучения HIPAA?
Хотя каждый учебный курс HIPAA должен быть адаптирован к ролям сотрудников, посещающих курс, необходимо включить некоторые важные элементы. В следующей таблице приведен пример того, что должен включать базовый курс обучения HIPAA, хотя охваченным организациям может потребоваться сосредоточиться на одних областях больше, чем на других. Однако ни одна из этих областей не должна полностью исключаться при обучении медицинских работников HIPAA.
| Области, которые следует охватить в учебном курсе HIPAA | |||
|---|---|---|---|
| Обзор HIPAA | Права пациентов | Защита ePHI | Последствия нарушения HIPAA |
| Почему HIPAA важен | Правила HIPAA о раскрытии информации PHI | HIPAA и социальные сети | Политика в отношении санкций |
| Определения HIPAA | Правило безопасности HIPAA | HIPAA в чрезвычайных ситуациях | Уведомления о нарушениях HIPAA |
| Правило конфиденциальности HIPAA | Угрозы данным пациентов | Предотвращение нарушений HIPAA | Последние обновления HIPAA |
Тренинг по безопасности HIPAA
Правило безопасности HIPAA требует, чтобы обучение по вопросам безопасности проводилось «периодически», что, по общему мнению, означает не реже одного раза в год.Медицинские работники становятся жертвами киберпреступников, поэтому важно, чтобы медицинские работники и студенты знали об угрозах, с которыми они могут столкнуться, были обучены распознавать эти угрозы безопасности HIPAA и были обучены передовым методам защиты ePHI и способам реагирования на них. возникла угроза.
Рассмотрите возможность проведения ежегодных учебных занятий по вопросам безопасности HIPAA, перемежающихся с более короткими курсами повышения квалификации в течение года. Киберпреступники часто меняют свою тактику, методы и процедуры.Сотрудники должны быть осведомлены о последних угрозах, нацеленных на работников здравоохранения, и пройти обучение тому, как распознавать фишинговые электронные письма и другие угрозы, которые регулярно подкрепляются. Обучение осведомленности о безопасности важно не только для соответствия HIPAA, оно также поможет предотвратить дорогостоящие утечки данных и штрафы регулирующих органов.
Лучшие практики для обучения соответствию требованиям HIPAA
Поскольку конкретных требований к обучению HIPAA не существует, мы собрали небольшую серию передовых практик, которые менеджеры по соблюдению требований HIPAA могут захотеть учесть при составлении «необходимого и подходящего» обучения по вопросам безопасности, обучения HIPAA для сотрудников при адаптации и программ повышения квалификации HIPAA. .Наши передовые методы обучения соблюдению требований HIPAA не высечены из камня и могут быть выбраны по желанию.
- Сделайте тренировок короткими и приятными. Рекомендуется, чтобы учебные занятия продолжались не более одного часа и были «периодическими» повторениями, как это предусмотрено Правилом безопасности HIPAA. Ежегодного повышения квалификации по HIPAA достаточно для выполнения «периодических» требований.
- Включите ли последствия нарушения HIPAA в обучение — не только финансовые последствия для CE или BA, но и последствия для стажеров и их коллег и, конечно же, лиц, чья PHI была раскрыта. .
- Не цитируйте длинные отрывки текста из руководств HIPAA или правил. Используйте мультимедийные презентации, чтобы сделать обучение незабываемым. Тренинг по соблюдению требований HIPAA должен быть не только усвоен, его нужно понимать и выполнять в повседневной жизни.
- Do включает в обучение высшее руководство. Даже если руководители высшего звена не контактируют с PHI, важно, чтобы они участвовали в обучении соблюдению требований HIPAA. Знание о том, что к обучению серьезно относятся наверху, побудит других отнестись к нему серьезно.
- Не забывайте задокументировать свое обучение. В случае расследования или аудита OCR важно иметь возможность представить содержание обучения, а также то, когда оно проводилось, кому и как часто. Сотрудники должны подписаться, чтобы подтвердить, что они прошли ознакомительный курс HIPAA.
- Do рассмотрите возможность проведения онлайн-обучения HIPAA для сотрудников. Модульные онлайн-курсы обучения HIPAA можно пройти, когда у сотрудников есть свободное время, что облегчает их включение в загруженные рабочие процессы.Онлайн-курсы HIPAA особенно полезны для повторного обучения HIPAA.
- Проводите ли регулярные тренинги по вопросам безопасности. Это поможет сформировать культуру безопасности в вашей организации и снизить риск утечки данных.
Тренинг по государственным законам о конфиденциальности информации здравоохранения
HIPAA — это федеральный закон, который применяется к Защищаемым организациям и их бизнес-партнерам, но это не единственный закон, регулирующий конфиденциальность и безопасность медицинских данных.HIPAA устанавливает минимальные стандарты конфиденциальности и безопасности медицинской информации, но штаты могут вводить более строгие требования. Помимо обучения HIPAA, обучение также должно проводиться в соответствии с законами штата. Например, медицинские организации в Техасе и те, кто обслуживает жителей Техаса, обязаны проводить обучение по Texas HB 300 и требованиям Закона штата Техас о конфиденциальности медицинских записей, которые выходят за рамки минимальных стандартов HIPAA.
Сводка требований к обучению HIPAA
Требования к обучению HIPAA для работодателей
В большинстве случаев требования к обучению HIPAA для работодателей применяются только к работодателям, которые являются участниками HIPAA или бизнес-партнерами.Квалифицированные работодатели должны предоставить обучение HIPAA всем сотрудникам, независимо от их роли в организации, в соответствии с административными мерами безопасности правила безопасности HIPAA.
Если работодатель не является покрываемым юридическим лицом или деловым партнером, но участвует в транзакциях, покрываемых HIPAA (например, работодатель управляет самозастрахованным планом медицинского страхования), обучение HIPAA необходимо проводить только для сотрудников, имеющих доступ к PHI или ePHI. . Дополнительную информацию о требованиях к обучению HIPAA для работодателей в этих обстоятельствах можно найти в этой статье.
Обучение сотрудников HIPAA
В дополнение к предоставлению «необходимого и надлежащего» обучения сотрудников HIPAA рекомендуется проводить дополнительное обучение, которое придает контекст обучению, которое получает каждый сотрудник. Например, при обучении сотрудников правилам HIPAA по раскрытию PHI рекомендуется также обсудить последствия нарушений HIPAA.
Документирование обучения сотрудников является требованием HIPAA. Тем не менее, это имеет преимущества, поскольку, если происходят существенные изменения в политиках или процедурах, и они влияют только на определенную область соответствия HIPAA, существует запись о том, кто прошел обучение в этой конкретной области соответствия HIPAA и кто теперь нуждается в повышении квалификации.
Повышение квалификации по HIPAA
Помимо предоставления при существенном изменении политики или процедур, необходимо проводить переподготовку HIPAA для персонала всякий раз, когда обнаруживаются новые угрозы для данных пациентов. Важно, чтобы сотрудники знали, как выявлять угрозы и реагировать на них, а отсрочка обучения такого рода до того, как ежегодный день переподготовки может привести к утечке данных, которую можно предотвратить.
Помимо учета изменений в политике и процедурах, курсы повышения квалификации по HIPAA также должны периодически проходить по старому принципу, чтобы напоминать сотрудникам, почему HIPAA важен и каковы права пациентов, особенно с учетом того, что недавно были предложены изменения в Правиле конфиденциальности HIPAA. это улучшит совместное использование данных и взаимодействие, а также запретит блокировку информации.
Тренинг HIPAA для медсестер
Хотя каждый учебный курс HIPAA должен быть адаптирован к ролям сотрудников, обучение HIPAA для медсестер должно быть сосредоточено на требованиях конфиденциальности в отношении раскрытия информации. Это происходит не из-за риска, что медсестры могут непреднамеренно раскрыть PHI в пределах слышимости третьих лиц, а из-за особых отношений, которые они развивают с пациентами.
Пациенты часто раскрывают медсестрам информацию, которую они не могут раскрывать своим врачам, и медсестры должны знать, что тот факт, что пациент поделился с ними информацией, не означает, что пациент дал согласие на передачу этой информации кому-либо. еще.Следовательно, медсестры должны знать, как поступать с раскрытием конфиденциальной информации в контексте HIPAA.
Тренинг HIPAA для ИТ-специалистов
Естественно предположить, что обучение HIPAA для ИТ-специалистов должно быть сосредоточено на ИТ-безопасности и защите сетей от несанкционированного доступа, но также важно, чтобы ИТ-специалисты прошли обучение по проблемам, с которыми сталкиваются передовые медицинские специалисты, работающие в соответствии с HIPAA.
Это значит, что ИТ-специалисты проектируют системы и разрабатывают процедуры, которые соответствуют потребностям медицинских работников.Если системы и процедуры слишком сложны или кажутся не имеющими отношения к ролям отдельных лиц, будут найдены способы обойти системы — потенциально подвергая ePHI риску раскрытия, потери или кражи.
Тренинг HIPAA для медицинского персонала
В зависимости от размера медицинского офиса и разнообразия ролей, выполняемых персоналом, обучение HIPAA для медицинского персонала, вероятно, будет более комплексным, чем для любой другой категории работников здравоохранения. Это связано с тем, что команды медицинского офиса часто могут иметь дело с пациентами, их семьями, запросами от третьих лиц, поставщиков, платежных систем и планов медицинского обслуживания.
Ряд сценариев, с которыми, вероятно, столкнутся медицинские сотрудники, являются одной из причин, по которым обучение HIPAA должно быть запоминающимся, чтобы его можно было применять в повседневной жизни. Что касается обучения HIPAA для медицинского персонала, чем больше оно контекстно, тем лучше, поскольку оно поможет сотрудникам лучше понять значение HIPAA и почему защита ePHI так важна.
Требования к обучению по HIPAA для деловых партнеров
Требования к обучению HIPAA для бизнес-партнеров часто неправильно понимают, потому что нигде в Правиле конфиденциальности не говорится, что обучение HIPAA для бизнес-партнеров является обязательным.Тем не менее, административные меры безопасности правила безопасности HIPAA (45 CFR § 164.308) гласят:
«Защищенное лицо или деловой партнер должен…… внедрить программу обучения и повышения осведомленности о безопасности для всех своих сотрудников (включая руководство)».
Хотя это можно интерпретировать как общую программу обучения и повышения осведомленности о безопасности, а не как программу обучения и осведомленности в области безопасности HIPAA, имеет смысл обучать HIPAA, потому что, если происходит нарушение HIPAA, и нет доказательств того, что обучение HIPAA проходило было предоставлено, это, вероятно, приведет к более суровым санкциям за «умышленное пренебрежение».
Тренинг по соблюдению требований HIPAA для бизнес-партнеров
Принимая во внимание приведенный выше комментарий, тренинг по соблюдению требований HIPAA для бизнес-партнеров должен состоять из базового обучения HIPAA, а затем ролевого обучения в зависимости от услуг, предоставляемых бизнес-партнером и его сотрудниками. Тем не менее, важно, чтобы покрываемые организации провели тщательную комплексную проверку бизнес-партнеров, чтобы убедиться, что обучение является надлежащим.
Проблема с обучением по соблюдению требований HIPAA для бизнес-партнеров заключается в том, что многие бизнес-партнеры не имеют ресурсов для назначения специалиста по соблюдению требований HIPAA, и задача обеспечения соблюдения требований HIPAA часто делегируется существующему сотруднику, который может не иметь знаний — или время — чтобы обеспечить правильное обучение HIPAA нужным людям.
Узнайте больше о требованиях к обучению HIPAA
Последствия неадекватной подготовки могут быть значительными — не только с финансовой точки зрения, но и с точки зрения человека. Тем не менее, многих нарушений HIPAA можно избежать с помощью соответствующего обучения соблюдению требований HIPAA. Хотя единственными требованиями к обучению HIPAA, по-видимому, является обязательное обучение, вы можете узнать больше о том, какое облако будет включено в обучение по соответствию HIPAA, прочитав подробное руководство по соответствию HIPAA.
Часто задаваемые вопросы о требованиях к обучению HIPAA
Кто отвечает за организацию обучения HIPAA?
Специалисты по соблюдению требований HIPAA должны отвечать за организацию обучения сотрудников HIPAA, хотя они не обязательно должны проводить обучение самостоятельно.Если, например, обучение включает в себя использование нового программного обеспечения в соответствии с нормативными требованиями, то, возможно, будет лучше, если член ИТ-группы проведет обучение, хотя специалист по соблюдению нормативных требований должен присутствовать на презентации.
Должен ли сотрудник по вопросам конфиденциальности проводить обучение по вопросам конфиденциальности, а сотрудник по безопасности — по вопросам безопасности?
Хотя это кажется разумным, поскольку каждый сотрудник будет специалистом в своей области, чтобы отвечать на вопросы, нет необходимости разделять обязанности по обучению.Кроме того, в HIPAA существует много пересечений между конфиденциальностью и безопасностью, поэтому обе темы обычно рассматриваются в учебном занятии, если только сеанс не посвящен конкретной теме конфиденциальности или безопасности.
Что является примером «существенного изменения политики»?
Некоторым больницам, возможно, придется внести поправки в политику и процедуры, чтобы приспособиться к переходу от программы «Значимое использование» CMS к программе «Содействие взаимодействию». Если изменения в политике влияют на способ управления ePHI, персонал, участвующий в управлении данными для программы «Содействие взаимодействию», должен пройти обучение, чтобы избежать пробелов в их знаниях.
Какие руководители высшего звена должны участвовать в обучении HIPAA?
Все они — хотя не обязательно все одновременно. Хотя важно, чтобы руководители высшего звена знали о влиянии соответствия требованиям HIPAA на операции, более практично привлекать (например) ИТ-директоров и руководителей по информационной безопасности к обучению технологиям, а финансовым директорам — к обучению, касающемуся взаимодействия между организациями здравоохранения и страховыми компаниями.