ТРАНСФОРМАТОРЫ. РАСШИФРОВКА НАИМЕНОВАНИЙ
Наименование (а точнее, номенклатура) трансформатора, говорит о его конструктивных особенностях и параметрах. При умении читать наименование оборудования можно только по нему узнать количество обмоток и фаз силового трансформатора, тип охлаждения, номинальную мощность и напряжение высшей обмотки.
ОБЩИЕ РЕКОМЕНДАЦИИНоменклатура трансформаторов (расшифровка буквенных и цифровых обозначений наименования) не регламентируется какими-либо нормативными документами, а всецело определяется производителем оборудования. Поэтому, если название Вашего трансформатора не поддаётся расшифровке, то обратитесь к его производителю или посмотрите паспорт изделия. Приведенные ниже расшифровки букв и цифр названия трансформаторов актуальны для отечественных изделий.
Наименование трансформатора состоит из букв и цифр, каждая из которых имеет своё значение. При расшифровке наименования следует учитывать то что некоторые из них могут отсутствовать в нём вообще (например буква «А» в наименовании обычного трансформатора), а другие являются взаимоисключающими (например, буквы «О» и «Т»).
Для силовых трансформаторов приняты следующие буквенные обозначения:
Таблица 1 — Расшифровка буквенных и цифровых обозначений наименования силового трансформатора
Примечание: принудительная циркуляция воздуха называется дутьем, то есть «с принудительной циркуляцией воздуха» и «с дутьем» равнозначные выражения.
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ СИЛОВЫХ ТРАНСФОРМАТОРОВ
ТМ — 100/35 — трансформатор трёхфазный масляный с естественной циркуляцией воздуха и масла, номинальной мощностью 0,1 МВА, классом напряжения 35 кВ;
ТДНС — 10000/35 — трансформатор трёхфазный с дутьем масла, регулируемый под нагрузкой для собственных нужд электростанции, номинальной мощностью 10 МВА, классом напряжения 35 кВ;
ТРДНФ — 25000/110 — трансформатор трёхфазный, с расщеплённой обмоткой, масляный с принудительной циркуляцией воздуха, регулируемый под нагрузкой, с расширителем, номинальной мощностью 25 МВА, классом напряжения 110 кВ;
АТДЦТН — 63000/220/110 — автотрансформатор трёхфазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 63 МВА, класс ВН — 220 кВ, класс СН — 110 кВ;
АОДЦТН — 333000/750/330 — автотрансформатор однофазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 333 МВА, класс ВН — 750 кВ, класс СН — 500 кВ.
Для регулировочных трансформаторов приняты следующие сокращения:
Таблица 2 — Расшифровка буквенных и цифровых обозначений наименования регулировочного трансформатора
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ РЕГУЛИРОВОЧНЫХ ТРАНСФОРМАТОРОВ
ВРТДНУ — 180000/35/35 — трансформатор вольтодобавочный, регулировочный, трёхфазный, с масляным охлаждением типа Д, регулируемый под нагрузкой, с усиленным вводом, проходной мощностью 180 МВА, номинальное напряжение обмотки возбуждения 35 кВ, номинальное напряжения регулировочной обмотки 35 кВ;
ЛТМН — 160000/10 — трансформатор линейный, трёхфазный, с естественной циркуляцией масла и воздуха, регулируемый под нагрузкой, проходной мощностью 160 МВА, номинальным линейным напряжением 10 кВ.
РАСШИФРОВКА НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ НАПРЯЖЕНИЯ
Для трансформаторов напряжения приняты следующие сокращения:
Таблица 3 — Расшифровка буквенных и цифровых обозначений наименования трансформатора напряжения
Примечание:
Комплектующий для серии НОСК;
С компенсационной обмоткой для серии НТМК;
Кроме серии НОЛ и ЗНОЛ, в которых:
— 06 — для встраивания в закрытые токопроводы, ЗРУ и КРУ внутренней установки;
— 08 — для ЗРУ и КРУ внутренней и наружной установки;
— 11 — для взрывоопасных КРУ.
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ НАПРЯЖЕНИЯ
НОСК-3-У5 — трансформатор напряжения однофазный с сухой изоляцией, комплектующий, номинальное напряжение обмотки ВН 3 кВ, климатическое исполнение — У5;
НОМ-15-77У1 — трансформатор напряжения однофазный с масляной изоляцией, номинальное напряжение обмотки ВН 15 кВ, 1977 года разработки, климатическое исполнение — У1;
ЗНОМ-15-63У2 — трансформатор напряжения с заземляемым концом обмотки ВН, однофазный с масляной изоляцией, номинальное напряжение обмотки ВН 15 кВ, 1963 года разработки, климатическое исполнение — У2;
ЗНОЛ-06-6У3 — трансформатор напряжения с заземляемым концом обмотки ВН, однофазный с литой эпоксидной изоляцией, для встраивания в закрытые токопроводы, ЗРУ и КРУ внутренней установки, климатическое исполнение — У3;
НТС-05-УХЛ4 — трансформатор напряжения трёхфазный с сухой изоляцией, номинальное напряжение обмотки ВН 0,5 кВ, климатическое исполнение — УХЛ4;
НТМК-10-71У3 — трансформатор напряжения трёхфазный с масляной изоляцией и компенсационной обмоткой, номинальное напряжение обмотки ВН 10 кВ, 1971 года разработки, климатическое исполнение — У3;
НТМИ-10-66У3 — трансформатор напряжения трёхфазный с масляной изоляцией и обмоткой для контроля изоляции сети, номинальное напряжение обмотки ВН 10 кВ, 1966 года разработки, климатическое исполнение — У3;
НКФ-110-58У1 — трансформатор напряжения каскадный в фарфоровой покрышке, номинальное напряжение обмотки ВН 110 кВ, 1958 года разработки, климатическое исполнение — У1;
НДЕ-500-72У1 — трансформатор напряжения с ёмкостным делителем, номинальное напряжение обмотки ВН 500 кВ, 1972 года разработки, климатическое исполнение — У1;
РАСШИФРОВКА НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ ТОКА
Для трансформаторов тока приняты следующие сокращения:
Таблица 4 — Расшифровка буквенных и цифровых обозначений наименования трансформатора тока
Примечание:
Для серии ТВ, ТВТ, ТВС, ТВУ;
Для серии ТНП, ТНПШ — с подмагничиванием переменным током;
Для серии ТШВ, ТВГ;
Для ТВВГ — 24 — водяное охлаждение;
Для серии ТНП, ТНПШ;
Для серии ТВ, ТВТ, ТВС, ТВУ — номинальное напряжения оборудования;
Для серии ТНП, ТНПШ — число обхватываемых жил кабеля;
Для серии ТНП, ТНПШ — номинальное напряжение.
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ ТОКА
ТФЗМ — 35А — У1 — трансформатор тока в фарфоровой покрышке, с обмоткой звеньевого исполнения, с масляной изоляцией, номинальным напряжением обмотки ВН 35 кВ, категории А, климатическим исполнением У1;
ТФРМ — 750М — У1 — трансформатор тока в фарфоровой покрышке, с обмоткой рымочного исполнения, с масляной изоляцией, номинальным напряжением обмотки ВН 750 кВ, климатическим исполнением У1;
ТШЛ — 10К — трансформатор тока шинный с литой изоляцией, номинальное напряжением обмотки ВН 10 кВ;
ТЛП — 10К — У3 — трансформатор тока с литой изоляцией, проходной, номинальным напряжением обмотки ВН 10 кВ, климатическое исполнение — У3;
ТПОЛ — 10 — трансформатор тока проходной, одновитковый, с литой изоляцией, номинальным напряжением обмотки ВН 10 кВ;
ТШВ — 15 — трансформатор тока шинный, с воздушным охлаждением, номинальным напряжением обмотки ВН 15 кВ;
ТВГ — 20 — I — трансформатор тока с воздушным охлаждением, генераторный, номинальным напряжением обмотки ВН 20 кВ;
ТШЛО — 20 — трансформатор тока шинный, с литой изоляцией, одновитковый, номинальным напряжением обмотки ВН 20 кВ;
ТВ — 35 — 40У2 — трансформатор тока встроенный, номинальным напряжением обмотки ВН 35 кВ, током термической стойкости 40 кА, климатическое исполнение — У2;
ТНП — 12 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, охватывающий 12 жил кабеля;
ТНПШ — 2 — 15 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, шинный, охватывающий 2 жилы кабеля, номинальным напряжением обмотки ВН 15 кВ.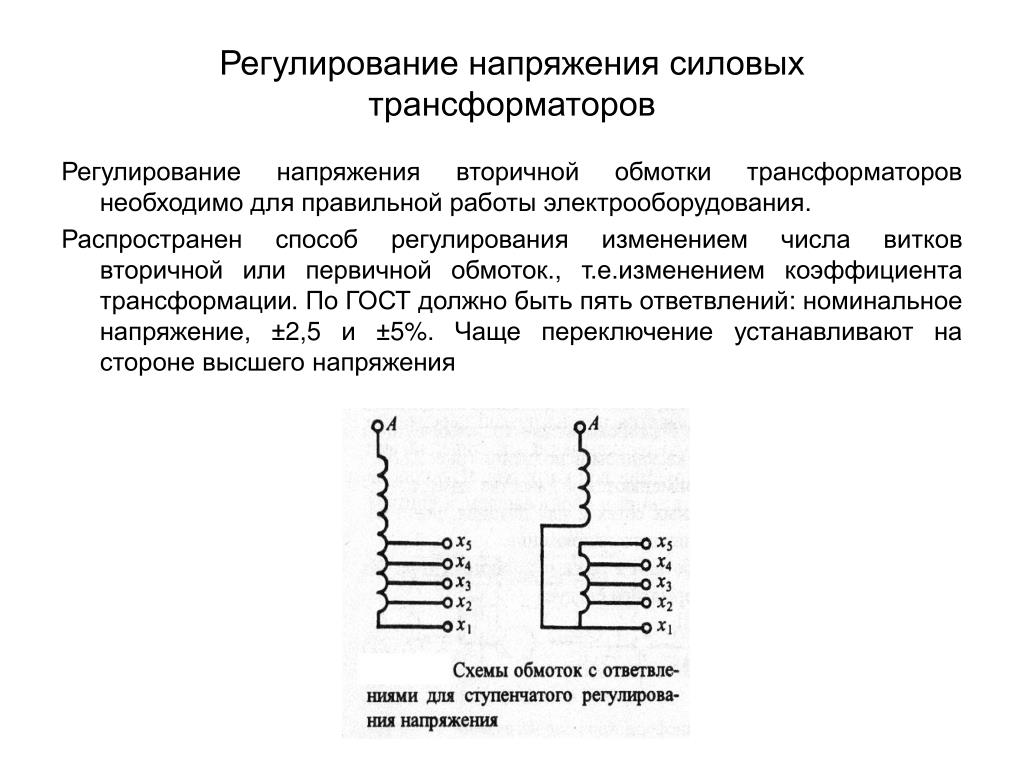
Трансформаторы силовые масляные трехфазные класса напряжения 110 кВ
- Трансформаторы двухобмоточные с переключением ответвлений без возбуждения (ПБВ) на стороне ВН в диапазоне ± 2х2,5 % и без ПБВ, предназначены для передачи и распределения электроэнергии, а также для работы на электростанциях в блоке с генератором
- Трансформаторы двухобмоточные с переключением ответвлений под нагрузкой (РПН) на стороне ВН в диапазоне ± 9х1,78 % предназначены для передачи и распределения электроэнергии, а также для собственных нужд электростанций
- Трансформаторы трехобмоточные с переключением ответвлений под нагрузкой (РПН) на стороне ВН в диапазоне ± 9х1,78 % с регулированием напряжения на стороне СН без возбуждения (ПБВ) в диапазоне ± 2х2,5 % и без регулирования напряжения на сторое СН, предназначены для передачи и распределения электроэнергии
Опросные листы для всех трансформаторов
Параметры
(1)
| Серия | Номинальная мощность, кВА | Схема и группа соединения обмоток | Напряжение обмотки, кВ | |
ВН | НН | ||||
1 | ТМ-2500/110 | 2500 | YН/D-11 | 121 | 6,30; 10,5 |
2 | ТМ-4000/110 | 4000 | |||
3 | ТМ-6300/110 | 6300 | |||
4 | ТД-10000/110 | 10000 | |||
5 | ТД-16000/110 | 16000 | |||
6 | ТД-25000/110 | 25000 | |||
7 | ТД-32000/110 | 32000 | |||
8 | ТД-40000/110 | 40000 | 115; 121 | ||
9 | ТДЦ-63000/110 | 63000 | 121 | 10,5 | |
10 | ТДЦ-80000/110 | 80000 | 3,15;6,3; 10,5; 3,8 | ||
11 | ТДЦ-100000/110 |
| 10,5 | ||
12 | ТДЦ-125000/110 | 125000 | 10,5; 13,8 | ||
(2)
| Серия | Номинальная мощность, кВА | Схема и группа соединения обмоток | Напряжение обмотки, кВ | |
ВН | НН | ||||
13 | ТМН-2500/110* | 2500 | YН/D-11 | 110 | 6,6; 11,0 |
14 | ТМН-6300/110 | 6300 | 115 | 6,6; 10,5; 11,0; 16,5 | |
15 | ТДН-10000/110 | 10000 | 6,3; 6,6; 10,5; 11,0; 16,5; 22,0; 34,5 | ||
16 | ТДН-16000/110 | 16000 | 6,3; 6,6; 10,5; 11,0; 16,5; 22,0; 34,5; 38,5 | ||
17 | ТДН-25000/110 | 25000 | 6,3; 6,6; 10,5; 11,0; 16,5; 38,5 | ||
18 | ТДН-40000/110 | 40000 | 6,3; 10,5; 11,0; 38,5 | ||
YН/Y-0 | 38,5; 11 | ||||
19 | ТДН-63000/110 | 63000 | YН/D-11 | 38,5 | |
20 | ТДН-80000/110 | 63000 | |||
21 | ТРДН-25000/110 | 25000 | YН/D-D-11-11 | 6,3-6,3; 6,6-6,6; 10,5-10,5; 11,0-11,0; 6,3-10,5; 11,0-6,6 | |
22 | ТРДНС-25000/110 | ||||
23 | ТРДН-32000/110 | 32000 | 6,3-6,3 | ||
24 | ТРДН-40000/110 | 40000 | 6,3-6,3; 6,6-6,6; 10,5-10,5; 11,0-11,0; 6,3-10,5; 11,0-6,3; 11,0-6,6 | ||
25 | ТРДНС-40000/110 | ||||
26 | ТРДНР-40000/110 | 11,0-6,6 | |||
27 | ТРДН-63000/110 | 63000 | 6,3-6,3; 6,35-6,35; 6,6-6,6; 10,5-10,5; 11,0-11,0; 6,3-10,5 6,35-10,5; 11,0-6,6 | ||
28 | ТРДНС-63000/110 | ||||
29 | ТРДН-80000/110 | 80000 | 6,3; 6,65; 10,5; 10,5 | ||
30 | ТРДЦН-125000/110 | 125000 | YН/D-D-11-11 | 10,5-10,5 | |
* — Регулирование напряжения со стороны НН (+10х1,5 % -8х1,5 %)
(3)
| Серия | Номинальная мощность, кВА | Схема и группа соединения обмоток | Напряжение обмотки, кВ | ||
ВН | СН | НН | ||||
31 | ТМТН-6300/110 | 6300 | YН/D/D-11-11 | 115 | 16,5; 22,0 | 6,6; 11,0 |
YН/YН/D-0-11 | 38,5 | |||||
32 | ТДТН-10000/110 | 10000 | YН/D/D-11-11 | 16,5; 22,0 | 6,3; 6,6; 11 | |
YН/YН/D-0-11 | 34,5; 8,5 | |||||
33 | ТДТН-16000/110 | 16000 | YН/D/D-11-11 | 6,3; 10,5; 1,0; 22,0 | 6,3; 6,6; 11 | |
YН/YН/D-0-11 | 34,5; 38,5 | |||||
34 | ТДТН-25000/110 | 25000 | YН/D/D-11-11 | 11,0; 16,5 | 6,6 | |
38,5 | 11,0; 6,6 | |||||
10,5 | 10,5 | |||||
6,3 | 6,3 | |||||
22,0 | 6,6; 11,0 | |||||
YН/YН/D-0-11 | 34,5; 36,75; 38,5; | |||||
YН/D/Y-11-4 | 16,5 | 6,6 | ||||
35 | ТДТН-40000/110 | 40000 | YН/D/D-11-11 | 10,5 | 6,3 | |
11,0 | 6,6 | |||||
22,0 | 6,6; 11,0 | |||||
YН/YН/D-0-11 | 34,5; 38,5 | |||||
36 | ТДТН-63000/110 | 63000 | YН/D/D-11-11 YН/YН/D-0-11 | 11,0; 34,5 | 6,6 | |
38,5 | 6,6; 11,0 | |||||
37 | ТДТН-80000/110 | 80000 | YН/D/D-11-11 | 11,0 | 6,6 | |
YН/YН/D-0-11 | 38,5 | 6,6; 11,0 | ||||
38 | ТДЦТН-80000/110 | 80000 | YН/D/D-11-11 | 11,0 | 6,6 | |
YН/YН/D-0-11 | 38,5 | 6,6; 11,0 | ||||
Опросные листы ниже
1. на двухобмоточные
на двухобмоточные
2. на трехобмоточные
Прикрепленные файлы
Напишите нам
Трансформаторы
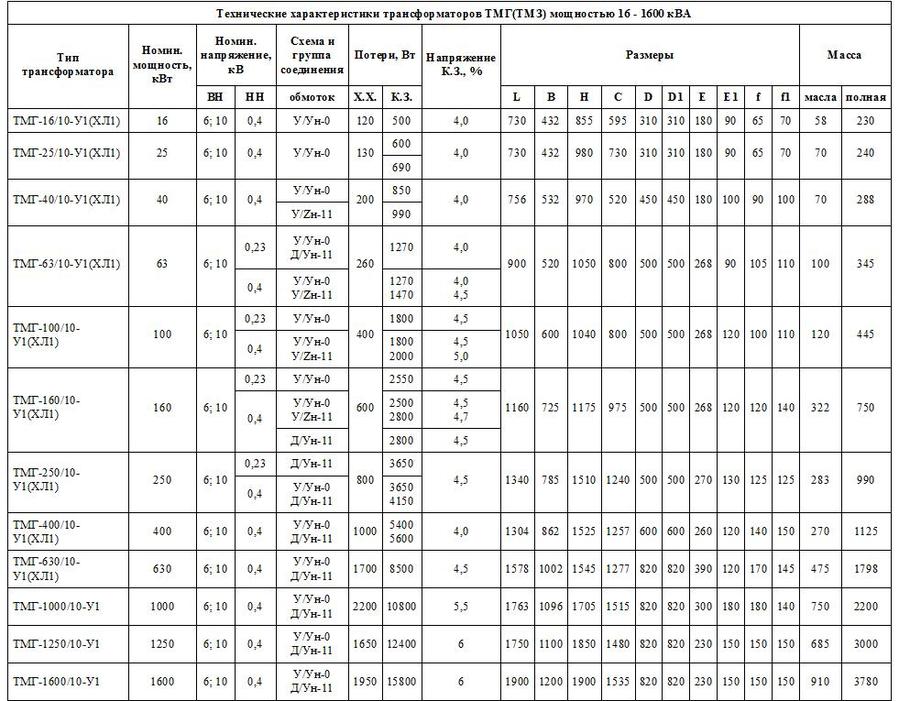
ТМ(Г) – это силовые трехфазные двухобмоточные трансформаторы. Они относится к трансформаторам понижающего типа на масляном охлаждении. ТМ(Г) преобразуют переменный ток и распределяют электроэнергию в различных электротехнических установках. Силовые трансформаторы делятся на понижающие и повышающие. Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТМ(Г) — Т1\Т2\Т3 У/Ун-0:
- Т – трехфазный;
- М – охлаждается от окружающей среды, с использованием масла;
- (Г) – виды защиты масла: герметичные;
- Т1 – номинальная мощность;
- Т2/Т3– класс напряжения обмотки ВН и НН;
- У/Ун-0 – схема и группа соединения обмоток;
ТС(З)(Г)Л — это сухие силовые трансформаторы и не имеют масляного охладителя, его заменяет естественная среда.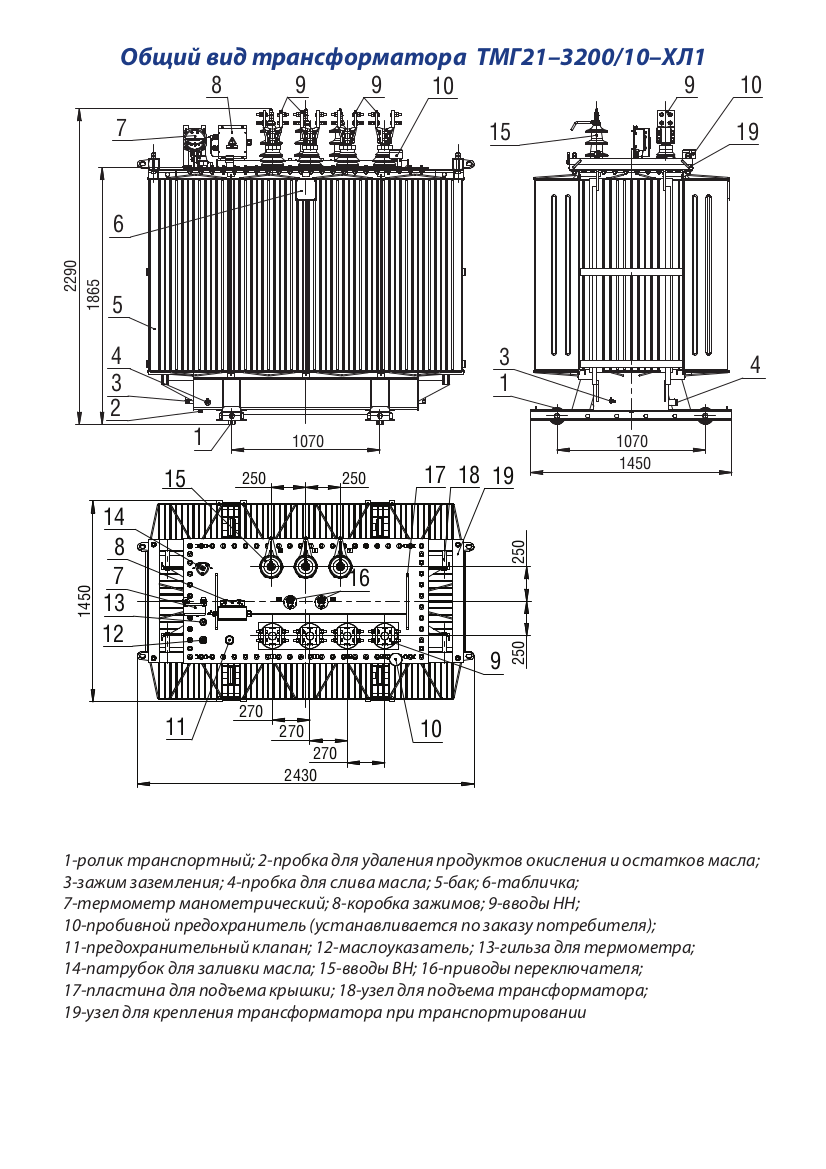 Они являются разновидностью силовых трансформаторов. Если вы решили купить сухой трансформатор – то сделали правильный выбор. Они могут быть установлены вблизи от потребителей, так как являются пожаробезопасными. К тому же сухой трансформатор меньше размером, чем маслянный. Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТС(З)(Г)Л — Т1\Т2\Т3 Д/Ун-11:
Они являются разновидностью силовых трансформаторов. Если вы решили купить сухой трансформатор – то сделали правильный выбор. Они могут быть установлены вблизи от потребителей, так как являются пожаробезопасными. К тому же сухой трансформатор меньше размером, чем маслянный. Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТС(З)(Г)Л — Т1\Т2\Т3 Д/Ун-11:
- Т – трехфазный;
- С – охлаждается от окружающей среды, без использования масла;
- З – имеется защитный кожух;
- Г – в обмотку добавлен кварцевый компаунд «ГЕАФОЛЬ»;
- Л – эпоксидная изоляция обмотки;
- Т1 – номинальная мощность;
- Т2/Т3– класс напряжения обмотки ВН и НН;
- Д/Ун-11 – схема и группа соединения обмоток.
Трансформаторы серии ТМГ предназначены для работы в умеренном и холодном климате. Для работы необходима окружающая среда, не содержащая взрывоопасных и легковоспламеняющихся веществ. Также они не выдерживают тряски, вибрации и ударов.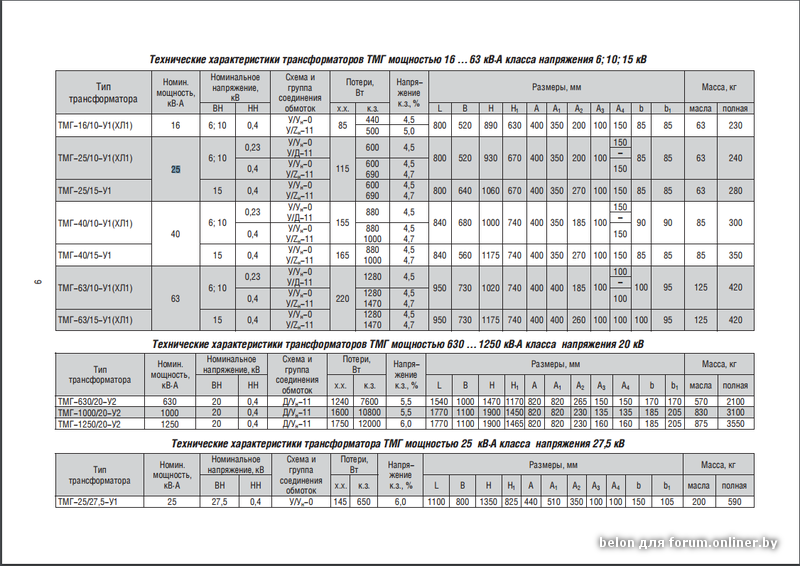 Напряжение настраивается на отключенном полностью трансформаторе переключением ответвлений его обмотки переключателем типа ПБВ.
Напряжение настраивается на отключенном полностью трансформаторе переключением ответвлений его обмотки переключателем типа ПБВ.
На современных трансформаторах установлены поплавковые маслоуказатели, для того, чтобы измерять уровень масла. Обезопасить трансформатор мощностью до 63 кВА от избыточного давления поможет специальный предохранительный клапан. По желанию клиента на трансформаторах мощностью выше 100 кВА. устанавливается вакуумметр.
Также на такие трансформаторы устанавливаются термометры для измерения температуры масла. На большие трансформаторы (мощностью более 630 кВА) устанавливаются ролики для его перемещения по разным направлениям. Также можно установить ролики на меньшие трансформаторы.
При производстве трансформаторов ТМГ используются передовые технологии, благодаря чему повышаются эксплуатационные характеристики, долговечность и надежность. Изделие является герметичным и полностью заполняется маслом без воздушной подушки. Масло не вступает в контакт с окружающей средой, поэтому оно не окисляется и не загрязняется..jpg)
Перед использованием масла из него удаляются все газы. В бак оно заливается в вакуумной камере. Благодаря этому из масла выходит весь воздух. Также удаляются из емкости различные воздушные и газовые подушки. Благодаря этому обеспечивается высокая устойчивость изоляции трансформатора к электрическим нагрузкам и долговечность устройства. Масло при такой заливке не подвержено окислению и практически не портится на протяжении всего времени эксплуатации. Заявленный срок службы трансформатора – 25 лет.
Масло силовых трансформаторов ТМ, ТМГ и т.д., большинства заводов изготовителей проходит процедуру дегазации. Что позволяет увеличить срок иксплуатации изделия.
У нас вы можете купить силовые трансформаторы как повышающие, так и понижающие, с минимальными сроками и наличием на складе (по заявке). Мы продаем трансформаторы от 16 кВА до 3150кВА.Также мы предлагаем вам однофазные трансформаторы ОМП, которые предназначены для питания систем безопасности и прочих однофазных приборов. Производитель дает гарантию на трансформаторы от 3 до 5 лет.
Производитель дает гарантию на трансформаторы от 3 до 5 лет.
Скачать опросный лист на ТМГ
Присоединительный трансформатор, трансформатор дугогасящего реактора ТМПС
Гарантийный срок устанавливается 60 месяцев (5 лет) с момента отгрузки трансформаторов потребителю.
Назначение
Трансформаторы серии ТМПС предназначены для подключения дугогасящих реакторов.
Трансформаторы предназначены для эксплуатации в районах с умеренным и умеренным и холодным климатом на открытом воздухе (исполнение У1 и УХЛ1 по ГОСТ 15150), при этом:
- окружающая среда не взрывоопасная, не содержащая токопроводящей пыли;
- высота установки над уровнем моря не более 1000 м;
- режим работы двухобмоточных трансформаторов длительный, допускается 10% перегрузка в шестичасовом режиме с повторным включением через 12 часов;
-
режим работы однообмоточных трансформаторов, при максимальном токе, шестичасовой с повторным включением через 12 часов, при номинальном токе длительный режим;
-
температура окружающей среды:
- от минус 45ºС до плюс 40 ºС для климатического исполнения У1,
- от минус 60 ºС до плюс 40 ºС для климатического исполнения УХЛ1;
- трансформаторы не предназначены для работы в условиях тряски, вибраций, ударов, в химически активной среде.

Параметры силовых трансформаторов ТМПС
Таблица 1 — Основные технические параметры трансформаторов 6 кВ, 10 кВ.
|
Наименование параметра |
Значения |
||||||||
|
Номинальная мощность, кВ·А |
100 |
250 |
400 |
630 |
1000 |
1250 |
1600 |
2000 |
2500 |
|
Номинальная частота, Гц |
50 |
50 |
50 |
50 |
50 |
50 |
50 |
50 |
50 |
|
Номинальные напряжения, кВ |
|
|
|
|
|
|
|||
|
ВН |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
10,5 (6,3) |
|
НН |
0,23 |
0,23 |
0,23 |
0,23 |
0,23 |
0,23 |
0,23 |
0,23 |
0,23 |
|
Номинальные токи, А |
|
|
|
|
|
|
|||
|
ВН |
5,5 (9,16) |
13,7 (22,9) |
22 (36,6) |
34,6 (57,7) |
55 (91,6) |
68. |
88 (146,6) |
110 |
137,5 (229) |
|
НН |
251 |
628 |
1004 |
1581 |
2510 |
3138 |
4016 |
5020 | 6276 |
|
Схема и группа соединения обмоток |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 | Ун/Д – 11 |
 7
7
Таблица 2 — Основные технические параметры трансформаторов 20 кВ.
|
Наименование параметра |
Значения |
||
|
Номинальная мощность, кВ·А |
250 |
630 |
1000 |
|
Номинальная частота, Гц |
50 |
50 |
50 |
|
Номинальные напряжения, кВ |
|
|
|
|
ВН |
21 |
21 |
21 |
|
НН |
0,23 |
0,23 |
0,23 |
|
Номинальные токи, А |
|
|
|
|
ВН |
6,9 |
17,3 |
27,5 |
|
НН |
628 |
1581 |
2510 |
|
Схема и группа соединения обмоток |
Ун/Д – 11 |
Ун/Д – 11 |
Ун/Д – 11 |
Таблица 3 — Габаритные и установочные размеры трансформаторов.
|
Тип |
Размеры, мм, не более |
||||
|
А |
А1 |
В |
Н |
L |
|
|
ТМПС-100 |
550 |
550 |
740 |
1170 |
940 |
|
ТМПС-250 |
550 |
550 |
1010 |
1340 |
1190 |
|
ТМПС-400 |
660 |
660 |
1025 |
1430 |
1395 |
|
ТМПС-630 |
660 |
660 |
1090 |
1540 |
1585 |
|
ТМПС-1000 |
820 |
820 |
1135 |
1860 |
1720 |
|
ТМПС-1250 |
820 | 820 | 1250 | 2020 | 1825 |
|
ТМПС-1600 |
820 | 820 | 1285 | 2170 | 2225 |
|
ТМПС-2000 |
1070 | 1070 | 1365 | 1990 | 2285 |
|
ТМПС-2500 |
1070 | 1070 | 1450 | 2380 | 2370 |
Таблица 4 — Масса трансформаторов.
|
Тип |
Масса, кг не более |
||
|
Масло |
Активная часть |
Общая |
|
|
ТМПС-100 |
125 |
300 |
540 |
|
ТМПС-250 |
270 |
585 |
1100 |
|
ТМПС-400 |
350 |
800 |
1400 |
|
ТМПС-630 |
450 |
1200 |
1860 |
|
ТМПС-1000 |
725 |
1700 |
2750 |
|
ТМПС-1250 |
875 |
1850 |
3250 |
|
ТМПС-1600 |
1170 |
2000 |
4250 |
|
ТМПС-2000 |
1200 |
2300 |
4500 |
|
ТМПС-2500 |
1800 |
2600 |
6680 |
Таблица 5 — Типовые значения технических параметров трансформаторов.
|
Наименование параметра |
Значение |
||||||||
|
Номинальная мощность, кВ·А |
100 |
250 |
400 |
630 |
1000 |
1250 |
1600 |
2000 |
2500 |
|
Потери короткого замыкания, Вт |
2130 |
3450 |
5980 |
9050 |
12650 |
18650 |
21300 |
27970 |
31980 |
|
Потери холостого хода, Вт |
330 |
460 |
790 |
1050 |
1470 |
1950 |
2300 |
2720 |
3350 |
|
Напряжение короткого замыкания, % |
4,5 |
4,5 |
4,5 |
5,5 |
5,5 |
6,0 |
6,0 |
6,0 |
6,0 |
|
Ток холостого хода, % |
2,0 |
1,4 |
1,3 |
1,2 |
0,9 |
2,0 |
1,0 |
1,0 |
0,8 |
Структура условного обозначения
Комплектность поставки
- Трансформатор силовой – 1 шт.

- Паспорт – 1 экз.
- Руководство по эксплуатации – 1 экз.
- Электроконтактный термометр — 1 шт. для трансформаторов мощностью 875, 1000, 1600, 2500 кВА.
- Мановакуумметр – 1 шт. для трансформаторов мощностью 875, 1000, 1600, 2500 кВА.
- Катки для трансформаторов поставляются по требованию Заказчика.
Гарантия изготовителя
Гарантийный срок устанавливается 60 месяцев (5 лет) с момента отгрузки потребителю.
Обмотки ВН и НН — Проектэлектротехника
г. Москва, ул. Кузнецкий мост, дом 21/5 [email protected]Обратный звонок +7 (8352) 23-70-20
О компании— Качество работ и услуг— НовостиПродукция— Сухие трансформаторы—— Распределительные трансформаторы—— Преобразовательные трансформаторы—— Трансформаторы морского исполнения —— Сухие трансформаторы с литой изоляцией—— Сухие трансформаторы мощностью 10 кВА—— Трехфазные трансформаторы— Специальные трансформаторы— Обмотки ВН и НН— Реакторное оборудование— Комплектные трансформаторные подстанции— Передвижные КТП на шасси— Электротехнические блок-боксы— Аксессуары под заказ— Защитные кожухи для трансформаторов — Дизельные электроагрегаты и электростанции—— Электростанции АД30-Т400—— Электростанции АД100-Т400—— Дизельные электроагрегаты серии АД—— Дизельные электроcтанции серии АД—— Передвижные дизельные электростанции—— Электроагрегат АД8-Т400-1, 2, 3Р (П)—— ЭЛЕКТРОАГРЕГАТ ДИЗЕЛЬНЫЙ АД16-Т400-1, 2, 3Р—— Электроагрегат АД20-Т400-1, 2, 3Р (П)—— Электроагрегат АД30-Т400-1, 2, 3Р (П)—— Электроагрегат АД50-Т400-1, 2, 3Р (П)—— Электроагрегат АД60-Т400-1, 2, 3Р (П)—— Электроагрегат АД100-Т400-1, 2, 3Р (П)—— Электроагрегат АД200-Т400-1, 2, 3Р (П)—— Электростанция ЭД30-Т400-1РПУ1—— Электростанция ЭД2х60-Т400-1, 2, 3РН—— Электростанция ЭД2х100-Т400-1, 2, 3РН—— Электростанция ЭД200-Т400-1, 2, 3РН— Сетевые накопители энергии— Контроллер управления «Вектор Э»— Проходные изоляторы трансформатора— Трансформаторные подстанции— Силовые трансформаторы— Виброгасители для трансформаторовУслуги— Ремонт силовых трансформаторовСкладOn-line заявкаОбъявленияПартнерам— Наши заказчики— ОтзывыКонтакты
- О компании
- Продукция
- Сухие трансформаторы
- Специальные трансформаторы
- Обмотки ВН и НН
- Реакторное оборудование
- Комплектные трансформаторные подстанции
- Передвижные КТП на шасси
- Электротехнические блок-боксы
- Аксессуары под заказ
- Защитные кожухи для трансформаторов
- Дизельные электроагрегаты и электростанции
- Электростанции АД30-Т400
- Электростанции АД100-Т400
- Дизельные электроагрегаты серии АД
- Дизельные электроcтанции серии АД
- Передвижные дизельные электростанции
- Электроагрегат АД8-Т400-1, 2, 3Р (П)
- ЭЛЕКТРОАГРЕГАТ ДИЗЕЛЬНЫЙ АД16-Т400-1, 2, 3Р
- Электроагрегат АД20-Т400-1, 2, 3Р (П)
- Электроагрегат АД30-Т400-1, 2, 3Р (П)
- Электроагрегат АД50-Т400-1, 2, 3Р (П)
- Электроагрегат АД60-Т400-1, 2, 3Р (П)
- Электроагрегат АД100-Т400-1, 2, 3Р (П)
- Электроагрегат АД200-Т400-1, 2, 3Р (П)
- Электростанция ЭД30-Т400-1РПУ1
- Электростанция ЭД2х60-Т400-1, 2, 3РН
- Электростанция ЭД2х100-Т400-1, 2, 3РН
- Электростанция ЭД200-Т400-1, 2, 3РН
- Сетевые накопители энергии
- Контроллер управления «Вектор Э»
- Проходные изоляторы трансформатора
- Трансформаторные подстанции
- Силовые трансформаторы
- Услуги
- Склад
- On-line заявка
- Объявления
- Партнерам
- Контакты
КТПН: расшифровка и условия эксплуатации
Комплектная трансформаторная подстанция наружной установки (КТПН) предназначена для приема, преобразования и распределения электрической энергии трехфазного переменного тока частотой 50 Гц.
Подстанции этого типа удобны в эксплуатации, не требуют постоянного ухода, имеют небольшой размер и являются оптимальным решением для размещения на улице. Основные технические характеристики отражены в маркировке оборудования. Владение этой информацией поможет вам подобрать подходящую подстанцию.
Содержание:
Устройство оборудования
КТПН состоит из модулей, являющиеся каркасной конструкцией из металла, внутри которой установлены главные и дополнительные устройства. Стены модуля сделаны из стального листа и окрашены порошковой полимерной краской. Размеры модуля обусловлены монтируемыми в него устройствами и общими решениями компоновки подстанции.
Назначение оборудования
КТПН нужны для приема, преобразования и распределения электроэнергии конечным потребителям. Применяют для снабжения электроэнергией объектов различных отраслей промышленности:
- нефтяной;
- газовой;
- горнорудной.
Комплектация КТПН
Оборудование состоит из нескольких узлов:
|

У КТПН есть и другие достоинства:
- их можно комплектовать дополнительным оборудованием для решения тех или иных задач;
- они мобильны, их можно транспортировать как полностью собранными, так и в виде отдельных блоков;
- благодаря наличию систем защиты они безопасны в эксплуатации.
Маркировка КТПН
Условные знаки, нанесенные на корпус подстанции, заключают в себе все сведения о ее устройстве. Их расшифровка помогает получить информацию не только о названии комплекса, но и типе его исполнения и соединения, числе и мощности установленных трансформаторов. Отмечаются номиналы высокого и низкого напряжения на входе и выходе. Код заканчивается на информации о категории размещения и климатическом исполнении.
Код заканчивается на информации о категории размещения и климатическом исполнении.
Расшифровка условного обозначения на примере: 2 КТПН -()-630/ 10 /0.4-4-У1
2 | Число силовых трансформаторовСТ (если 1 – не обозначается) |
КТПН — | Комплектная Трансформаторная ПодстанцияТ-тупикового; |
() | ● Т-тупикового; |
630 | Мощность силового трансформатора в кВА |
10 | Класс напряжения трансформатора в кВ |
0,4 | Номинальное напряжение на стороне НН в кВ |
У1 | Тип климатическое исполнение |
КТПН 25; 40; 63; 100; 160; 250; 400; 630; 1000; 1250; 1600; 2000; 2500; 3150; 4000 предназначены для электроснабжения промышленных, коммерческих, гражданских объектов. Обеспечивают преобразование электроэнергии в трехфазных сетях с номинальным напряжением 6 или 10 кВ в энергию 0,23/0,4/0,6/0,69 кВ. Модификации на 600 и 690 вольт по низкой стороне выпускаются по индивидуальным заказам.
Обеспечивают преобразование электроэнергии в трехфазных сетях с номинальным напряжением 6 или 10 кВ в энергию 0,23/0,4/0,6/0,69 кВ. Модификации на 600 и 690 вольт по низкой стороне выпускаются по индивидуальным заказам.
В КТПН-К все элементы оборудования размещены в одном корпусе. КТПН-Б представляет собой блочно-модульные здания. При необходимости их состав можно менять, гибко подстраивая комплектацию оборудования под требования Клиента.
Условия ввода в эксплуатацию
При проверке установки новой ТП проверяющая комиссия сначала сверяет параметры, указанные в инструкции по вводу в эксплуатацию КТПН:
- Присутствие нумерации, находящейся на баках и дверях трансформаторов, с помощью которых уменьшается риск неверного использования. Двери трансформаторных помещений должны быть оснащены надписями, сообщающими об опасности, которой подвергается человек при подходе к трансформатору.
- Трансформаторы, мощность которых выше 1000 кВА, должны оснащаться амперметрами для контроля нагрузки, а также термометрами, определяющими температуру масла.

- Инструкция по вводу в эксплуатацию КТПН предполагает присутствие на кнопках, ручках и ключах управления текстовых табличек, указывающих на совершаемые ими действия (включить, отключить, добавить, убавить). Также устройство должно иметь контрольные лампы с надписями, идентифицирующимихарактеризующими сигнал.
- Жилы кабелей и проводов, подсоединяющиеся к клеммам, должны иметь запас длины для повторного подсоединения жил к зажиму при случайном обрыве.
- Щит управления должен иметь запасные предохранители и контрольные лампы, инструменты, фонари, огнетушители, аптечки, ключи от всех комнат.
- Двери аккумуляторных камер должны иметь предупреждающие надписи: «Аккумуляторная», «Не курить».
- В аккумуляторном помещении лампы накаливания должны располагаться в светильниках, имеющих взрывозащищенное исполнение.
- Все конденсаторы должны быть обозначены краской. Номер должен быть записан на стенке бака, направленной к коридору обслуживания.
Подключение оборудования
КТПН устанавливаются на фундамент (монолитный ленточный, свайный, плитный). Такой метод является трудоемким и используется при плюсовых температурах окружающей среды. Если нужно установить подстанцию на грунт (бетонную, асфальтовую площадку), то КТПН должна быть на особой раме или понтоне. |
При установке КТПН необходимо учитывать следующие рекомендации:
- фундамент должен располагаться на 0,2–1,5 м от земли для исключения случайного затопления;
- число закладных труб для вводов и выводов кабельных линий должно быть выше проектного на 50%;
- система заземления должна согласовываться с проектом установки и ПУЭ;
- подключают конструкцию после окончания установочных работ.
До эксплуатации нужно совершить ряд пусконаладочных работ, предусмотренных разработчиком и соответствующих требованиям электрической безопасности.
Правила эксплуатации КТПН
Подстанция рассчитана на круглогодичную работу при следующих условиях:
- температура воздуха от -45 до +40°С для У1 и от -60 до +40°С для УХЛ1;
- влажность воздуха при +15°С – не выше 75%;
- высота расположения над уровнем моря — не больше 1000 м;
- атмосферное давление — 86,6 — 106,7 кПа;
- сейсмичность — до 9 баллов (шкала MSK-64) по ГОСТ 17516.1;
- в стандартном исполнении может монтироваться в условиях промышленной атмосферы, не имеющей в составе вредных веществ, которые могут проесть изоляцию или подвергнуть коррозии металлические составляющие подстанции, сформировать взрывоопасную концентрацию пыли.
Если соблюдение всех этих параметров невозможно, для преобразования электроэнергии нужно выбрать иные виды подстанций, созданные для использования в особых условиях.
Специалисты нашей компании произведут, смонтируют и выполнят пусконаладку КТПН различной комплектации. Применение КТПН упрощает и удешевляет подключение потребителей электроэнергии при наличии доступа только к высоковольтной сети. Мы гарантируем оперативный монтаж и подключение. Наше оборудование полностью безопасно при эксплуатации на открытых площадках в умеренных и холодных климатических условиях.
Общие сведения Трансформатор силовой масляный трехфазный трехобмоточный типа ТДТН-63000/110 У1 наружной установки, с регулированием напряжения в обмотке ВН под нагрузкой (РПН) в пределах + 9×1,78% номинального напряжения и с регулированием напряжения на стороне СН — 35 кВ при отключенном трансформаторе (ПБВ) в пределах + 2×2,5% номинального напряжения, предназначен для работы в сетях с глухозаземленной нейтралью. Структура условного обозначения ТДТН-63000/110 У1: Условия эксплуатации Высота над уровнем моря не более 1 000 м. В открытых электроустановках. Среднесуточная температура окружающего воздуха не более 30°С, среднегодовая — не более 20°С. Требования техники безопасности по ГОСТ 12.2.003-74, ГОСТ 12.2.007.2-75, ГОСТ 12.2.024-76, ГОСТ 12.1.004-91. Трансформатор соответствует ГОСТ 12965-93. ГОСТ 12965-93 Технические характеристики Конструкция и принцип действия Активная часть трансформатора, состоящая из остова, обмоток, изоляции, отводов с регулятором напряжения РПН и переключателями ПБВ, устанавливается в бак. Остов трансформатора однорамный, трехстержневой, собран из листов холоднокатаной электротехнической стали. Стержни остова стягиваются бандажами из стеклоленты, а ярма — ярмовыми балками и стальными полубандажами. Верхние и нижние ярмовые балки стянуты между собой стальными шпильками. Обмотки цилиндрические концентрически размещены на стержнях остова. Обмотка СН размещается между обмотками НН и ВН. Регулировочная обмотка — наружная. Изоляция обмоток — маслобарьерного типа. Встроенные трансформаторы тока предназначены для максимальной и дифференциальной токовой защиты и приборов измерения. Трансформатор снабжен на линейных вводах ВН двумя трансформаторами тока ТВТ-110, на нейтральном вводе ВН — двумя трансформаторами тока ТВТ-35, на линейных вводах СН — 38,5 кВ — двумя трансформаторами тока ТВТ-35. Трансформатор охлаждается радиаторами, каждый из которых обдувается двумя вентиляторами. Мощность электродвигателя типа 4АА63АЧТрУ1 вентиляторов охлаждения равна 0,25 кВт. Трансформатор снабжен шкафом автоматического управления дутьем типа ШД-2. Дутьевая установка питается от трехфазной сети напряжением 380 В. Активная часть трансформатора поднимается за кронштейны на верхних ярмовых балках, а полностью собранный трансформатор — за подъемные приспособления на баке. Бак трансформатора колокольного типа, сварной, снабжен арматурой для заливки, слива трансформаторного масла и взятия проб, подключения маслоочистительной установки и вакуум-насоса в соответствии с ГОСТ 12965-93. На баке устанавливаются защитные устройства, приборы контроля температуры масла, приводы РПН и ПБВ. На крышке бака установлены: расширитель, имеющий стрелочный маслоуказатель, вводы «О» СН, «О» ВН, НН, СН, ВН, регулятор напряжения РПН. Расширитель соединяется трубопроводом с баком трансформатора. Габаритные и установочные размеры трансформатора приведены на рис. 1, расположение и размеры вводов — на рис. 2 и в таблице. Рис. 1. Общий вид, габаритные и установочные размеры трансформатора типа ТДТН-63000/110 У1: 1 — бак;2 — ввод НН; 3 — ввод ВН; 4 — ввод СН; 5 — ввод О ВН; 6 — ввод О СН; 7 — расширитель; 8 — регулятор напряжения РПН Рис. 2. Расположение вводов СН — 11 кВ на крышке бакаТабл. В комплект поставки входят: трансформатор, запасные части в соответствии с ведомостью ЗИП изготовителя, эксплуатационная документация.Центр комплектации «СпецТехноРесурс» |
Иллюстрированное руководство по трансформаторам — пошаговое объяснение | Майкл Фи
Трансформаторы штурмом захватывают мир обработки естественного языка. Эти невероятные модели бьют множество рекордов НЛП и продвигают новейшие разработки. Они используются во многих приложениях, таких как машинный перевод, разговорные чат-боты и даже для улучшения поисковых систем. Трансформаторы сейчас в моде в области глубокого обучения, но как они работают? Почему они превзошли предыдущего короля проблем последовательности, такого как рекуррентные нейронные сети, GRU и LSTM? Вы, наверное, слышали о различных известных моделях трансформеров, таких как BERT, GPT и GPT2.В этом посте мы сосредоточимся на одной статье, с которой все началось: «Внимание — это все, что вам нужно».
Перейдите по ссылке ниже, если вы хотите вместо этого посмотреть видеоверсию.
Чтобы понять трансформаторов, мы сначала должны понять механизм внимания. Механизм внимания позволяет трансформаторам иметь чрезвычайно долгую память. Модель-трансформер может «присутствовать» или «фокусироваться» на всех ранее сгенерированных токенах.
Давайте рассмотрим пример. Допустим, мы хотим написать небольшой научно-фантастический роман с генеративным преобразователем.Мы можем сделать это с помощью приложения Write With Transformer от Hugging Face. Мы заполним модель нашими входными данными, а модель сгенерирует все остальное.
Наш вклад: «Когда пришельцы вошли на нашу планету».
Выход трансформатора: «и начала колонизацию Земли, определенная группа инопланетян начала манипулировать нашим обществом через свое влияние определенного числа элиты, чтобы удерживать и железной хваткой над населением».
Хорошо, история немного мрачная, но что интересно, так это то, как модель ее сгенерировала.По мере того как модель генерирует текст слово за словом, она может «следить» или «фокусироваться» на словах, которые имеют отношение к сгенерированному слову. Способность знать, какие слова следует посещать, также усваивается во время обучения посредством обратного распространения ошибки.
Механизм внимания, фокусирующийся на разных токенах при генерации слов 1 на 1Рекуррентные нейронные сети (RNN) также могут просматривать предыдущие входные данные. Но сила механизма внимания в том, что он не страдает от кратковременной памяти. У RNN более короткое окно для ссылки, поэтому, когда история становится длиннее, RNN не может получить доступ к словам, сгенерированным ранее в последовательности.Это по-прежнему верно для сетей с закрытыми рекуррентными модулями (GRU) и долгосрочной краткосрочной памятью (LSTM), хотя они обладают большей емкостью для достижения долговременной памяти, следовательно, имеют более длительное окно для ссылки. Механизм внимания теоретически и при наличии достаточных вычислительных ресурсов имеет бесконечное окно, из которого можно ссылаться, поэтому он может использовать весь контекст истории при создании текста.
Гипотетическое справочное окно Attention, RNN, GRU и LSTMСила механизма внимания была продемонстрирована в статье «Внимание — это все, что вам нужно», где авторы представили новую новую нейронную сеть под названием Transformers, которая является кодировщиком на основе внимания. архитектура типа декодера.Модель преобразователя
На высоком уровне кодер преобразует входную последовательность в абстрактное непрерывное представление, которое содержит всю изученную информацию этого входа. Затем декодер принимает это непрерывное представление и шаг за шагом генерирует один вывод, одновременно передавая предыдущий вывод.
Давайте рассмотрим пример. В статье модель Transformer применялась к задаче нейронного машинного перевода. В этом посте мы продемонстрируем, как это работает для разговорного чат-бота.
Наш ввод: «Привет, как дела»
Вывод трансформатора: «Я в порядке»
Первым шагом является подача ввода в слой встраивания слов. Слой встраивания слов можно рассматривать как таблицу поиска, чтобы получить изученное векторное представление каждого слова. Нейронные сети обучаются с помощью чисел, поэтому каждое слово отображается в вектор с непрерывными значениями для представления этого слова.
преобразование слов во входные вложенияСледующим шагом является введение позиционной информации во вложения.Поскольку кодировщик-преобразователь не имеет повторения, как рекуррентные нейронные сети, мы должны добавить некоторую информацию о позициях во входные вложения. Это делается с помощью позиционного кодирования. Авторы придумали хитрый трюк, используя функции sin и косинус.
Мы не будем вдаваться в математические подробности позиционного кодирования, но вот основы. Для каждого нечетного индекса входного вектора создайте вектор с помощью функции cos. Для каждого четного индекса создайте вектор с помощью функции sin.Затем добавьте эти векторы к их соответствующим входным вложениям. Это успешно дает сети информацию о положении каждого вектора. Функции sin и косинус были выбраны в тандеме, потому что они обладают линейными свойствами, которым модель может легко научиться уделять внимание.
Теперь у нас есть слой кодировщика. Задача слоев Encoders состоит в том, чтобы отобразить все входные последовательности в абстрактное непрерывное представление, которое содержит изученную информацию для всей этой последовательности. Он содержит 2 подмодуля, многоголовое внимание, за которым следует полностью подключенная сеть.Также существуют остаточные связи вокруг каждого из двух подслоев, за которыми следует нормализация уровня.
Субмодули уровня кодировщикаЧтобы разобраться в этом, давайте сначала рассмотрим модуль многоголового внимания.
Многоголовое внимание в кодировщике применяет особый механизм внимания, называемый самовниманием. Самовнимание позволяет моделям связывать каждое слово во входных данных с другими словами. Итак, в нашем примере наша модель может научиться ассоциировать слово «вы» с «как» и «есть».Также возможно, что модель узнает, что слова, структурированные по этому шаблону, обычно являются вопросом, поэтому отвечайте соответствующим образом.
Encoder Self-Attention Operations. Ссылка на это при просмотре иллюстраций ниже.Векторы запроса, ключа и значения
Чтобы добиться самовнимания, мы передаем входные данные в 3 отдельных полностью связанных слоя для создания векторов запроса, ключа и значения.
Что именно это за векторы? Я нашел хорошее объяснение по обмену стеками, в котором говорится….
«Концепция ключа и значения запроса исходит из поисковых систем. Например, когда вы вводите запрос для поиска некоторого видео на Youtube, поисковая система сопоставляет ваш запрос с набором ключей (заголовок видео, описание и т. Д.), Связанных с видео кандидатов в базе данных, затем представим вам наиболее подходящие видео ( значения ).
Точечное произведение запроса и ключа
После подачи вектора запроса, ключа и значения через линейный слой запросы и ключи подвергаются умножению матрицы скалярного произведения для создания матрицы оценок.
Умножение скалярного произведения запроса и ключаМатрица оценок определяет, насколько большое внимание следует уделять слову другие слова. Таким образом, каждое слово будет иметь оценку, соответствующую другим словам на временном шаге. Чем выше оценка, тем больше внимания. Вот как запросы сопоставляются с ключами.
Оценка внимания от скалярного произведения.Уменьшение оценок внимания
Затем оценки уменьшаются путем деления на квадратный корень из измерения запроса и ключа.Это сделано для обеспечения более стабильных градиентов, так как умножение значений может иметь взрывной эффект.
Уменьшение оценок вниманияSoftmax масштабированных оценок
Затем вы берете softmax масштабированной оценки, чтобы получить веса внимания, что дает вам значения вероятности от 0 до 1. Выполняя softmax, повышаются более высокие оценки, и более низкие баллы подавлены. Это позволяет модели быть более уверенной в выборе слов.
Взятие softmax масштабированных оценок для получения значений вероятностиУмножение выходных данных Softmax на вектор значений
Затем вы берете веса внимания и умножаете их на свой вектор значений, чтобы получить вектор выходных данных.Более высокие баллы softmax сохранят ценность слов, которые модель выучила более важными. Более низкие баллы заглушают неуместные слова. Затем вы передаете результат в линейный слой для обработки.
Чтобы сделать это вычисление многоголового внимания, вам нужно разделить запрос, ключ и значение на N векторов, прежде чем применять самовнимание. Затем расщепленные векторы индивидуально проходят процесс самовнимания. Каждый процесс самовнимания называется головой. Каждая голова создает выходной вектор, который объединяется в один вектор перед прохождением последнего линейного слоя.Теоретически каждая голова будет изучать что-то свое, что дает модели кодировщика большую репрезентативную способность.
Разделение Q, K, V, N раз перед применением самовниманияПодводя итог, многоголовое внимание — это модуль в трансформаторной сети, который вычисляет веса внимания для входа и создает выходной вектор с закодированной информацией о том, как каждое слово должно соответствовать всем другим словам в последовательности.
Выходной вектор многоголового внимания добавляется к исходному позиционному встраиванию входных данных.Это называется остаточной связью. Вывод остаточного соединения проходит через нормализацию слоя.
Остаточное соединение позиционного встраивания ввода и вывода многоголового вниманияНормализованный остаточный вывод проецируется через точечную сеть с прямой связью для дальнейшей обработки. Точечная сеть с прямой связью представляет собой пару линейных слоев с активацией ReLU между ними. Выходной сигнал затем снова добавляется к входу точечной сети с прямой связью и далее нормализуется.
Остаточное соединение входа и выхода точечного прямого слоя.Остаточные соединения помогают обучению сети, позволяя градиентам проходить через сети напрямую. Нормализация слоев используется для стабилизации сети, что приводит к существенному сокращению необходимого времени обучения. Слой точечной упреждающей связи используется для проецирования выходных данных внимания, потенциально давая им более богатое представление.
Это завершает слой кодировщика. Все эти операции предназначены для кодирования входных данных в непрерывное представление с информацией о внимании.Это поможет декодеру сосредоточиться на соответствующих словах во вводе во время процесса декодирования. Вы можете складывать кодер N раз для дальнейшего кодирования информации, при этом каждый уровень имеет возможность изучать различные представления внимания, что потенциально увеличивает предсказательную мощность трансформаторной сети.
Задача декодера — генерировать текстовые последовательности. Декодер имеет такой же подуровень, что и кодер. он имеет два многоголовых слоя внимания, слой с точечной прямой связью и остаточные связи, а также нормализацию уровня после каждого подуровня.Эти подуровни ведут себя аналогично уровням в кодировщике, но каждый многоглавый уровень внимания выполняет свою работу. Декодер завершается линейным слоем, который действует как классификатор, и softmax для получения вероятностей слов.
Слой декодера. Ссылка на эту диаграмму при чтении.Декодер является авторегрессионным, он начинается со стартового токена и принимает список предыдущих выходов в качестве входов, а также выходы кодировщика, которые содержат информацию о внимании из входа.Декодер прекращает декодирование, когда генерирует токен в качестве вывода.
Декодер является авторегрессионным, так как он генерирует токен 1 за раз, подавая его на предыдущие выходы.Давайте пройдемся по этапам декодирования.
Начало декодера почти такое же, как у кодировщика. Входные данные проходят через слой внедрения и слой позиционного кодирования, чтобы получить позиционные вложения. Позиционные вложения вводятся в первый слой внимания с несколькими головами, который вычисляет оценки внимания для входных данных декодера.
Этот многоглавый слой внимания работает несколько иначе. Поскольку декодер является авторегрессионным и генерирует последовательность слово за словом, вам необходимо предотвратить его преобразование в будущие токены. Например, при вычислении оценки внимания к слову «я» у вас не должно быть доступа к слову «отлично», потому что это слово является будущим словом, которое было сгенерировано после. Слово «am» должно иметь доступ только к самому себе и к словам перед ним. Это верно для всех других слов, где они могут относиться только к предыдущим словам.
Изображение первого многоголового внимания декодера по шкале оценки внимания. Слово «am» не должно иметь никаких значений для слова «штраф». Это верно для всех остальных слов.Нам нужен метод, предотвращающий вычисление оценок внимания для будущих слов. Этот метод называется маскированием. Чтобы декодер не смотрел на будущие токены, вы применяете маску просмотра вперед. Маска добавляется перед вычислением softmax и после масштабирования оценок. Давайте посмотрим, как это работает.
Маска упреждения
Маска — это матрица того же размера, что и оценки внимания, заполненная значениями 0 и отрицательной бесконечностью.Когда вы добавляете маску к шкале оценок внимания, вы получаете матрицу оценок, в которой верхний правый треугольник заполнен бесконечностями негатива.
Добавление маски упреждающего просмотра к масштабированным оценкамПричина использования маски в том, что как только вы берете softmax замаскированных оценок, отрицательные бесконечности обнуляются, оставляя нулевые оценки внимания для будущих токенов. Как вы можете видеть на рисунке ниже, оценка внимания для «am» имеет значения для себя и всех слов перед ним, но равна нулю для слова «хорошо».По сути, это говорит модели не акцентировать внимание на этих словах.
Это маскирование — единственное отличие в том, как рассчитываются оценки внимания в первом многоглавом слое внимания. Этот слой по-прежнему имеет несколько головок, к которым применяется маска, прежде чем они будут объединены и пропущены через линейный слой для дальнейшей обработки. Результатом первого многоголового внимания является замаскированный выходной вектор с информацией о том, как модель должна присутствовать на входе декодера.
Многоголовое внимание с маскированиемВторой слой многоголового внимания.Для этого уровня выходными данными кодировщика являются запросы и ключи, а выходными данными первого многоголового уровня внимания являются значения. Этот процесс сопоставляет вход кодера со входом декодера, позволяя декодеру решить, на какой вход кодера следует обратить внимание. Результат второго многоголового внимания проходит через точечный слой прямой связи для дальнейшей обработки.
Выходные данные последнего поточечного слоя с прямой связью проходят через последний линейный слой, который действует как классификатор.Классификатор такой же большой, как и количество имеющихся у вас классов. Например, если у вас есть 10 000 классов для 10 000 слов, вывод этого классификатора будет иметь размер 10 000. Выходные данные классификатора затем передаются в слой softmax, который дает оценки вероятности от 0 до 1. Мы берем индекс наивысшей оценки вероятности, который равен нашему предсказанному слову.
Линейный классификатор с Softmax для получения вероятностей выводаЗатем декодер берет вывод, добавляет его в список входов декодера и снова продолжает декодирование, пока не будет предсказан токен.В нашем случае предсказание с наивысшей вероятностью — это последний класс, который назначается конечному токену.
Декодер также может быть наложен на N уровней, каждый из которых принимает входные данные от кодера и предшествующих ему слоев. Сложив слои, модель может научиться извлекать и сосредотачиваться на различных комбинациях внимания из своих головок внимания, потенциально повышая ее способность к прогнозированию.
Кодировщик и декодер с накоплениемИ все! Такова механика трансформаторов.Трансформаторы используют силу механизма внимания, чтобы делать более точные прогнозы. Рекуррентные нейронные сети пытаются добиться аналогичных результатов, но потому, что они страдают от кратковременной памяти. Трансформаторы могут быть лучше, особенно если вы хотите кодировать или генерировать длинные последовательности. Благодаря архитектуре преобразователя индустрия обработки естественного языка может достичь беспрецедентных результатов.
Посетите michaelphi.com, чтобы найти больше подобного контента.
Модели кодировщика-декодера на базе трансформатора
! Pip install трансформаторы == 4.2.1
! pip install фраза == 0.1.95
Модель кодера-декодера на основе трансформатора была представлена Васвани. и другие. в знаменитом Attention — это все, что вам нужно бумага и сегодня де-факто стандартная архитектура кодера-декодера при обработке естественного языка (НЛП).
В последнее время было проведено много исследований различных предтренировочных объективы для моделей кодеров-декодеров на базе трансформаторов, например Т5, Барт, Пегас, ProphetNet, Мардж, и т. Д. …, но модель архитектуры остался в основном прежним.
Цель сообщения в блоге — дать подробное описание как моделирует архитектуру кодера-декодера на основе трансформатора от последовательности к последовательности проблем. Сфокусируемся на математической модели определяется архитектурой и тем, как модель может использоваться для вывода. Попутно мы дадим некоторую справочную информацию о последовательности в последовательность. модели в NLP и разбить кодировщик-декодер на базе трансформатора архитектура в его кодировщика и декодера частей.Мы предоставляем много иллюстрации и установить связь между теорией модели кодеров-декодеров на базе трансформаторов и их практическое применение в 🤗Трансформаторы для вывода. Обратите внимание, что это сообщение в блоге не объясняет , а не . как такие модели можно обучить — это тема будущего блога Почта.
Модели кодеров-декодеров на базе трансформаторов являются результатом многолетней Исследование представлений , изучение архитектур моделей и . Этот блокнот содержит краткое изложение истории нейронных кодировщики-декодеры модели.Для получения дополнительной информации читателю рекомендуется прочитать этот замечательный блог опубликовать Себастион Рудер. Кроме того, базовое понимание рекомендуется архитектура с самовниманием . Следующее сообщение в блоге автора Джей Аламмар служит хорошим напоминанием об оригинальной модели Transformer. здесь.
На момент написания этого блокнота «Трансформеры включают кодировщики-декодеры моделей T5 , Bart , MarianMT и Pegasus , которые кратко описаны в документации по модели резюме.
Ноутбук разделен на четыре части:
- Предпосылки — Краткая история моделей нейронных кодировщиков-декодеров дается с акцентом на модели на основе RNN.
- Кодер-декодер — Модель кодера-декодера на основе трансформатора представлена и объясняется, как модель используется для вывод.
- Энкодер — Энкодер модели поясняется в деталь.
- Декодер — Декодерная часть модели поясняется в деталь.
Каждая часть основана на предыдущей части, но также может быть прочитана на ее собственный.
ФонЗадачи генерации естественного языка (NLG), подполе NLP, являются лучшими выражаются как задачи от последовательности к последовательности. Такие задачи можно определить как поиск модели, которая отображает последовательность входных слов в последовательность целевые слова. Некоторые классические примеры — это обобщение и перевод . Далее мы предполагаем, что каждое слово закодировано в векторное представление.входные слова nnn могут быть представлены как последовательность входных векторов nnn:
X1: n = {x1,…, xn}. \ Mathbf {X} _ {1: n} = \ {\ mathbf {x} _1, \ ldots, \ mathbf {x} _n \}. X1: n = {x1,…, xn}.
Следовательно, проблемы от последовательности к последовательности могут быть решены путем нахождения отображение fff из входной последовательности nnn векторов X1: n \ mathbf {X} _ {1: n} X1: n в последовательность целевых векторов mmm Y1: m \ mathbf {Y} _ {1: m} Y1: m, тогда как число векторов-мишеней ммм априори неизвестен и зависит от входных данных последовательность:
f: X1: n → Y1: m.22 для решения задач от последовательности к последовательности следовательно, означает, что необходимо знать количество целевых векторов mmm apriori и должен быть независимым от ввода X1: n \ mathbf {X} _ {1: n} X1: n. Это неоптимально, потому что для задач в NLG количество целевых слов обычно зависит от ввода X1: n \ mathbf {X} _ {1: n} X1: n и не только на входной длине nnn. Например. , статья 1000 слов можно суммировать как до 200 слов, так и до 100 слов в зависимости от его содержание.
В 2014 г. Cho et al.33. После обработки последнего входного вектора xn \ mathbf {x} _nxn, Скрытое состояние кодировщика определяет входную кодировку c \ mathbf {c} c. Таким образом, кодировщик определяет отображение:
fθenc: X1: n → c. f _ {\ theta_ {enc}}: \ mathbf {X} _ {1: n} \ to \ mathbf {c}. fθenc: X1: n → c.
Затем скрытое состояние декодера инициализируется входной кодировкой. и во время логического вывода декодер RNN используется для авторегрессивного генерировать целевую последовательность. Поясним.
Математически декодер определяет распределение вероятностей целевая последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m с учетом скрытого состояния c \ mathbf {c} c:
pθdec (Y1: m∣c).{m} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}). pθdec (Y1: m ∣c) = i = 1∏m pθdec (yi ∣Y0: i − 1, c).
Таким образом, если архитектура может моделировать условное распределение следующий целевой вектор, учитывая все предыдущие целевые векторы:
pθdec (yi∣Y0: i − 1, c), ∀i∈ {1,…, m}, p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}), \ forall i \ in \ {1, \ ldots, m \}, pθdec (yi ∣Y0: i − 1, c), ∀ i∈ {1,…, m},
, то он может моделировать распределение любой последовательности целевого вектора, заданной скрытое состояние c \ mathbf {c} c путем простого умножения всех условных вероятности.
Так как же модель архитектуры декодера на основе RNN pθdec (yi∣Y0: i − 1, c) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ { 0: i-1}, \ mathbf {c}) pθdec (yi ∣Y0: i − 1, c)?
С точки зрения вычислений, модель последовательно отображает предыдущий внутренний скрытое состояние ci − 1 \ mathbf {c} _ {i-1} ci − 1 и предыдущий целевой вектор yi \ mathbf {y} _iyi до текущего внутреннего скрытого состояния ci \ mathbf {c} _ici и a вектор logit li \ mathbf {l} _ili (показано темно-красным цветом ниже):
fθdec (yi − 1, ci − 1) → li, ci.f _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _ {i-1}, \ mathbf {c} _ {i-1}) \ to \ mathbf {l} _i, \ mathbf {c } _i.fθdec (yi − 1, ci − 1) → li, ci. c0 \ mathbf {c} _0c0 таким образом определяется как c \ mathbf {c} c, являющийся выходом скрытое состояние кодировщика на основе RNN. Впоследствии softmax используется для преобразования вектора логита li \ mathbf {l} _ili в условное распределение вероятностей следующего целевого вектора:
p (yi∣li) = Softmax (li), где li = fθdec (yi − 1, cprev). p (\ mathbf {y} _i | \ mathbf {l} _i) = \ textbf {Softmax} (\ mathbf {l} _i), \ text {with} \ mathbf {l} _i = f _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _ {i-1}, \ mathbf {c} _ {\ text {prev}}).44. Из приведенного выше уравнения мы можно видеть, что распределение текущего целевого вектора yi \ mathbf {y} _iyi напрямую обусловлено предыдущим целевым вектором yi − 1 \ mathbf {y} _ {i-1} yi − 1 и предыдущим скрытым состоянием ci −1 \ mathbf {c} _ {i-1} ci − 1. Поскольку предыдущее скрытое состояние ci − 1 \ mathbf {c} _ {i-1} ci − 1 зависит от всех предыдущие целевые векторы y0,…, yi − 2 \ mathbf {y} _0, \ ldots, \ mathbf {y} _ {i-2} y0,…, yi − 2, он может быть заявлено, что декодер на основе RNN неявно ( например, косвенно ) моделирует условное распределение pθdec (yi∣Y0: i − 1, c) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}) pθdec (yi ∣Y0: i − 1, c).55, которые эффективно выбирают целевой вектор с высокой вероятностью последовательности из pθdec (Y1: m∣c) p _ {\ theta_ {dec}} (\ mathbf {Y} _ {1: m} | \ mathbf {c}) pθdec (Y1: m ∣c).
При таком методе декодирования во время вывода следующий входной вектор yi \ mathbf {y} _iyi может затем быть выбран из pθdec (yi∣Y0: i − 1, c) p _ {\ theta _ {\ text {dec}} } (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}) pθdec (yi ∣Y0: i − 1, c) и, следовательно, добавляется к входной последовательности, так что декодер Затем RNN моделирует pθdec (yi + 1∣Y0: i, c) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _ {i + 1} | \ mathbf {Y} _ {0: i }, \ mathbf {c}) pθdec (yi + 1 ∣Y0: i, c) для выборки следующего входного вектора yi + 1 \ mathbf {y} _ {i + 1} yi + 1 и т. д. в авторегрессивный мод.
Важной особенностью моделей кодеров-декодеров на основе RNN является определение специальных векторов , таких как вектор EOS \ text {EOS} EOS и BOS \ text {BOS} BOS. Вектор EOS \ text {EOS} EOS часто представляет собой окончательный входной вектор xn \ mathbf {x} _nxn, чтобы «указать» кодировщику, что вход последовательность закончилась, а также определяет конец целевой последовательности. В качестве как только EOS \ text {EOS} EOS выбирается из вектора логита, генерация завершено. Вектор BOS \ text {BOS} BOS представляет входной вектор y0 \ mathbf {y} _0y0, подаваемый в декодер RNN на самом первом этапе декодирования.Для вывода первого логита l1 \ mathbf {l} _1l1 требуется ввод, и поскольку на первом шаге не было создано никаких входных данных. специальный BOS \ text {BOS} BOS входной вектор поступает на декодер RNN. Хорошо — довольно сложно! Давайте проиллюстрируйте и рассмотрите пример.
Развернутый кодировщик RNN окрашен в зеленый цвет, а развернутый RNN декодер окрашен в красный цвет.
Английское предложение «Я хочу купить машину», представленное как x1 = I \ mathbf {x} _1 = \ text {I} x1 = I, x2 = want \ mathbf {x} _2 = \ text {want} x2 = хочу, x3 = to \ mathbf {x} _3 = \ text {to} x3 = to, x4 = buy \ mathbf {x} _4 = \ text {buy} x4 = buy, x5 = a \ mathbf {x} _5 = \ text {a} x5 = a, x6 = car \ mathbf {x} _6 = \ text {car} x6 = car и x7 = EOS \ mathbf {x} _7 = \ text {EOS} x7 = EOS переводится на немецкий: «Ich will ein Auto kaufen «определяется как y0 = BOS \ mathbf {y} _0 = \ text {BOS} y0 = BOS, y1 = Ich \ mathbf {y} _1 = \ text {Ich} y1 = Ich, y2 = will \ mathbf {y} _2 = \ text {will} y2 = will, y3 = ein \ mathbf {y} _3 = \ text {ein} y3 = ein, y4 = Auto, y5 = kaufen \ mathbf {y} _4 = \ text {Auto}, \ mathbf {y} _5 = \ text {kaufen} y4 = Auto, y5 = kaufen и y6 = EOS \ mathbf {y} _6 = \ text {EOS} y6 = EOS. 66.На рисунке выше горизонтальная стрелка, соединяющая развернутый кодировщик RNN представляет собой последовательные обновления скрытых штат. Окончательное скрытое состояние кодировщика RNN, представленное c \ mathbf {c} c, затем полностью определяет кодировку входных данных. последовательность и используется как начальное скрытое состояние декодера RNN. Это можно увидеть как преобразование декодера RNN на закодированный вход.
Для генерации первого целевого вектора в декодер загружается BOS \ text {BOS} BOS вектор, показанный как y0 \ mathbf {y} _0y0 на рисунке выше.Цель вектор RNN затем дополнительно отображается на вектор логита l1 \ mathbf {l} _1l1 с помощью слоя прямой связи LM Head для определения условное распределение первого целевого вектора, как объяснено выше:
pθdec (y∣BOS, c). p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ mathbf {c}). pθdec (y∣BOS, c).
Выбирается слово Ich \ text {Ich} Ich (показано серой стрелкой, соединяющей l1 \ mathbf {l} _1l1 и y1 \ mathbf {y} _1y1) и, следовательно, вторая цель вектор может быть выбран:
будет ∼pθdec (y∣BOS, Ich, c).\ text {will} \ sim p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ text {Ich}, \ mathbf {c}). will∼pθdec (y∣BOS, Ich, c).
И так до тех пор, пока на шаге i = 6i = 6i = 6, вектор EOS \ text {EOS} EOS не будет выбран из l6 \ mathbf {l} _6l6, и декодирование не будет завершено. Результирующая цель последовательность составляет Y1: 6 = {y1,…, y6} \ mathbf {Y} _ {1: 6} = \ {\ mathbf {y} _1, \ ldots, \ mathbf {y} _6 \} Y1: 6 = {y1,…, y6}, что является «Ich will ein Auto kaufen» в нашем примере выше.
Подводя итог, модель кодера-декодера на основе RNN, представленная fθencf _ {\ theta _ {\ text {enc}}} fθenc и pθdec p _ {\ theta _ {\ text {dec}}} pθdec, определяет распределение p (Y1: m∣X1: n) p (\ mathbf {Y} _ {1: m} | \ mathbf {X} _ {1: n}) p (Y1: m ∣X1: n) к факторизация:
pθenc, θdec (Y1: m∣X1: n) = ∏i = 1mpθenc, θdec (yi∣Y0: i − 1, X1: n) = ∏i = 1mpθdec (yi∣Y0: i − 1, c), с c = fθenc (X).{m} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}), \ text {with} \ mathbf {c} = f _ {\ theta_ {enc}} (X). pθenc, θdec (Y1: m ∣X1: n) = i = 1∏m pθenc, θdec (yi ∣Y0: i − 1, X1: n) = i = 1 ∏m pθdec (yi ∣Y0: i − 1, c), где c = fθenc (X).
Во время вывода эффективные методы декодирования могут авторегрессивно сгенерировать целевую последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m.
Модель кодера-декодера на основе RNN взяла штурмом сообщество NLG. В В 2016 г. компания Google объявила о полной замене разработанной услуги перевода с помощью единой модели кодировщика-декодера на основе RNN (см. здесь).44 Нейронная сеть может определять распределение вероятностей по всем слова, т.е. p (y∣c, Y0: i − 1) p (\ mathbf {y} | \ mathbf {c}, \ mathbf {Y} _ {0: i-1}) p (y∣c , Y0: i − 1) как следует. Сначала сеть определяет отображение входов c, Y0: i − 1 \ mathbf {c}, \ mathbf {Y} _ {0: i-1} c, Y0: i − 1 во встроенное векторное представление y ′ \ Mathbf {y ‘} y ′, что соответствует целевому вектору RNN. Встроенный векторное представление y ′ \ mathbf {y ‘} y ′ затем передается на «язык модель головы «, что означает, что он умножается на слов. матрица внедрения , i.66 Sutskever et al. (2014) меняет порядок ввода так, чтобы в приведенном выше примере ввод векторы будут соответствовать x1 = car \ mathbf {x} _1 = \ text {car} x1 = car, x2 = a \ mathbf {x} _2 = \ text {a} x2 = a, x3 = buy \ mathbf { x} _3 = \ text {buy} x3 = buy, x4 = to \ mathbf {x} _4 = \ text {to} x4 = to, x5 = want \ mathbf {x} _5 = \ text {want} x5 = Хочу, x6 = I \ mathbf {x} _6 = \ text {I} x6 = I и x7 = EOS \ mathbf {x} _7 = \ text {EOS} x7 = EOS. В мотивация состоит в том, чтобы обеспечить более короткую связь между соответствующими пары слов, такие как x6 = I \ mathbf {x} _6 = \ text {I} x6 = I и y1 = Ich \ mathbf {y} _1 = \ text {Ich} y1 = Ich.Исследовательская группа подчеркивает, что обращение входной последовательности было ключевой причиной того, что их модель улучшена производительность машинного перевода.
Кодировщик-декодерВ 2017 г. Vaswani et al. представил Transformer и тем самым дал рождение модели на базе трансформатора кодировщика-декодера .
Аналогичен моделям кодировщика-декодера на базе RNN, трансформаторный модели кодировщика-декодера состоят из кодировщика и декодера, которые обе стопки из блоков остаточного внимания .Ключевое нововведение трансформаторные модели кодировщика-декодера заключается в том, что такое остаточное внимание блоки могут обрабатывать входную последовательность X1: n \ mathbf {X} _ {1: n} X1: n переменной длина nnn без отображения повторяющейся структуры. Не полагаясь на рекуррентная структура позволяет преобразовывать кодировщики-декодеры высокая степень распараллеливания, что делает модель на порядки больше вычислительно эффективен, чем модели кодировщика-декодера на основе RNN на современное оборудование.
Напоминаем, что для решения задачи от последовательности к последовательности нам необходимо найти отображение входной последовательности X1: n \ mathbf {X} _ {1: n} X1: n на выход последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m переменной длины mmm.Посмотрим как модели кодеров-декодеров на основе трансформаторов используются для поиска такого отображение.
Подобно моделям кодировщика-декодера на основе RNN, трансформатор на основе модели кодировщика-декодера определяют условное распределение целевых векторы Y1: n \ mathbf {Y} _ {1: n} Y1: n с заданной входной последовательностью X1: n \ mathbf {X} _ {1: n} X1: n:
pθenc, θdec (Y1: m∣X1: n). p _ {\ theta _ {\ text {enc}}, \ theta _ {\ text {dec}}} (\ mathbf {Y} _ {1: m} | \ mathbf {X} _ {1: n}). pθenc, θdec (Y1: m ∣X1: n).
Кодер на основе трансформатора кодирует входную последовательность X1: n \ mathbf {X} _ {1: n} X1: n в последовательность из скрытых состояний X‾1: n \ mathbf {\ overline { X}} _ {1: n} X1: n, таким образом определяя отображение:
fθenc: X1: n → X‾1: n.f _ {\ theta _ {\ text {enc}}}: \ mathbf {X} _ {1: n} \ to \ mathbf {\ overline {X}} _ {1: n}. fθenc: X1: n → X1: n.
Затем часть декодера на основе трансформатора моделирует условное распределение вероятностей последовательности целевых векторов Y1: n \ mathbf {Y} _ {1: n} Y1: n с учетом последовательности закодированных скрытых состояний X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n:
pθdec (Y1: n∣X‾1: n). p _ {\ theta_ {dec}} (\ mathbf {Y} _ {1: n} | \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: n ∣X1: n ).
По правилу Байеса это распределение может быть разложено на произведение условное распределение вероятностей целевого вектора yi \ mathbf {y} _iyi учитывая закодированные скрытые состояния X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и все предыдущие целевые векторы Y0: i − 1 \ mathbf {Y} _ {0: i-1} Y0: i − 1:
pθdec (Y1: n∣X‾1: n) = ∏i = 1npθdec (yi∣Y0: i − 1, X‾1: n).{n} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: n ∣X1: n) = i = 1∏n pθdec (yi ∣Y0: i − 1, X1: n).
Трансформаторный декодер тем самым отображает последовательность закодированных скрытых указывает X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и все предыдущие целевые векторы Y0: i − 1 \ mathbf {Y} _ {0: i-1} Y0: i − 1 в вектор logit li \ mathbf {l} _ili. Логит вектор li \ mathbf {l} _ili затем обрабатывается операцией softmax для определить условное распределение pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i -1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n), так же, как это делается для декодеров на основе RNN.Однако в отличие от Декодеры на основе RNN, распределение целевого вектора yi \ mathbf {y} _iyi явно (или напрямую) обусловлено всеми предыдущими целевыми векторами y0,…, yi − 1 \ mathbf {y} _0, \ ldots, \ mathbf {y} _ {i-1} y0,…, yi − 1 Как мы увидим позже деталь. 0-й целевой вектор y0 \ mathbf {y} _0y0 настоящим представлен специальный «начало предложения» BOS \ text {BOS} вектор BOS.
Определив условное распределение pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0 : i-1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n), теперь мы можем авторегрессивно сгенерировать вывод и таким образом определить отображение входной последовательности X1: n \ mathbf {X} _ {1: n} X1: n в выходную последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m при выводе.
Давайте визуализируем полный процесс авторегрессивного поколения модели кодеров-декодеров на базе трансформатора.
Трансформаторный энкодер окрашен в зеленый цвет, а Трансформаторный декодер окрашен в красный цвет. Как и в предыдущем разделе, мы показываем, как английское предложение «Я хочу купить машину», представленное как x1 = I \ mathbf {x} _1 = \ text {I} x1 = I, x2 = want \ mathbf {x} _2 = \ text { want} x2 = want, x3 = to \ mathbf {x} _3 = \ text {to} x3 = to, x4 = buy \ mathbf {x} _4 = \ text {buy} x4 = buy, x5 = a \ mathbf {x} _5 = \ text {a} x5 = a, x6 = car \ mathbf {x} _6 = \ text {car} x6 = car и x7 = EOS \ mathbf {x} _7 = \ text {EOS} x7 = EOS переводится на немецкий: «Ich will ein Auto kaufen «определяется как y0 = BOS \ mathbf {y} _0 = \ text {BOS} y0 = BOS, y1 = Ich \ mathbf {y} _1 = \ text {Ich} y1 = Ich, y2 = will \ mathbf {y} _2 = \ text {will} y2 = will, y3 = ein \ mathbf {y} _3 = \ text {ein} y3 = ein, y4 = Auto, y5 = kaufen \ mathbf {y} _4 = \ text {Auto}, \ mathbf {y} _5 = \ text {kaufen} y4 = Auto, y5 = kaufen и y6 = EOS \ mathbf {y} _6 = \ text {EOS} y6 = EOS.
Сначала кодировщик обрабатывает всю входную последовательность X1: 7 \ mathbf {X} _ {1: 7} X1: 7 = «Я хочу купить машину» (представлен светом зеленые векторы) в контекстуализированную кодированную последовательность X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7. Например. x‾4 \ mathbf {\ overline {x}} _ 4×4 определяет кодировка, которая зависит не только от ввода x4 \ mathbf {x} _4x4 = «buy», но и все остальные слова «я», «хочу», «к», «а», «машина» и «EOS», т.е. контекст.
Затем входная кодировка X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7 вместе с BOS вектор, i.е. y0 \ mathbf {y} _0y0, подается на декодер. Декодер обрабатывает входные данные X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7 и y0 \ mathbf {y} _0y0, чтобы первый логит l1 \ mathbf {l} _1l1 (показан более темным красным) для определения условное распределение первого целевого вектора y1 \ mathbf {y} _1y1:
pθenc, dec (y∣y0, X1: 7) = pθenc, dec (y∣BOS, я хочу купить машину EOS) = pθdec (y∣BOS, X‾1: 7). p _ {\ theta_ {enc, dec}} (\ mathbf {y} | \ mathbf {y} _0, \ mathbf {X} _ {1: 7}) = p _ {\ theta_ {enc, dec}} (\ mathbf {y} | \ text {BOS}, \ text {Я хочу купить машину EOS}) = p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ mathbf {\ overline { X}} _ {1: 7}).pθenc, dec (y∣y0, X1: 7) = pθenc, dec (y∣BOS, я хочу купить машину EOS) = pθdec (y∣BOS, X1: 7).
Затем выбирается первый целевой вектор y1 \ mathbf {y} _1y1 = Ich \ text {Ich} Ich из распределения (обозначено серыми стрелками) и теперь может быть снова подается на декодер. Теперь декодер обрабатывает как y0 \ mathbf {y} _0y0 = «BOS» и y1 \ mathbf {y} _1y1 = «Ich» для определения условного распределение второго целевого вектора y2 \ mathbf {y} _2y2:
pθdec (y∣BOS Ich, X‾1: 7). p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich}, \ mathbf {\ overline {X}} _ {1: 7}).pθdec (y∣BOS Ich, X1: 7).
Мы можем снова выполнить выборку и создать целевой вектор y2 \ mathbf {y} _2y2 = «буду». Мы продолжаем в авторегрессивном режиме до тех пор, пока на шаге 6 не появится EOS. вектор выбирается из условного распределения:
EOS∼pθdec (y∣BOS Ich will ein Auto kaufen, X‾1: 7). \ text {EOS} \ sim p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich будет ein Auto kaufen}, \ mathbf {\ overline {X}} _ {1: 7}). EOS∼pθdec (y∣BOS Ich будет ein Auto kaufen, X1: 7).
И так далее в авторегрессивном режиме.
Важно понимать, что энкодер используется только в первом прямой переход к карте X1: n \ mathbf {X} _ {1: n} X1: n в X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n. Начиная со второго прямого прохода, декодер может напрямую использовать ранее рассчитанная кодировка X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n. Для ясности, давайте проиллюстрируем первый и второй прямой проход для нашего пример выше.
Как видно, только на шаге i = 1i = 1i = 1 мы должны кодировать «Я хочу купить автомобиль EOS «на X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7.На шаге i = 2i = 2i = 2 контекстные кодировки «Я хочу купить машину EOS» просто повторно используется декодером.
В 🤗Трансформаторах это авторегрессивное поколение выполняется под капотом.
при вызове метода .generate () . Воспользуемся одним из наших переводов
модели, чтобы увидеть это в действии.
от трансформаторов импортных MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
model = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»).input_ids
output_ids = model.generate (input_ids) [0]
печать (tokenizer.decode (output_ids))
Выход:
Ich will ein Auto kaufen
Вызов .generate () делает многие вещи скрытыми. Сначала проходит input_ids в кодировщик. Во-вторых, он передает заранее определенный токен, которым является символ MarianMTModel вместе с закодированными input_ids в декодер.11. Более подробно о том, как работает декодирование с поиском луча, можно
посоветовал прочитать этот блог
Почта.
В приложение мы включили фрагмент кода, который показывает, как простая Метод генерации может быть реализован «с нуля». Чтобы полностью понять, как авторегрессивное поколение работает под капотом, это Настоятельно рекомендуется прочитать Приложение.
Подводя итог:
- Энкодер на основе трансформатора определяет отображение от входа последовательность X1: n \ mathbf {X} _ {1: n} X1: n в контекстуализированную последовательность кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n.
- Трансформаторный декодер определяет условное распределение pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n).
- При соответствующем механизме декодирования выходная последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m может быть автоматически выбран из pθdec (yi∣Y0: i − 1, X‾1: n), ∀i∈ {1,…, m} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf { Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}), \ forall i \ in \ {1, \ ldots, m \} pθdec (yi ∣ Y0: i − 1, X1: n), ∀i∈ {1,…, m}.
Отлично, теперь, когда мы получили общий обзор того, как работают модели кодировщиков-декодеров на базе трансформатора, мы можем погрузиться глубже в
как кодировщик, так и декодер части модели. В частности, мы
увидит, как именно кодировщик использует слой самовнимания
чтобы получить последовательность контекстно-зависимых векторных кодировок и как
Уровни самовнимания позволяют эффективно распараллеливать. Тогда мы будем
подробно объясните, как слой самовнимания работает в декодере
модель и как декодер зависит от выхода кодировщика с перекрестное внимание слоев для определения условного распределения pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf { Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n).11 В случае "Helsinki-NLP / opus-mt-en-de" декодирование
параметры доступны
здесь,
где мы видим, что модель применяет поиск луча с num_beams = 6 .
Как упоминалось в предыдущем разделе, энкодер на базе трансформатора отображает входную последовательность в контекстуализированную последовательность кодирования:
fθenc: X1: n → X‾1: n. 11.Двунаправленный Слой самовнимания помещает каждый входной вектор x′j, ∀j∈ {1,…, n} \ mathbf {x ‘} _ j, \ forall j \ in \ {1, \ ldots, n \} x′j, ∀j∈ {1,…, n} по отношению ко всем входные векторы x′1,…, x′n \ mathbf {x ‘} _ 1, \ ldots, \ mathbf {x’} _ nx′1,…, x′n и тем самым преобразует входной вектор x′j \ mathbf {x ‘} _ jx′j в более «изысканный» контекстное представление самого себя, определяемое как x′′j \ mathbf {x »} _ jx′′j. Таким образом, первый блок кодера преобразует каждый входной вектор входная последовательность X1: n \ mathbf {X} _ {1: n} X1: n (показана светло-зеленым цветом ниже) из контекстно-независимое векторное представление в контекстно-зависимое векторное представление, и следующие блоки кодировщика дополнительно уточняют это контекстное представление до тех пор, пока последний блок кодера не выдаст окончательное контекстное кодирование X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n (показано более темным зеленый внизу).22.
Наш примерный энкодер на базе трансформатора состоит из трех энкодеров. блоков, тогда как второй блок кодировщика показан более подробно в красный прямоугольник справа для первых трех входных векторов x1, x2andx3 \ mathbf {x} _1, \ mathbf {x} _2 и \ mathbf {x} _3x1, x2 иx3. Двунаправленный Механизм самовнимания проиллюстрирован полносвязным графом в показаны нижняя часть красного поля и два слоя прямой связи. в верхней части красного поля.Как было сказано ранее, мы сосредоточимся только на о механизме двунаправленного самовнимания.
Как видно, каждый выходной вектор слоя самовнимания x′′i, ∀i∈ {1,…, 7} \ mathbf {x »} _ i, \ forall i \ in \ {1, \ ldots, 7 \} x′′i, ∀i∈ {1,…, 7} напрямую зависит от , от все входных векторов x′1,…, x′7 \ mathbf {x ‘} _ 1, \ ldots, \ mathbf {x’} _ 7x′1,…, x′7. Это означает, например , что входное векторное представление слова «хочу», то есть x′2 \ mathbf {x ‘} _ 2x′2, находится в прямой связи со словом «купить», я.е. x′4 \ mathbf {x ‘} _ 4x′4, но также со словом «I», т.е. x′1 \ mathbf {x’} _ 1x′1. Выходное векторное представление «хочу», , т.е. x′′2 \ mathbf {x »} _ 2x′′2, таким образом, представляет собой более точный контекстный представление слова «хочу».
Давайте подробнее рассмотрим, как работает двунаправленное самовнимание. Каждый входной вектор x′i \ mathbf {x ‘} _ ix′i входной последовательности X′1: n \ mathbf {X’} _ {1: n} X′1: n блока кодера проецируется на ключевой вектор ki \ mathbf {k} _iki, вектор значений vi \ mathbf {v} _ivi и вектор запроса qi \ mathbf {q} _iqi (показаны ниже оранжевым, синим и фиолетовым соответственно) с помощью трех обучаемых весовых матриц Wq, Wv, Wk \ mathbf {W} _q, \ mathbf {W} _v, \ mathbf {W} _kWq, Wv, Wk:
qi = Wqx′i, \ mathbf {q} _i = \ mathbf {W} _q \ mathbf {x ‘} _ i, qi = Wq x′i, vi = Wvx′i, \ mathbf {v} _i = \ mathbf {W} _v \ mathbf {x ‘} _ i, vi = Wv x′i, ki = Wkx′i, \ mathbf {k} _i = \ mathbf {W} _k \ mathbf {x ‘} _ i, ki = Wk x′i, ∀i∈ {1,… n}.\ forall i \ in \ {1, \ ldots n \}. ∀i∈ {1,… n}.
Обратите внимание, что одинаковые весовые матрицы применяются к каждому входному вектору xi, ∀i∈ {i,…, n} \ mathbf {x} _i, \ forall i \ in \ {i, \ ldots, n \} xi, ∀i∈ {i,…, n}. После проецирования каждого входной вектор xi \ mathbf {x} _ixi в вектор запроса, ключа и значения, каждый вектор запроса qj, ∀j∈ {1,…, n} \ mathbf {q} _j, \ forall j \ in \ {1, \ ldots, n \} qj, ∀j∈ {1,…, n} равен в сравнении ко всем ключевым векторам k1,…, kn \ mathbf {k} _1, \ ldots, \ mathbf {k} _nk1,…, kn. Чем больше похожий один из ключевых векторов k1,… kn \ mathbf {k} _1, \ ldots \ mathbf {k} _nk1,… kn должен вектор запроса qj \ mathbf {q} _jqj, тем важнее соответствующий вектор значений vj \ mathbf {v} _jvj для выходного вектора x′′j \ mathbf {x »} _ jx′′j.\ intercal \ mathbf {q} _j) Softmax (K1: n⊺ qj) как показано в уравнении ниже. Для полного описания слой самовнимания, читателю рекомендуется взглянуть на это сообщение в блоге или исходная бумага.
Хорошо, это звучит довольно сложно. Проиллюстрируем
двунаправленный слой самовнимания для одного из векторов запросов нашего
пример выше. Для простоты предполагается, что наш примерный
Трансформаторный декодер использует только одну концентрирующую головку конфиг.num_heads = 1 и что нормализация не применяется.
Слева показан ранее проиллюстрированный второй блок кодера. снова и справа, детальная визуализация двунаправленного Механизм самовнимания дан для второго входного вектора x′2 \ mathbf {x ‘} _ 2x′2, который соответствует входному слову «хочу». Вначале проецируются все входные векторы x′1,…, x′7 \ mathbf {x ‘} _ 1, \ ldots, \ mathbf {x’} _ 7x′1,…, x′7 к соответствующим векторам запросов q1,…, q7 \ mathbf {q} _1, \ ldots, \ mathbf {q} _7q1,…, q7 (вверху фиолетовым цветом показаны только первые три вектора запроса), значение векторы v1,…, v7 \ mathbf {v} _1, \ ldots, \ mathbf {v} _7v1,…, v7 (показаны синим) и ключ векторы k1,…, k7 \ mathbf {k} _1, \ ldots, \ mathbf {k} _7k1,…, k7 (показаны оранжевым).{\ intercal} K1: 7⊺ и q2 \ mathbf {q} _2q2, таким образом, делает его можно сравнить векторное представление «хочу» со всеми другими входные векторные представления «Я», «К», «Купить», «А», «Автомобиль», «EOS», чтобы веса самовнимания отражали важность каждого из другие входные векторные представления x′j, с j ≠ 2 \ mathbf {x ‘} _ j \ text {, с} j \ ne 2x′j, с j = 2 для уточненного представления x′′2 \ mathbf { x »} _ 2x′′2 слова «хочу».
Чтобы лучше понять значение двунаправленного слой самовнимания, предположим, что следующее предложение обрабатывается: « Дом красивый и удачно расположенный в центре города. где легко добраться на общественном транспорте ».Слово «это» относится к «дому», который находится на расстоянии 12 «позиций». В энкодеры на основе трансформатора, двунаправленный слой самовнимания выполняет одну математическую операцию, чтобы поместить входной вектор «дом» во взаимосвязи с входным вектором «оно» (сравните с первая иллюстрация этого раздела). Напротив, в RNN на основе кодировщик, слово, которое находится на расстоянии 12 «позиций», потребует не менее 12 математические операции, означающие, что в кодировщике на основе RNN линейный количество математических операций не требуется.Это делает его много кодировщику на основе RNN сложнее моделировать контекстные представления. Также становится ясно, что энкодер на основе трансформатора гораздо менее склонен к потере важной информации, чем основанный на RNN модель кодер-декодер, поскольку длина последовательности кодирования равна оставил то же самое, , т.е. len (X1: n) = len (X‾1: n) = n \ textbf {len} (\ mathbf {X} _ {1: n}) = \ textbf {len} (\ mathbf {\ overline {X}} _ {1: n}) = nlen (X1: n) = len (X1: n) = n, в то время как RNN сжимает длину из ∗ len ((X1: n) = n * \ textbf {len} ((\ mathbf {X} _ {1: n}) = n ∗ len ((X1: n) = n просто len (c) = 1 \ textbf {len} (\ mathbf {c}) = 1len (c) = 1, что очень затрудняет работу RNN для эффективного кодирования дальнодействующих зависимостей между входными словами.\ intercal \ mathbf {K} _ {1: n}) + \ mathbf {X ‘} _ {1: n}. X′′1: n = V1: n Softmax (Q1: n⊺ K1: n) + X′1: n.
Выходные данные X′′1: n = x′′1,…, x′′n \ mathbf {X »} _ {1: n} = \ mathbf {x »} _ 1, \ ldots, \ mathbf { x »} _ nX′′1: n = x′′1,…, x′′n вычисляется с помощью серии умножений матриц и softmax операция, которую можно эффективно распараллелить. Обратите внимание, что в Модель кодировщика на основе RNN, вычисление скрытого состояния c \ mathbf {c} c должно выполняться последовательно: вычисление скрытого состояния первый входной вектор x1 \ mathbf {x} _1x1, затем вычислить скрытое состояние второй входной вектор, который зависит от скрытого состояния первого скрытого вектор и др.Последовательный характер RNN не позволяет эффективно распараллеливание и делает их более неэффективными по сравнению с модели кодировщиков на базе трансформаторов на современном оборудовании GPU.
Отлично, теперь мы должны лучше понять а) как модели кодировщиков на основе трансформаторов эффективно моделируют контекстные представления и б) как они эффективно обрабатывают длинные последовательности входные векторы.
Теперь давайте напишем небольшой пример кодирующей части нашего
Модель кодера-декодера MarianMT для проверки того, что объясненная теория
выполняется на практике.11 Подробное объяснение роли слоев прямой связи
в трансформаторных моделях выходит за рамки этого ноутбука. это
утверждал в Yun et. al, (2017)
что уровни прямой связи имеют решающее значение для сопоставления каждого контекстного вектора x′i \ mathbf {x ‘} _ ix′i индивидуально с желаемым выходным пространством, которое самовнимание слой самостоятельно не справляется. Должен быть
здесь отмечено, что каждый выходной токен x ′ \ mathbf {x ‘} x ′ обрабатывается
тот же слой прямой связи. Подробнее читателю рекомендуется прочитать
бумага.22 Однако входной вектор EOS необязательно добавлять к
входная последовательность, но, как было показано, во многих случаях улучшает производительность.
В отличие от 0 BOS \ text {BOS} целевой вектор BOS
декодер на основе трансформатора требуется как начальный входной вектор для
предсказать первый целевой вектор.
от трансформаторов импортных MarianMTModel, MarianTokenizer
импортный фонарик
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
модель = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
вложения = модель.get_input_embeddings ()
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»). input_ids
encoder_hidden_states = model.base_model.encoder (input_ids, return_dict = True) .last_hidden_state
input_ids_perturbed = tokenizer («Я хочу купить дом», return_tensors = «pt»). input_ids
encoder_hidden_states_perturbed = model.base_model.encoder (input_ids_perturbed, return_dict = True) .last_hidden_state
print (f "Длина вложений ввода {вложений (input_ids).форма [1]}. Длина encoder_hidden_states {encoder_hidden_states.shape [1]} ")
print ("Кодировка для` I` равна его возмущенной версии ?: ", torch.allclose (encoder_hidden_states [0, 0], encoder_hidden_states_perturbed [0, 0], atol = 1e-3))
Выходы:
Длина вложений ввода 7. Длина encoder_hidden_states 7
Кодировка для `I` равна его возмущенной версии ?: False
Сравниваем длину вложений входного слова, i.е. вложений (input_ids) , соответствующих X1: n \ mathbf {X} _ {1: n} X1: n, с
длина encoder_hidden_states , соответствующая X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n. Кроме того, мы переадресовали последовательность слов
«Хочу купить машину» и слегка возмущенный вариант «Хочу
купить дом «через кодировщик, чтобы проверить, есть ли первая выходная кодировка,
соответствует «I», отличается, когда в
входная последовательность.
Как и ожидалось, выходная длина вложений входного слова и кодировщика выходные кодировки, i.е. len (X1: n) \ textbf {len} (\ mathbf {X} _ {1: n}) len (X1: n) и len (X‾1: n) \ textbf {len} (\ mathbf { \ overline {X}} _ {1: n}) len (X1: n), равно. Во-вторых, это может быть отметил, что значения закодированного выходного вектора x‾1 = «I» \ mathbf {\ overline {x}} _ 1 = \ text {«I»} x1 = «I» отличаются, когда последнее слово меняется с «автомобиль» на «дом». Однако это не должно вызывать сюрприз, если кто-то понял двунаправленное самовнимание.
Кстати, модели с автокодированием , такие как BERT, имеют точно такие же архитектура как на базе трансформатора модели кодировщика . Автокодирование модели используют эту архитектуру для массового самоконтроля предварительное обучение текстовых данных в открытом домене, чтобы они могли сопоставить любое слово последовательность к глубокому двунаправленному представлению. В Devlin et al. (2018) авторы показывают, что предварительно обученная модель BERT с одним классификационным слоем для конкретной задачи сверху может достичь результатов SOTA по одиннадцати задачам НЛП. Все автокодирование модели 🤗Трансформаторов можно найти здесь.
ДекодерКак упоминалось в разделе Encoder-Decoder , преобразователь на основе преобразователя декодер определяет условное распределение вероятностей цели последовательность с учетом контекстуализированной кодирующей последовательности:
pθdec (Y1: m∣X‾1: n), p _ {\ theta_ {dec}} (\ mathbf {Y} _ {1: m} | \ mathbf {\ overline {X}} _ {1: n} ), pθdec (Y1: m ∣X1: n),
, который по правилу Байеса может быть разложен на продукт условного распределения следующего целевого вектора с учетом контекстуализированного кодирующая последовательность и все предыдущие целевые векторы:
pθdec (Y1: m∣X‾1: n) = ∏i = 1mpθdec (yi∣Y0: i − 1, X‾1: n).{m} p _ {\ theta_ {dec}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: m ∣X1: n) = i = 1∏m pθdec (yi ∣Y0: i − 1, X1: n).
Давайте сначала разберемся, как декодер на основе трансформатора определяет распределение вероятностей. Трансформаторный декодер представляет собой набор блоки декодера , за которыми следует плотный слой, «голова LM». Стек блоков декодера сопоставляет контекстуализированную последовательность кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и последовательность целевого вектора с добавлением вектор BOS \ text {BOS} BOS и переход к последнему целевому вектору i.е. Y0: i − 1 \ mathbf {Y} _ {0: i-1} Y0: i − 1, в закодированную последовательность целевых векторов Y‾0: i − 1 \ mathbf {\ overline {Y}} _ {0: i-1} Y0: i-1. Затем «голова LM» отображает закодированные последовательность целевых векторов Y‾0: i − 1 \ mathbf {\ overline {Y}} _ {0: i-1} Y0: i − 1 до a последовательность логит-векторов L1: n = l1,…, ln \ mathbf {L} _ {1: n} = \ mathbf {l} _1, \ ldots, \ mathbf {l} _nL1: n = l1,…, ln, тогда как размерность каждого логит-вектора li \ mathbf {l} _ili соответствует размер словарного запаса. {\ intercal} \ mathbf {\ overline {y}} _ {i-1 }) = Softmax (Wemb⊺ y i − 1) = Softmax (li).= \ text {Softmax} (\ mathbf {l} _i). = Softmax (li).
Собираем все вместе, чтобы смоделировать условное распределение последовательности целевых векторов Y1: m \ mathbf {Y} _ {1: m} Y1: m, целевые векторы Y1: m − 1 \ mathbf {Y} _ {1: m-1} Y1: m − 1 Предваряется специальным вектором BOS \ text {BOS} BOS, , то есть y0 \ mathbf {y} _0y0, сначала отображаются вместе с контекстуализированными кодирующая последовательность X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n в вектор логита последовательность L1: m \ mathbf {L} _ {1: m} L1: m. Следовательно, каждый целевой вектор логита li \ mathbf {l} _ili преобразуется в условную вероятность распределение целевого вектора yi \ mathbf {y} _iyi с использованием softmax операция.{m} p _ {\ theta_ {dec}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: m ∣X1: n) = i = 1∏m pθdec (yi ∣Y0: i − 1, X1: n).
В отличие от трансформаторных энкодеров, в трансформаторных декодеры, закодированный выходной вектор y‾i \ mathbf {\ overline {y}} _ iy i должен быть хорошее представление следующего целевого вектора yi + 1 \ mathbf {y} _ {i + 1} yi + 1 и не самого входного вектора. Кроме того, закодированный выходной вектор y‾i \ mathbf {\ overline {y}} _ iy i должен быть обусловлен всеми контекстными кодирующая последовательность X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n.22. Слой однонаправленного самовнимания. ставит каждый из своих входных векторов y′j \ mathbf {y ‘} _ jy′j только во взаимосвязь с все предыдущие входные векторы y′i, с i≤j \ mathbf {y ‘} _ i, \ text {with} i \ le jy′i, с i≤j для все j∈ {1,…, n} j \ in \ {1, \ ldots, n \} j∈ {1,…, n} для моделирования распределения вероятностей следующие целевые векторы. Слой перекрестного внимания помещает каждый из входные векторы y′′j \ mathbf {y »} _ jy′′j во взаимосвязи со всеми контекстуализированными кодирующие векторы X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n, чтобы обусловить распределение вероятностей следующих целевых векторов на входе кодировщик тоже.
Хорошо, давайте визуализируем декодер на основе трансформатора для нашего Пример перевода с английского на немецкий.
Мы видим, что декодер отображает вход Y0: 5 \ mathbf {Y} _ {0: 5} Y0: 5 «BOS», «Ich», «will», «ein», «Auto», «kaufen» (показаны светло-красным) вместе с контекстуализированной последовательностью «я», «хочу», «к», «купить», «а», «автомобиль», «EOS», т.е. X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7 (показано темно-зеленым) в векторы логита L1: 6 \ mathbf {L} _ {1: 6} L1: 6 (показано на темно-красный).
Применение операции softmax к каждому l1, l2,…, l5 \ mathbf {l} _1, \ mathbf {l} _2, \ ldots, \ mathbf {l} _5l1, l2,…, l5 может таким образом определить условные распределения вероятностей:
pθdec (y∣BOS, X‾1: 7), p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ mathbf {\ overline {X}} _ {1: 7} ), pθdec (y∣BOS, X1: 7), pθdec (y∣BOS Ich, X‾1: 7), p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich}, \ mathbf {\ overline {X}} _ {1: 7 }), pθdec (y∣BOS Ich, X1: 7), …, \ Ldots,…, pθdec (y∣BOS Ich будет ein Auto kaufen, X‾1: 7). p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich будет ein Auto kaufen}, \ mathbf {\ overline {X}} _ {1: 7}).pθdec (y∣BOS Ich будет ein Auto kaufen, X1: 7).
Общая условная вероятность:
pθdec (Ich будет ein Auto kaufen EOS∣X‾1: n) p _ {\ theta_ {dec}} (\ text {Ich будет ein Auto kaufen EOS} | \ mathbf {\ overline {X}} _ {1: n }) pθdec (Ich будет ein Auto kaufen EOS∣X1: n)
Следовательно,может быть вычислено как следующее произведение:
pθdec (Ich∣BOS, X‾1: 7) ×… × pθdec (EOS∣BOS Ich будет ein Auto kaufen, X‾1: 7). p _ {\ theta_ {dec}} (\ text {Ich} | \ text {BOS}, \ mathbf {\ overline {X}} _ {1: 7}) \ times \ ldots \ times p _ {\ theta_ {dec} } (\ text {EOS} | \ text {BOS Ich будет ein Auto kaufen}, \ mathbf {\ overline {X}} _ {1: 7}).pθdec (Ich∣BOS, X1: 7) ×… × pθdec (EOS∣BOS Ich будет использовать Auto kaufen, X1: 7).
В красном поле справа показан блок декодера для первых трех целевые векторы y0, y1, y2 \ mathbf {y} _0, \ mathbf {y} _1, \ mathbf {y} _2y0, y1, y2. В нижнем части, механизм однонаправленного самовнимания проиллюстрирован и в в центре проиллюстрирован механизм перекрестного внимания. Давай сначала сосредоточьтесь на однонаправленном самовнимании.
Как при двунаправленном самовнимании, при однонаправленном самовнимании, векторы запросов q0,…, qm − 1 \ mathbf {q} _0, \ ldots, \ mathbf {q} _ {m-1} q0,…, qm − 1 (показаны на фиолетовый внизу), ключевые векторы k0,…, km − 1 \ mathbf {k} _0, \ ldots, \ mathbf {k} _ {m-1} k0,…, km − 1 (показаны оранжевым ниже), и векторы значений v0,…, vm − 1 \ mathbf {v} _0, \ ldots, \ mathbf {v} _ {m-1} v0,…, vm − 1 (показаны на синий ниже) проецируются из соответствующих входных векторов y′0,…, y′m − 1 \ mathbf {y ‘} _ 0, \ ldots, \ mathbf {y’} _ {m-1} y′0,…, y′m −1 (показано светло-красным цветом ниже).Однако при однонаправленном самовнимании каждый вектор запроса qi \ mathbf {q} _iqi сравнивается только с его соответствующим ключевым вектором и все предыдущие, а именно k0,…, ki \ mathbf {k} _0, \ ldots, \ mathbf {k} _ik0,…, ki, чтобы получить соответствующие гири . Это предотвращает включение любой информации в выходной вектор y′′j \ mathbf {y »} _ jy′′j (показан темно-красным ниже) о следующем входном векторе yi, с i> j \ mathbf {y} _i, \ text {с} i> jyi, с i> j для все j∈ {0,…, m − 1} j \ in \ {0, \ ldots, m — 1 \} j∈ {0,…, m − 1}.\ intercal \ mathbf {q} _i) + \ mathbf {y ‘} _ i. y′′i = V0: i Softmax (K0: i⊺ qi) + y′i.
Обратите внимание, что диапазон индекса векторов ключей и значений равен 0: i0: i0: i вместо 0: m − 10: m-10: m − 1, который будет диапазоном ключевых векторов в двунаправленное самовнимание.
Давайте проиллюстрируем однонаправленное самовнимание для входного вектора y′1 \ mathbf {y ‘} _ 1y′1 для нашего примера выше.
Как видно, y′′1 \ mathbf {y »} _ 1y′′1 зависит только от y′0 \ mathbf {y ‘} _ 0y′0 и y′1 \ mathbf {y’} _ 1y′1 .Поэтому положим векторное представление слова «Ich», т.е. y′1 \ mathbf {y ‘} _ 1y′1 только в отношении самого себя и Целевой вектор «BOS», то есть y′0 \ mathbf {y ‘} _ 0y′0, но не с векторное представление слова «будет», т.е. y′2 \ mathbf {y ‘} _ 2y′2.
Итак, почему так важно, чтобы мы использовали однонаправленное самовнимание в декодер вместо двунаправленного самовнимания? Как указано выше, декодер на основе трансформатора определяет отображение из последовательности ввода вектор Y0: m − 1 \ mathbf {Y} _ {0: m-1} Y0: m − 1 в логиты, соответствующие следующему входные векторы декодера, а именно L1: m \ mathbf {L} _ {1: m} L1: m.В нашем примере это означает например , что входной вектор y1 \ mathbf {y} _1y1 = «Ich» сопоставлен в вектор логита l2 \ mathbf {l} _2l2, который затем используется для прогнозирования входной вектор y2 \ mathbf {y} _2y2. Таким образом, если y′1 \ mathbf {y ‘} _ 1y′1 будет иметь доступ к следующим входным векторам Y′2: 5 \ mathbf {Y ‘} _ {2: 5} Y′2: 5, декодер будет просто скопируйте векторное представление «воли», то есть y′2 \ mathbf {y ‘} _ 2y′2, чтобы получить его выход y′′1 \ mathbf {y’ ‘} _ 1y′′1. Это было бы перенаправлен на последний уровень, так что закодированный выходной вектор y‾1 \ mathbf {\ overline {y}} _ 1y 1 по существу просто соответствовал бы векторное представление y2 \ mathbf {y} _2y2.
Это явно невыгодно, поскольку декодер на основе трансформатора никогда не учись предсказывать следующее слово, учитывая все предыдущие слова, а просто скопируйте целевой вектор yi \ mathbf {y} _iyi через сеть в y‾i − 1 \ mathbf {\ overline {y}} _ {i-1} y i − 1 для всех i∈ {1,… , m} i \ in \ {1, \ ldots, m \} i∈ {1,…, m}. В чтобы определить условное распределение следующего целевого вектора, распределение не может быть обусловлено следующим целевым вектором. Нет смысла предсказывать yi \ mathbf {y} _iyi из p (y∣Y0: i, X‾) p (\ mathbf {y} | \ mathbf {Y} _ {0: i}, \ mathbf {\ overline {X}}) p (y∣Y0: i, X), поскольку распределение обусловлено целевым вектором, который предполагается модель.Следовательно, однонаправленная архитектура самовнимания позволяет нам определить распределение вероятностей причинно-следственных связей , которое необходимо для эффективного моделирования условного распределения следующих целевой вектор.
Отлично! Теперь мы можем перейти к слою, который соединяет кодировщик и декодер — механизм перекрестного внимания !
Слой перекрестного внимания принимает в качестве входных данных две векторные последовательности: выходы однонаправленного слоя самовнимания, i.е. Y′′0: m − 1 \ mathbf {Y »} _ {0: m-1} Y′′0: m − 1 и контекстуализированные векторы кодирования X‾1: n \ mathbf {\ overline {X }} _ {1: n} X1: n. Как и в слое самовнимания, запрос векторы q0,…, qm − 1 \ mathbf {q} _0, \ ldots, \ mathbf {q} _ {m-1} q0,…, qm − 1 являются проекциями выходные векторы предыдущего слоя, , то есть Y′′0: m − 1 \ mathbf {Y »} _ {0: m-1} Y′′0: m − 1. Однако векторы ключа и значения k0,…, km − 1 \ mathbf {k} _0, \ ldots, \ mathbf {k} _ {m-1} k0,…, km − 1 и v0,…, vm −1 \ mathbf {v} _0, \ ldots, \ mathbf {v} _ {m-1} v0,…, vm − 1 — проекции контекстуализированные векторы кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n.Имея определены векторы ключа, значения и запроса, вектор запроса qi \ mathbf {q} _iqi затем сравниваются с все ключевых векторов и используется соответствующая оценка для взвешивания соответствующих векторов значений, как и в случае двунаправленное самовнимание, чтобы дать выходной вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i для всех i∈0,…, m − 1i \ in {0, \ ldots , m-1} i∈0,…, m − 1. \ intercal \ mathbf {q} _i) + \ mathbf {y »} _ я.y ′ ′ ′ i = V1: n Softmax (K1: n⊺ qi) + y′′i.
Обратите внимание, что диапазон индекса векторов ключей и значений равен 1: n1: n1: n соответствует количеству контекстуализированных векторов кодирования.
Давайте визуализируем механизм перекрестного внимания Давайте для ввода вектор y′′1 \ mathbf {y »} _ 1y′′1 для нашего примера выше.
Мы видим, что вектор запроса q1 \ mathbf {q} _1q1 (показан фиолетовым цветом) равен получено из y′′1 \ mathbf {y »} _ 1y′′1 (показано красным) и, следовательно, полагается на вектор представление слова «Ич».Вектор запроса q1 \ mathbf {q} _1q1 затем сравнивается с ключевыми векторами k1,…, k7 \ mathbf {k} _1, \ ldots, \ mathbf {k} _7k1,…, k7 (показаны желтым цветом), соответствующими представление контекстного кодирования всех входных векторов кодировщика X1: n \ mathbf {X} _ {1: n} X1: n = «Я хочу купить автомобиль EOS». Это ставит вектор представление «Ich» в прямую связь со всеми входами кодировщика векторы. Наконец, веса внимания умножаются на значение векторы v1,…, v7 \ mathbf {v} _1, \ ldots, \ mathbf {v} _7v1,…, v7 (показаны бирюзовым) в вывести в дополнение к входному вектору y′′1 \ mathbf {y »} _ 1y′′1 выходной вектор y ′ ′ ′ 1 \ mathbf {y » ‘} _ 1y ′ ′ ′ 1 (показан темно-красным ).
Итак, интуитивно, что именно здесь происходит? Каждый выходной вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i является взвешенной суммой всех проекций значений входы кодировщика v1,…, v7 \ mathbf {v} _ {1}, \ ldots, \ mathbf {v} _7v1,…, v7 плюс вход вектор y′′i \ mathbf {y »} _ iy′′i ( см. формулу , проиллюстрированную выше). Ключ механизм понимания следующий: в зависимости от того, насколько похож проекция запроса входного вектора декодера qi \ mathbf {q} _iqi на проекция ключа входного вектора кодировщика kj \ mathbf {k} _jkj, тем более важна проекция значения входного вектора кодировщика vj \ mathbf {v} _jvj.В общих чертах это означает, что чем больше «родственный» входное представление декодера относится к входному представлению кодировщика, больше влияет ли входное представление на выход декодера представление.
Круто! Теперь мы можем видеть, как эта архитектура хорошо обрабатывает каждый вывод. вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i на взаимодействии между входом кодировщика векторы X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и входной вектор y′′i \ mathbf {y »} _ iy′′i. Еще одно важное наблюдение на этом этапе заключается в том, что архитектура полностью не зависит от количества nnn контекстуализированные векторы кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n, на которых выходной вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i обусловлен.{\ text {cross}} _ {v} Wvcross для получения ключевых векторов k1,…, kn \ mathbf {k} _1, \ ldots, \ mathbf {k} _nk1,…, kn и векторов значений v1 ,…, Vn \ mathbf {v} _1, \ ldots, \ mathbf {v} _nv1,…, vn соответственно используются всеми позиции 1,…, n1, \ ldots, n1,…, n и все векторы значений v1,…, vn \ mathbf {v} _1, \ ldots, \ mathbf {v} _n v1,…, vn суммируются к одному взвешенный усредненный вектор. Теперь также становится очевидным, почему декодер на базе трансформатора не страдает зависимостью от дальнего действия Проблема, от которой страдает декодер на основе RNN.Потому что каждый декодер логит вектор напрямую зависит от каждого отдельного закодированного выходного вектора, количество математических операций для сравнения первого закодированного выходной вектор и последний логит-вектор декодера составляют по существу только один.
В заключение, однонаправленный слой самовнимания отвечает за согласование каждого выходного вектора со всеми предыдущими входными векторами декодера а текущий вектор ввода и слой перекрестного внимания — отвечает за дальнейшее кондиционирование каждого выходного вектора на всех закодированных входных данных. векторы.22 Опять же, подробное объяснение роли прямого игра слоев в моделях на основе трансформатора выходит за рамки этого ноутбук. Это утверждается в Yun et. аль, (2017), что слои с прямой связью имеют решающее значение для сопоставления каждого контекстного вектора x′i \ mathbf {x ‘} _ ix′i индивидуально к желаемому выходному пространству, которое слой самовнимания не может справиться самостоятельно. Здесь следует отметить, что каждый выходной токен x ‘\ mathbf {x’} x ‘обрабатывается одним и тем же уровнем прямой связи. Для большего Подробности, читателю рекомендуется прочитать статью.
от трансформаторов импортных MarianMTModel, MarianTokenizer
импортный фонарик
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
model = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
вложения = модель.get_input_embeddings ()
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»). input_ids
decoder_input_ids = tokenizer (" Ich will ein", return_tensors = "pt", add_special_tokens = False) .input_ids
decoder_output_vectors = модель.base_model.decoder (decoder_input_ids) .last_hidden_state
lm_logits = torch.nn.functional.linear (decoder_output_vectors, embeddings.weight, bias = model.final_logits_bias)
decoder_input_ids_perturbed = tokenizer (" Ich will das", return_tensors = "pt", add_special_tokens = False) .input_ids
decoder_output_vectors_perturbed = model.base_model.decoder (decoder_input_ids_perturbed) .last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear (decoder_output_vectors_perturbed, embeddings.weight, bias = model.final_logits_bias)
print (f "Форма входных векторов декодера {embeddings (decoder_input_ids) .shape}. Форма логитов декодера {lm_logits.shape}")
print ("Кодировка для` Ich` равна его измененной версии ?: ", torch.allclose (lm_logits [0, 0], lm_logits_perturbed [0, 0], atol = 1e-3))
Выход:
Форма входных векторов декодера torch.Size ([1, 5, 512]). Форма декодера logits torch.Size ([1, 5, 58101])
Кодировка для `Ich` равна его измененной версии ?: True
Мы сравниваем выходную форму вложений входных слов декодера, i.е. вложений (decoder_input_ids) (соответствует Y0: 4 \ mathbf {Y} _ {0: 4} Y0: 4,
здесь соответствует BOS, а «Ich will das» токенизируется до 4
токены) с размерностью lm_logits (соответствует L1: 5 \ mathbf {L} _ {1: 5} L1: 5). Также мы передали последовательность слов
« Ich will das» и слегка возмущенная версия
« Ich will das» вместе с encoder_output_vectors через кодировщик, чтобы проверить, lm_logit , соответствующий «Ich», отличается, когда только последнее слово
изменено во входной последовательности («ein» -> «das»).
Как и ожидалось, выходные формы вложений входных слов декодера и
lm_logits, , т.е. размерность Y0: 4 \ mathbf {Y} _ {0: 4} Y0: 4 и L1: 5 \ mathbf {L} _ {1: 5} L1: 5 в последнем измерение. В то время как
длина последовательности такая же (= 5), размерность входа декодера
вложение слов соответствует model.config.hidden_size , тогда как
размерность lm_logit соответствует размеру словаря model.config.vocab_size , как описано выше.Во-вторых, можно отметить
что значения закодированного выходного вектора l1 = «Ich» \ mathbf {l} _1 = \ text {«Ich»} l1 = «Ich» совпадают при изменении последнего слова
от «эйн» до «дас». Однако это не должно вызывать удивления, если
человек понял однонаправленное самовнимание.
В заключение отметим, что модели с авторегрессией , такие как GPT2, имеют та же архитектура, что и на базе трансформатора декодеры модели , если один удаляет слой перекрестного внимания, потому что автономный авторегрессивный модели не привязаны к каким-либо выходам энкодера.Так авторегрессивный модели по сути такие же, как модели с автоматическим кодированием , но заменяют двунаправленное внимание с однонаправленным вниманием. Эти модели также можно предварительно обучить работе с массивными текстовыми данными в открытом домене, чтобы показать впечатляющая производительность в задачах генерации естественного языка (NLG). В Radford et al. (2019), авторы показывают, что предварительно обученная модель GPT2 может достичь SOTA или закрыть к результатам SOTA по разнообразным задачам NLG без особой настройки. Все авторегрессивные моделей 🤗Трансформаторов можно найти здесь.
Хорошо, вот и все! Теперь вы должны хорошо понимать модели кодеров-декодеров на базе трансформатора и как их использовать с 🤗Библиотека трансформеров.
Большое спасибо Виктору Саню, Саше Рашу, Сэму Шлейферу, Оливеру Остранду, Теду Московицу и Кристиану Кивику за ценные отзывы.
Приложение Как упоминалось выше, следующий фрагмент кода показывает, как можно программировать
простой метод генерации кодера-декодера на базе трансформатора модели.Здесь мы реализуем простой метод декодирования жадного , используя torch.argmax для выборки целевого вектора.
от трансформаторов импортных MarianMTModel, MarianTokenizer
импортный фонарик
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
model = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»). input_ids
decoder_input_ids = tokenizer ("", add_special_tokens = False, return_tensors = "pt").input_ids
assert decoder_input_ids [0, 0] .item () == model.config.decoder_start_token_id, "` decoder_input_ids` должен соответствовать `model.config.decoder_start_token_id`"
output = model (input_ids, decoder_input_ids = decoder_input_ids, return_dict = True)
encoded_sequence = (outputs.encoder_last_hidden_state,)
lm_logits = outputs.logits
next_decoder_input_ids = torch.argmax (lm_logits [:, -1:], ось = -1)
decoder_input_ids = torch.cat ([decoder_input_ids, next_decoder_input_ids], axis = -1)
lm_logits = модель (Нет, encoder_outputs = encoded_sequence, decoder_input_ids = decoder_input_ids, return_dict = True).логиты
next_decoder_input_ids = torch.argmax (lm_logits [:, -1:], ось = -1)
decoder_input_ids = torch.cat ([decoder_input_ids, next_decoder_input_ids], axis = -1)
lm_logits = модель (Нет, encoder_outputs = encoded_sequence, decoder_input_ids = decoder_input_ids, return_dict = True) .logits
next_decoder_input_ids = torch.argmax (lm_logits [:, -1:], ось = -1)
decoder_input_ids = torch.cat ([decoder_input_ids, next_decoder_input_ids], axis = -1)
print (f "Создано на данный момент: {tokenizer.decode (decoder_input_ids [0], skip_special_tokens = True)}")
Выходы:
На данный момент создано: Ich Ich
В этом примере кода мы показываем именно то, что было описано ранее.Мы
передайте ввод «Я хочу купить машину» вместе с BOS \ text {BOS} BOS
токен модели кодера-декодера и выборка из первого логита l1 \ mathbf {l} _1l1 (, т.е. первая строка lm_logits ). Настоящим наша выборка
стратегия проста: жадно выбрать следующий входной вектор декодера, который
имеет наибольшую вероятность. Затем авторегрессивным образом мы передаем
выбранный входной вектор декодера вместе с предыдущими входными данными для
модель кодировщика-декодера и снова образец.Повторяем это в третий раз.
В результате модель сгенерировала слова «Ич Ич». Первое
слово точное! Второе слово не очень хорошее. Мы можем видеть здесь,
что хороший метод декодирования является ключом к успешной генерации последовательности
из заданного модельного распределения.
На практике используются более сложные методы декодирования для выборки lm_logits . Большинство из них покрыто
это сообщение в блоге.
Что такое трансформатор ?. Введение в трансформаторы и… | Максим | Машинное обучение изнутри
Новые модели глубокого обучения внедряются все чаще, и иногда бывает сложно уследить за всеми новинками.Тем не менее, одна конкретная модель нейронной сети оказалась особенно эффективной для общих задач обработки естественного языка. Модель называется Transformer, и в ней используются несколько методов и механизмов, которые я здесь расскажу. Статьи, на которые я ссылаюсь в посте, предлагают более подробное и количественное описание.
В документе «Внимание — это все, что вам нужно» описываются трансформаторы и так называемая архитектура «последовательность-последовательность». Sequence-to-Sequence (или Seq2Seq) — это нейронная сеть, которая преобразует заданную последовательность элементов, например последовательность слов в предложении, в другую последовательность.(Что ж, это может не удивить вас, учитывая название.)
МоделиSeq2Seq особенно хороши при переводе, когда последовательность слов одного языка преобразуется в последовательность разных слов на другом языке. Популярным выбором для этого типа моделей являются модели на основе Long-Short-Term-Memory (LSTM). С данными, зависящими от последовательности, модули LSTM могут придавать значение последовательности, запоминая (или забывая) те части, которые он считает важными (или неважными). Например, предложения зависят от последовательности, поскольку порядок слов имеет решающее значение для понимания предложения.LSTM — естественный выбор для этого типа данных.
Модели Seq2Seq состоят из кодировщика и декодера. Кодировщик берет входную последовательность и отображает ее в пространство более высокой размерности (n-мерный вектор). Этот абстрактный вектор подается в декодер, который превращает его в выходную последовательность. Последовательность вывода может быть на другом языке, символах, копии ввода и т. Д.
Представьте себе кодировщик и декодер как переводчиков, говорящих только на двух языках. Их первый язык — их родной язык, который у них обоих разный (e.грамм. Немецкий и французский) и их второй общий язык — воображаемый. Для перевода немецкого на французский Encoder преобразует немецкое предложение на другой язык, который он знает, а именно на воображаемый язык. Поскольку декодер может читать этот воображаемый язык, теперь он может переводить с этого языка на французский. Вместе модель (состоящая из кодировщика и декодера) может переводить с немецкого на французский!
Предположим, что изначально ни кодировщик, ни декодер плохо владеют воображаемым языком.Чтобы научиться этому, мы обучаем их (модель) на множестве примеров.
Самый простой выбор для кодировщика и декодера модели Seq2Seq — это один LSTM для каждого из них.
Вам интересно, когда же Трансформер наконец войдет в игру, не так ли?
Чтобы упростить понимание трансформаторов, нам нужна еще одна техническая деталь: Внимание . Механизм внимания смотрит на входную последовательность и на каждом этапе решает, какие другие части последовательности важны.Это звучит абстрактно, но позвольте мне уточнить простой пример: читая этот текст, вы всегда сосредотачиваетесь на прочитанном слове, но в то же время ваш разум по-прежнему удерживает в памяти важные ключевые слова текста, чтобы обеспечить контекст.
Механизм внимания работает аналогично для данной последовательности. Для нашего примера с человеческим кодировщиком и декодером представьте, что вместо того, чтобы записывать только перевод предложения на воображаемом языке, кодировщик также записывает ключевые слова, которые важны для семантики предложения, и передает их декодеру в дополнение к обычному переводу.Эти новые ключевые слова значительно упрощают перевод для декодера, поскольку он знает, какие части предложения важны и какие ключевые термины задают контекст предложения.
Другими словами, для каждого входа, который считывает LSTM (кодировщик), механизм внимания одновременно учитывает несколько других входов и решает, какие из них важны, присваивая этим входам разные веса. Затем декодер примет на вход закодированное предложение и веса, предоставленные механизмом внимания.Чтобы узнать больше о внимании, прочтите эту статью. А для более научного подхода, чем предложенный, прочтите о различных подходах, основанных на внимании, для моделей «последовательность-последовательность» в этой замечательной статье под названием «Эффективные подходы к нейронному машинному переводу на основе внимания».
В статье «Внимание — это все, что вам нужно» представлена новая архитектура под названием Transformer. Как видно из названия, он использует механизм внимания, который мы видели ранее. Как и LSTM, Transformer — это архитектура для преобразования одной последовательности в другую с помощью двух частей (кодировщика и декодера), но она отличается от ранее описанных / существующих моделей последовательностей, поскольку не подразумевает никаких рекуррентных сетей ( ГРУ, LSTM и др.).
Рекуррентные сети до сих пор были одним из лучших способов фиксировать своевременные зависимости в последовательностях. Однако команда, представившая документ, доказала, что архитектура только с механизмами внимания без каких-либо RNN (рекуррентных нейронных сетей) может улучшить результаты в задаче перевода и других задачах! Одно улучшение в задачах естественного языка представлено командой, представляющей BERT: BERT: предварительное обучение глубоких двунаправленных преобразователей для понимания языка.
Итак, что такое трансформатор?
Изображение стоит тысячи слов, поэтому начнем с него!
Рис. 1. Из статьи Vaswani et al.Кодировщик находится слева, а декодер — справа. И кодировщик, и декодер состоят из модулей, которые можно устанавливать друг на друга несколько раз, что описано как Nx на рисунке. Мы видим, что модули состоят в основном из слоев Multi-Head Attention и Feed Forward. Входы и выходы (целевые предложения) сначала встраиваются в n-мерное пространство, поскольку мы не можем использовать строки напрямую.
Одна небольшая, но важная часть модели — позиционное кодирование различных слов.Поскольку у нас нет повторяющихся сетей, которые могут запомнить, как последовательности вводятся в модель, нам нужно каким-то образом присвоить каждому слову / части в нашей последовательности относительное положение, поскольку последовательность зависит от порядка ее элементов. Эти позиции добавляются к встроенному представлению (n-мерному вектору) каждого слова.
Давайте внимательнее рассмотрим эти блоки Multi-Head Attention в модели:
Рисунок 2. Из «Attention Is All You Need» Vaswani et al.Начнем с описания механизма внимания слева.Это не очень сложно и может быть описано следующим уравнением:
Q — матрица, содержащая запрос (векторное представление одного слова в последовательности), K — все ключи (векторные представления всех слов в последовательности) и V — значения, которые снова являются векторными представлениями всех слов в последовательности. Для кодера и декодера, модулей внимания с несколькими головами, V состоит из той же последовательности слов, что и Q. Однако для модуля внимания, который принимает во внимание последовательности кодера и декодера, V отличается от последовательности, представленной Q.
Чтобы немного упростить это, мы могли бы сказать, что значения в V умножаются и суммируются с некоторыми весами внимания a, , где наши веса определяются как:
Это означает, что веса a определены как на каждое слово последовательности (представленной Q) влияют все другие слова в последовательности (представленные K). Кроме того, функция SoftMax применяется к весам и , чтобы иметь распределение между 0 и 1. Эти веса затем применяются ко всем словам в последовательности, которые вводятся в V (те же векторы, что и Q для кодера и декодера, но разные для модуля, имеющего входы кодировщика и декодера).
На рисунке справа показано, как этот механизм внимания можно распараллелить на несколько механизмов, которые можно использовать бок о бок. Механизм внимания повторяется несколько раз с линейными проекциями Q, K и V. Это позволяет системе учиться на различных представлениях Q, K и V, что полезно для модели. Эти линейные представления выполняются путем умножения Q, K и V на весовые матрицы W, которые изучаются во время обучения.
Эти матрицы Q, K и V различны для каждой позиции модулей внимания в структуре в зависимости от того, находятся ли они в кодере, декодере или промежуточном кодере и декодере.Причина в том, что мы хотим обработать либо всю входную последовательность кодера, либо часть входной последовательности декодера. Модуль внимания с несколькими головами, который соединяет кодер и декодер, будет следить за тем, чтобы входная последовательность кодера учитывалась вместе с входной последовательностью декодера до заданной позиции.
После головок с множественным вниманием в кодировщике и декодере у нас есть точечный слой прямой связи. Эта небольшая сеть с прямой связью имеет идентичные параметры для каждой позиции, которые можно описать как отдельное идентичное линейное преобразование каждого элемента из данной последовательности.
ДрессировкаКак дрессировать такого «зверя»? Обучение и вывод на основе моделей Seq2Seq немного отличается от обычной задачи классификации. То же самое и с Трансформерами.
Мы знаем, что для обучения модели задачам перевода нам нужны два предложения на разных языках, которые являются переводами друг друга. Когда у нас будет много пар предложений, мы можем приступить к обучению нашей модели. Допустим, мы хотим перевести с французского на немецкий. Наш закодированный ввод будет предложением на французском языке, а ввод для декодера будет предложением на немецком языке.Однако вход декодера будет смещен вправо на одну позицию. .. Подождите, а почему?
Одна из причин заключается в том, что мы не хотим, чтобы наша модель научилась копировать входные данные декодера во время обучения, но мы хотим узнать, что с учетом последовательности кодера и конкретной последовательности декодера, которая уже была замечена моделью, мы прогнозируем следующее слово / символ.
Если мы не сдвинем последовательность декодера, модель научится просто «копировать» вход декодера, поскольку целевым словом / символом для позиции i будет слово / символ i на входе декодера.Таким образом, сдвигая ввод декодера на одну позицию, наша модель должна предсказать целевое слово / символ для позиции i , увидев только слово / символы 1,…, i-1 в последовательности декодера. Это мешает нашей модели изучить задачу копирования / вставки. Мы заполняем первую позицию ввода декодера токеном начала предложения, поскольку в противном случае это место было бы пустым из-за сдвига вправо. Точно так же мы добавляем маркер конца предложения во входную последовательность декодера, чтобы отметить конец этой последовательности, и он также добавляется к целевому выходному предложению.Через мгновение мы увидим, насколько это полезно для вывода результатов.
Это верно для моделей Seq2Seq и трансформатора. В дополнение к сдвигу вправо, Трансформатор применяет маску к входу в первом модуле внимания с несколькими головами, чтобы не видеть потенциальных «будущих» элементов последовательности. Это характерно для архитектуры Transformer, потому что у нас нет RNN, в которые мы можем вводить нашу последовательность последовательно. Здесь мы вводим все вместе, и если бы не было маски, внимание с несколькими головками рассматривало бы всю входную последовательность декодера в каждой позиции.
Процесс подачи правильного сдвинутого ввода в декодер также называется принудительной подачей учителя, как описано в этом блоге.
Целевая последовательность, которую мы хотим для наших расчетов потерь, — это просто вход декодера (немецкое предложение) без сдвига и с маркером конца последовательности в конце.
ВыводВывод с использованием этих моделей отличается от обучения, что имеет смысл, потому что в конце концов мы хотим перевести французское предложение, не имея немецкого предложения.Уловка здесь заключается в том, чтобы повторно загружать нашу модель для каждой позиции выходной последовательности, пока мы не встретим токен конца предложения.
Еще один пошаговый метод:
- Введите полную последовательность кодировщика (французское предложение), и в качестве входных данных декодера мы берем пустую последовательность с токеном начала предложения на первой позиции. Это выведет последовательность, в которой мы возьмем только первый элемент.
- Этот элемент будет заполнен во второй позиции нашей входной последовательности декодера, которая теперь имеет маркер начала предложения и первое слово / символ в нем.
- Введите в модель как последовательность кодировщика, так и новую последовательность декодера. Возьмите второй элемент вывода и поместите его во входную последовательность декодера.
- Повторяйте это, пока не спрогнозируете токен конца предложения, который отмечает конец перевода.
Мы видим, что нам нужно несколько прогонов нашей модели для перевода нашего предложения.
Я надеюсь, что эти описания сделали архитектуру Transformer немного понятнее для всех, кто начинает с Seq2Seq и структур кодировщика-декодера.
Мы видели архитектуру Transformer и знаем из литературы и авторов «Attention is All you Need», что модель очень хорошо справляется с языковыми задачами. Давайте теперь протестируем Transformer на примере использования.
Вместо задачи перевода давайте реализуем прогноз временных рядов для почасового потока электроэнергии в Техасе, предоставленный Советом по надежности электроснабжения Техаса (ERCOT). Здесь вы можете найти почасовые данные.
Прекрасное подробное объяснение трансформатора и его реализации предоставлено harvardnlp.Если вы хотите глубже изучить архитектуру, я рекомендую пройти через эту реализацию.
Поскольку мы можем использовать последовательные модели на основе LSTM для составления многошаговых прогнозов, давайте взглянем на Трансформатор и его возможности для таких прогнозов. Однако сначала нам нужно внести несколько изменений в архитектуру, поскольку мы работаем не с последовательностями слов, а со значениями. Кроме того, мы делаем авторегрессию, а не классификацию слов / символов.
ДанныеИмеющиеся данные дают нам почасовую нагрузку для всей области управления ERCOT. Я использовал данные с 2003 по 2015 год в качестве обучающей выборки и 2016 года в качестве тестовой. Имея только значение нагрузки и метку времени загрузки, я расширил метку времени на другие функции. Из метки времени я извлек день недели, которому он соответствует, и закодировал его в горячем режиме. Кроме того, я использовал год (2003, 2004,…, 2015) и соответствующий час (1, 2, 3,…, 24) как само значение.Это дает мне в общей сложности 11 функций на каждый час дня. В целях сходимости я также нормализовал нагрузку ERCOT, разделив ее на 1000.
Чтобы предсказать заданную последовательность, нам нужна последовательность из прошлого. Размер этих окон может варьироваться от варианта к варианту использования, но здесь, в нашем примере, я использовал почасовые данные за предыдущие 24 часа, чтобы спрогнозировать следующие 12 часов. Помогает то, что мы можем регулировать размер этих окон в зависимости от наших потребностей. Например, мы можем изменить это на ежедневные данные вместо почасовых данных.
Изменения в модели из бумагиВ качестве первого шага нам нужно удалить вложения, так как у нас уже есть числовые значения во входных данных. Вложение обычно отображает данное целое число в n-мерное пространство. Здесь вместо использования встраивания я просто использовал линейное преобразование для преобразования 11-мерных данных в n-мерное пространство. Это похоже на вложение со словами.
Нам также необходимо удалить слой SoftMax из выходных данных Transformer, потому что наши выходные узлы являются не вероятностями, а реальными значениями.
После этих незначительных изменений можно начинать обучение!
Как уже упоминалось, я использовал принуждение учителя для обучения. Это означает, что кодер получает окно из 24 точек данных в качестве входных данных, а вход декодера представляет собой окно из 12 точек данных, где первая представляет собой значение «начала последовательности», а следующие точки данных представляют собой просто целевую последовательность. Введя значение «начало последовательности» в начале, я сдвинул ввод декодера на одну позицию относительно целевой последовательности.
Я использовал 11-мерный вектор только с -1 в качестве значений «начала последовательности». Конечно, это можно изменить, и, возможно, было бы полезно использовать другие значения в зависимости от варианта использования, но для этого примера это работает, поскольку у нас никогда не бывает отрицательных значений ни в одном из измерений последовательностей ввода / вывода.
Функция потерь для этого примера — это просто среднеквадратичная ошибка.
РезультатыДва графика ниже показывают результаты. Я взял среднее значение почасовых значений за день и сравнил его с правильными значениями.Первый график показывает 12-часовые прогнозы, сделанные за 24 предыдущих часа. Для второго графика мы предсказали один час с учетом предыдущих 24 часов. Мы видим, что модель очень хорошо улавливает некоторые колебания. Среднеквадратичная ошибка для обучающего набора составляет 859, а для набора проверки — 4 106 для 12-часовых прогнозов и 2583 для 1-часовых прогнозов. Это соответствует средней абсолютной процентной ошибке прогноза модели 8,4% для первого графика и 5,1% для второго.
Рисунок 3: 12-часовой прогноз с учетом предыдущих 24 часов за один год Рисунок 4: 1-часовой прогноз с учетом предыдущих 24 часов за один годРезультаты показывают, что можно было бы использовать архитектуру Transformer для прогнозирования временных рядов. Однако во время оценки это показывает, что чем больше шагов мы хотим спрогнозировать, тем выше будет ошибка. Первый график (рис. 3) выше был получен с использованием 24 часов для прогнозирования следующих 12 часов. Если мы спрогнозируем только один час, результаты будут намного лучше, как мы видим на втором графике (рисунок 4).
Есть много места, где можно поиграть с параметрами преобразователя, такими как количество слоев декодера и кодировщика и т. Д. Это не было задумано как идеальная модель, и при лучшей настройке и обучении результаты, вероятно, улучшатся.
Это может быть большим подспорьем для ускорения обучения с использованием графических процессоров. Я использовал локальную платформу Watson Studio для обучения моей модели с помощью графических процессоров, и я позволил ей работать там, а не на моем локальном компьютере. Вы также можете ускорить обучение с помощью графических процессоров Watson Machine Learning, которые бесплатны до определенного времени! Прочтите мой предыдущий блог, чтобы узнать, как это можно легко интегрировать в ваш код.
Большое спасибо за то, что прочитали это, и я надеюсь, что смог прояснить несколько понятий людям, которые только начинают изучать глубокое обучение!
Понимание преобразователей, путь науки о данных
Трансформеры в наши дни фактически стали стандартом для любых задач НЛП. И не только это, но теперь они также используются в компьютерном зрении и для создания музыки. Я уверен, что вы все слышали о трансформаторе GPT3 и его приложениях. Но все это в стороне, их по-прежнему трудно понять.
Мне потребовалось несколько раз прочитать исследовательскую статью Google, в которой впервые были представлены трансформаторы, а также очень много сообщений в блогах, чтобы действительно понять, как работает трансформатор.
Итак, я подумал о том, чтобы изложить всю идею как можно более простыми словами, наряду с некоторыми очень элементарными математическими упражнениями и некоторыми каламбурами, поскольку я сторонник того, чтобы немного повеселиться во время обучения. Я постараюсь свести к минимуму как жаргон, так и технические термины, но это такая тема, на которую я мог бы сделать только так много.И моя цель — заставить читателя понять даже самые жуткие подробности Transformer к концу этого поста.
Кроме того, это официально мой самый длинный пост как с точки зрения времени, затраченного на его написание, так и с точки зрения длины сообщения. Следовательно, я советую вам взять кофе. ☕️
Итак, начнем — этот пост будет очень разговорным, и он о « Decoding The Transformer».
Q: Итак, почему я должен вообще понимать Transformer?
В прошлом архитектура LSTM и GRU (как объяснялось здесь в моем предыдущем посте о НЛП) вместе с механизмом внимания использовались как современный подход к проблемам языкового моделирования (проще говоря, предсказать следующее слово) и перевод системы.Но основная проблема этих архитектур заключается в том, что они рекуррентны по своей природе, и время выполнения увеличивается с увеличением длины последовательности. То есть эти архитектуры берут предложение и обрабатывают каждое слово последовательным образом , и, следовательно, с увеличением длины предложения увеличивается все время выполнения.
Transformer, модельная архитектура, впервые описанная в статье «Внимание — это все, что вам нужно», позволяет отказаться от этого повторения и вместо этого полностью полагается на механизм внимания для определения глобальных зависимостей между вводом и выводом.И это делает его БЫСТРЫМ.
Это изображение полного трансформатора, взятое из бумаги. И это, безусловно, пугает. Итак, я постараюсь развеять мифы в этом посте, пройдя по каждому отдельному фрагменту. Так что читайте дальше.
Общая картина
Q: Звучит интересно. Итак, что именно делает трансформатор?
По сути, преобразователь может выполнять практически любую задачу НЛП.Его можно использовать для языкового моделирования, перевода или классификации по мере необходимости, и он делает это быстро, устраняя последовательный характер проблемы. Таким образом, преобразователь в приложении машинного перевода преобразует один язык в другой или для задачи классификации предоставит вероятность класса с использованием соответствующего выходного уровня.
Все будет зависеть от конечного уровня выходов для сети, но базовая структура Transformer останется неизменной для любой задачи.В этом посте я продолжу пример машинного перевода.
Итак, вот как преобразователь ищет задачу перевода с очень большой высоты. Он принимает в качестве входных данных предложение на английском языке и возвращает предложение на немецком языке.
Трансформатор для перевода ( Изображение автора )
Строительные блоки
В: Это было слишком просто. 😎 Можете ли вы расширить его?
Хорошо, просто помни, в конце концов, ты просил об этом.Давайте пойдем немного глубже и попробуем понять, из чего состоит трансформатор.
Итак, преобразователь по существу состоит из набора слоев кодера и декодера. Роль уровня кодировщика заключается в кодировании английского предложения в числовую форму с использованием механизма внимания, в то время как декодер стремится использовать закодированную информацию из уровней кодировщика, чтобы дать немецкий перевод для конкретного английского предложения.
На рисунке ниже преобразователь представлен в виде предложения на английском языке, которое кодируется с использованием 6 слоев кодировщика.Выходные данные последнего уровня кодировщика затем поступают на каждый уровень декодера для перевода с английского на немецкий.
Поток данных в преобразователе ( Изображение автора )
1. Архитектура кодировщика
В: Ничего страшного, но как стек кодировщика точно кодирует английское предложение?
Терпение, я уже добился этого. Итак, как я уже сказал, стек кодировщика содержит шесть слоев кодировщика друг над другом (как указано в документе, но в будущих версиях преобразователей будет использоваться еще больше слоев).И каждый кодировщик в стеке, по сути, имеет два основных уровня:
- слой самовнимания с несколькими головами и
- Позиционная полностью подключенная сеть прямой связи
Очень простой слой кодировщика ( Изображение автора )
Они полны рта. Верно? Не теряйте меня, поскольку я объясню их оба в следующих разделах. Прямо сейчас просто помните, что уровень кодировщика включает в себя внимание и сеть с прямой связью по положению.
Q: Но как этот уровень ожидает от своих входов?
Этот уровень ожидает, что его входные данные будут иметь форму SxD (как показано на рисунке ниже), где S — длина исходного предложения (английское предложение), а D — размер вложения, веса которого могут быть обучен в сети. В этом посте мы будем использовать D как 512 по умолчанию. В то время как S будет максимальной длиной предложения в пакете.Так что обычно это меняется с партиями.
Кодировщик
— одинаковые формы ввода и вывода ( Изображение автора )
А что с выходами этого слоя? Помните, что слои кодировщика накладываются друг на друга. Итак, мы хотим иметь возможность иметь вывод того же размера, что и ввод, чтобы вывод мог легко перетекать в следующий кодировщик. Таким образом, результат также имеет форму SxD .
Q: Хватит говорить о размерах, я понимаю, что входит, а что выходит, но что на самом деле происходит на уровне кодировщика?
Хорошо, давайте рассмотрим уровни внимания и прямой связи один за другим:
A) Слой самовнимания
Как работает самовнимание ( Изображение автора )
Цифра выше должна показаться устрашающей, но ее легко понять.Так что оставайся здесь со мной.
Deep Learning — это, по сути, не что иное, как множество матричных вычислений, и то, что мы, по сути, делаем на этом уровне, — это много интеллектуальных вычислений матриц. Уровень самовнимания инициализируется тремя матрицами весов — запросом (W_q), ключом (W_k) и значением (W_v). Каждая из этих матриц имеет размер ( Dxd ), где d в документе принимается равным 64. Веса для этих матриц будут обучены при обучении модели.
В первом вычислении (Calc 1 на рисунке) мы создаем матрицы Q, K и V, умножая входные данные на соответствующие матрицы запросов, ключей и значений.
До сих пор это тривиально и не имело никакого смысла, но именно при втором расчете становится интересно. Давайте попробуем разобраться в выводе функции softmax. Мы начинаем с умножения матрицы Q и Kᵀ, чтобы получить матрицу размера ( SxS ), и делить ее на скаляр √d. Затем мы берем softmax, чтобы сумма строк равнялась единице.
Интуитивно мы можем представить результирующую матрицу SxS как вклад каждого слова в другое слово. Например, это может выглядеть так:
Softmax (QxKt / sqrt (d)) ( Изображение автора )
Как видите, записи по диагонали большие.Это потому, что слово «вклад в себя» велико. Это разумно. Но здесь мы видим, что слово «быстрый» превращается в «быстрый» и «лисий», а слово «коричневый» также превращается в «коричневый» и «лисий». Это интуитивно помогает нам сказать, что оба слова — «быстрый» и «коричневый» относятся к «лисе».
Когда у нас есть эта матрица SxS с вкладами, мы умножаем эту матрицу на матрицу значений (Sxd) предложения, и она возвращает нам матрицу формы Sxd (4×64). Итак, на самом деле операция заменяет вектор внедрения слова вроде «быстро» на say.75 x (быстрое внедрение) и .2x (внедрение fox), и, таким образом, теперь результирующий вывод для слова «быстрый» имеет встроенное внимание.
Обратите внимание, что выход этого слоя имеет размер (Sxd), и прежде чем мы закончим со всем кодировщиком, нам нужно изменить его обратно на D = 512, поскольку нам нужен выход этого кодировщика как вход другого кодировщика.
Q: Но вы назвали этот слой Слоем самовнимания с несколькими головами. Что такое мультиголовка?
Ладно, плохо, но, в свою защиту, я как раз подошел к этому.
Это называется мультиголовым, потому что мы используем много таких слоев самовнимания параллельно. То есть у нас есть много слоев самовнимания, наложенных друг на друга. Количество слоев внимания h на бумаге равно 8. Таким образом, входной сигнал X проходит параллельно через множество слоев самовнимания, каждый из которых дает матрицу формы z (Sxd) = 4×64. Мы объединяем эти матрицы 8 (h) и снова применяем окончательный выходной линейный слой Wo размером DxD.
Какой размер у нас получится? Для операции конкатенации мы получаем размер SxD (4x (64×8) = 4×512).И умножая этот результат на Wo, мы получаем окончательный результат Z с формой SxD (4×512), как и нужно.
Также обратите внимание на соотношение между h, d и D, т. Е. H x d = D
Слой полного многоголового самовнимания ( Изображение автора )
Таким образом, мы наконец получили результат Z формы 4×512, как и предполагалось. Но прежде чем он попадет в другой кодировщик, мы передаем его через прямую сеть.
B) Позиционная сеть прямой связи
Как только мы разберемся в многоголовом слое внимания, сеть прямого распространения становится довольно легко понять.Это просто комбинация различных линейных и выпадающих слоев на выходе Z. Следовательно, здесь снова просто много умножения Матрицы.
Каждое слово попадает в сеть прямой связи. ( Изображение автора )
Сеть прямой связи применяется к каждой позиции на выходе Z параллельно (каждую позицию можно представить как слово), отсюда и название — Сеть прямой связи по позициям. Сеть с прямой связью также имеет общий вес, так что длина исходного предложения не имеет значения (кроме того, если бы она не разделяла веса, нам пришлось бы инициализировать множество таких сетей на основе максимальной длины исходного предложения и этого невозможно)
На самом деле это просто линейный слой, который применяется к каждой позиции (или слову) ( Изображение автора )
Таким образом, мы близки к хорошему пониманию кодирующей части трансформатора.
Q: Привет, я только что просматривал картинку в статье, и в стеке кодировщика есть что-то, называемое «позиционным кодированием», а также «Add & Norm». Что это?
Я снова здесь, поэтому вам не нужно прокручивать «Источник»
Хорошо, эти две концепции очень важны для этой конкретной архитектуры. И я рад, что вы спросили об этом. Итак, мы обсудим эти шаги, прежде чем переходить к стеку декодера.
С.Позиционные кодировки
Поскольку наша модель не содержит повторений и сверток, для того, чтобы модель могла использовать порядок последовательности, мы должны ввести некоторую информацию об относительном или абсолютном положении токенов в последовательности. С этой целью мы добавляем «позиционные кодировки» к входным вложениям в нижней части стеков кодировщика и декодера (как мы увидим позже). Позиционные кодировки должны иметь тот же размер D, что и вложения, чтобы их можно было суммировать.
Добавить статический позиционный шаблон к X ( Изображение автора )
В статье авторы использовали функции синуса и косинуса для создания позиционных вложений для различных позиций.
Эта конкретная математическая вещь фактически генерирует 2-мерную матрицу, которая добавляется к вектору внедрения, который идет на первом этапе кодировщика.
Проще говоря, это просто постоянная матрица, которую мы добавляем к предложению, чтобы сеть могла получить позицию слова.
Матрица позиционного кодирования для первых 300 и 3000 позиций ( Изображение автора )
Выше показана тепловая карта матрицы кодирования положения, которую мы добавим к входным данным, которые должны быть переданы первому кодировщику. Я показываю тепловую карту для первых 300 позиций и первых 3000 позиций. Мы видим, что есть отдельный шаблон, который мы предоставляем нашему преобразователю, чтобы понимать положение каждого слова. И поскольку мы используем функцию, состоящую из sin и cos, мы можем встраивать позиционные вложения для очень высоких позиций, как мы можем видеть на втором рисунке.
Интересный факт: Авторы также позволили Transformer изучить эти кодировки и не увидели никакой разницы в производительности как таковой. Итак, они согласились с вышеупомянутой идеей, поскольку она не зависит от длины предложения, и поэтому, даже если тестовое предложение больше, чем образцы поездов, все будет в порядке.
D. Сложить и нормализовать
Еще одна вещь, которую я не упомянул для простоты при объяснении кодировщика, это то, что архитектура кодировщика (а также архитектура декодера) также имеет остаточные соединения с пропуском уровня (что-то вроде resnet50).Итак, точная архитектура кодировщика в статье выглядит так, как показано ниже. Проще говоря, он помогает передавать информацию на гораздо большую длину в глубокой нейронной сети. Это можно рассматривать как сродни (интуитивно) передаче информации в организации, где у вас есть доступ как к своему руководителю, так и к руководителю вашего менеджера.
Уровень пропуска соединений помогает потоку информации в сети ( Изображение автора )
2. Архитектура декодера
Q: Итак, до сих пор мы узнали, что кодировщик принимает входное предложение и кодирует его информацию в матрицу размера SxD (4×512).Это все здорово, но как это помогает декодеру декодировать его на немецкий язык?
Хорошие вещи приходят к тем, кто ждет. Итак, прежде чем понимать, как это делает декодер, давайте разберемся со стеком декодера.
Стек декодера содержит 6 слоев декодера в стеке (как снова указано в документе), и каждый декодер в стеке состоит из следующих трех основных слоев:
- Маскированный слой самовнимания с несколькими головами
- Слой самовнимания с несколькими головками и
- Позиционная полностью подключенная сеть прямой связи
Он также имеет такое же позиционное кодирование и соединение уровня пропуска.Мы уже знаем, как работают сетевые уровни с многоголовым вниманием и прямой связью, поэтому сразу разберемся, чем отличается декодер от кодировщика.
Архитектура декодера ( Изображение автора )
Q: Подождите, но вижу ли я, что требуемый вывод поступает в декодер в качестве ввода? Какие? Почему? 😖
Я заметил, что вы довольно хорошо умеете задавать вопросы. И это отличный вопрос, который я часто задавал себе, и я надеюсь, что он станет более ясным к тому времени, когда вы дойдете до конца этого поста.
Но, чтобы дать интуицию, в этом случае мы можем рассматривать преобразователь как модель условного языка. Модель, которая предсказывает следующее слово с учетом входного слова и предложения на английском языке, на котором будет основываться его предсказание.
Такие модели по своей сути последовательны, например, как бы вы обучили такую модель? Вы начинаете с предоставления начального токена ( ), и модель предсказывает первое слово, обусловленное английским предложением. Вы меняете веса в зависимости от того, верен ли прогноз или нет.Затем вы даете начальный токен и первое слово ( ), и модель предсказывает второе слово. Вы снова меняете вес. И так далее. der
Трансформаторный декодер учится именно так, но прелесть в том, что он не делает это последовательно. Он использует маскирование для выполнения этого вычисления и, таким образом, берет все выходное предложение (хотя и сдвигается вправо путем добавления токена на передний план) во время обучения. Также обратите внимание, что во время прогнозирования мы не передаем результат в сеть
Q: Но как именно это маскирование работает?
A) Маскированный слой самовнимания с несколькими головками
Работает, как обычно, носишь я имею ввиду 😷 .Шучу в сторону, как вы можете видеть, на этот раз у нас есть слой внимания Masked Multi-Head в нашем декодере. Это означает, что мы замаскируем наш сдвинутый вывод (то есть ввод в декодер) таким образом, чтобы сеть никогда не могла видеть последующие слова, поскольку в противном случае она может легко скопировать это слово во время обучения.
Итак, как именно маска работает на слое замаскированного внимания? Если вы помните, в слое внимания мы умножили запрос (Q) и ключи (K) и разделили их на sqrt (d), прежде чем брать softmax.
Однако в слое замаскированного внимания мы добавляем результирующую матрицу перед softmax (которая будет иметь форму (TxT)) к маскирующей матрице.
Итак, в маскированном слое функция меняется с:
( Изображение автора )
В: Я все еще не понимаю, что будет, если мы это сделаем?
Это вообще-то понятно. Позвольте мне разбить его по шагам. Итак, наша результирующая матрица (QxK / sqrt (d)) формы (TxT) может выглядеть примерно так: (Числа могут быть большими, поскольку softmax еще не применен)
Schnelle в настоящее время обслуживает как Braune, так и Fuchs ( Изображение автора )
Слово Schnelle теперь будет состоять из Braune и Fuchs, если мы возьмем softmax указанной выше матрицы и умножим его на матрицу значений V.{-inf} = 0, все позиции после Шнелле были преобразованы в 0. Теперь, если мы умножим эту матрицу на матрицу значений V, вектор, соответствующий позиции Шнелле в векторе Z, проходящем через декодер, не будет содержать никакой информации. следующих слов Braune и Fuchs, как мы и хотели.
И вот так преобразователь сразу берет все сдвинутое выходное предложение и не учится последовательно. Должен сказать, довольно аккуратно.
В: Вы издеваетесь? Это действительно здорово.
Так рада, что ты все еще со мной, и ты это ценишь. Теперь вернемся к декодеру. Следующий уровень в декодере:
B) Слой многоголового внимания
Как вы можете видеть в архитектуре декодера, вектор Z (выходной сигнал кодировщика) течет от кодера к слою внимания с несколькими головками в декодере. Этот Z-выход последнего кодировщика имеет особое имя и часто называется памятью. Слой внимания принимает в качестве входных данных как выходные данные кодировщика, так и данные, поступающие снизу (смещенные выходы), и использует внимание.Вектор запроса Q создается из данных, текущих в декодере, в то время как ключевые (K) и значения (V) векторы поступают из выходных данных кодировщика.
Q: А маски нет?
Нет, маски здесь нет. Выходные данные, поступающие снизу, уже замаскированы, и это позволяет каждой позиции в декодере охватить все позиции в векторе значений. Таким образом, для каждой генерируемой позиции слова декодер имеет доступ ко всему английскому предложению.
Вот один слой внимания (который, как и раньше, будет частью мультиголовки):
( Изображение автора )
Q: Но разве на этот раз формы Q, K и V не будут другими?
Вы можете посмотреть на рисунок, на котором я произвел все расчеты веса.Я также хотел бы попросить вас увидеть формы результирующего вектора Z и то, как наши весовые матрицы до сих пор никогда не использовали целевую или исходную длину предложения ни в одном из своих измерений. Обычно форма сокращается во всех наших матричных вычислениях. Например, посмотрите, как размер S сокращается в вычислении 2 выше. Поэтому при выборе партий при обучении авторы говорят о плотных партиях. То есть в пакете все исходные предложения имеют одинаковую длину. И разные партии могут иметь разную длину источника.
Теперь я расскажу о соединениях уровня пропуска и уровне прямой связи. На самом деле они такие же, как в….
Q: Хорошо, я понял. У нас есть соединения уровня пропуска и слой FF, и мы получаем матрицу формы TxD после всей этой операции декодирования. а где немецкий перевод?
3. Выходная головка
Мы действительно очень там друг. После того, как мы закончили с трансформатором, следующее — добавить выходную головку для конкретной задачи в верхней части выхода декодера.Это можно сделать, добавив несколько линейных слоев и softmax сверху, чтобы получить вероятность для всех слов в немецком словаре . Мы можем сделать что-то вроде этого:
( Изображение автора )
Как видите, мы умеем генерировать вероятности. Пока мы знаем, как выполнить прямой проход через эту архитектуру Transformer. Давайте посмотрим, как мы обучаем такую архитектуру нейронной сети.
Обучение:
До сих пор, если мы посмотрим на структуру с высоты птичьего полета, мы получим что-то вроде:
( Изображение автора )
Мы можем дать английское предложение и сдвинутое выходное предложение, выполнить прямой проход и получить вероятности по немецкой лексике.Таким образом, мы должны иметь возможность использовать функцию потерь, такую как кросс-энтропия, где целью может быть нужное нам немецкое слово, и обучать нейронную сеть с помощью Adam Optimizer. Как и любой пример классификации. Итак, вот ваш немецкий.
Однако в статье авторы используют небольшие вариации оптимизаторов и потерь. Если хотите, вы можете пропустить следующие 2 раздела по графику потери дивергенции KL и скорости обучения с Адамом, поскольку это делается только для увеличения производительности модели, а не неотъемлемой части архитектуры Transformer как таковой.
Q: Я здесь так долго и жаловался ли я? 😒
Хорошо. Хорошо. Я тебя понимаю. Тогда давай.
A) Расхождение KL со сглаживанием этикеток:
KL Дивергенция — это потеря информации, которая происходит, когда распределение P аппроксимируется распределением Q. Когда мы используем KL Дивергентные потери, мы пытаемся оценить целевое распределение (P), используя вероятности (Q), которые мы генерируем из модели. .И мы стараемся минимизировать эту потерю информации при обучении.
( Изображение автора )
Если вы заметили, в этой форме (без сглаживания меток, которое мы обсудим) это в точности то же самое, что и кросс-энтропия. Учитывая два распределения, как показано ниже.
Целевое распределение и распределение вероятностей для слова (токена) ( Изображение автора )
Простая формула расхождения KL дает -logq (oder) , и это потеря кросс-энтропии.
В статье, хотя авторы использовали сглаживание меток с α = 0,1, поэтому потеря KL-дивергенции не является кросс-энтропией. Это означает, что в целевом распределении выходное значение заменяется на (1-α), а оставшиеся 0,1 распределяются по всем словам. Авторы говорят, что это для того, чтобы модель не была слишком уверенной.
( Изображение автора )
В: Но почему мы делаем наши модели неуверенными? Это кажется абсурдным.
Да, но интуитивно, вы можете думать об этом так, как если бы мы присвоили цели 1 нашей функции потерь, у нас нет сомнений в том, что истинная метка — Истина, а другие — нет. Но словарный запас по своей сути является нестандартной целью. Например, кто сказал, что нельзя использовать хорошее вместо великого? Поэтому мы добавляем путаницу в наши надписи, чтобы наша модель не была слишком жесткой.
B) Определенный график скорости обучения с Адамом
Авторы используют планировщик скорости обучения, чтобы увеличить скорость обучения до этапов разминки, а затем уменьшить ее с помощью функции ниже.И они использовали оптимизатор Adam с β¹ = 0,9, β² = 0,98. Здесь нет ничего слишком интересного, только несколько вариантов обучения.
Q: Но подождите, я только что вспомнил, что у нас не будет сдвинутого вывода во время предсказания, не так ли? Как же тогда делать прогнозы?
Если вы понимаете, что на данный момент у нас есть генеративная модель, и нам придется делать прогнозы генеративным способом, поскольку мы не будем знать выходной целевой вектор при прогнозировании.Так что прогнозы по-прежнему последовательны.
Время прогноза
Прогнозирование с помощью жадного поиска с помощью Transformer ( Изображение автора )
Эта модель делает предсказания по кусочкам. В исходной статье для прогнозирования используется поиск луча. Но жадный поиск тоже подойдет для объяснения этого. В приведенном выше примере я показал, как именно будет работать жадный поиск. Жадный поиск начнется с:
- Передача всего предложения на английском языке в качестве входных данных кодировщика и только начального токена
- Модель предсказывает следующее слово —
der - Затем мы передаем все английское предложение в качестве входных данных кодировщика и добавляем последнее предсказанное слово к смещенному выходу (вход в декодер =
der - Модель предсказывает следующее слово —
schnelle - Передача всего предложения на английском языке в качестве входных данных кодировщика и
der schnelle , - и так далее, пока модель не спрогнозирует конечный токен
Q: Теперь жадный, расскажите еще про поиск луча.
Хорошо, идея поиска луча по своей сути очень похожа на вышеупомянутую идею. В лучевом поиске мы смотрим не просто на слово с наибольшей вероятностью, а на два верхних слова.
Итак, например, когда мы дали все английское предложение в качестве входных данных кодировщика и только начальную лексему в качестве сдвинутого выхода, мы получили два лучших слова как i (p = 0,6) и der (p = 0,3). Теперь мы сгенерируем выходную модель для обеих выходных последовательностей, и i , и посмотрим на вероятность сгенерированного следующего верхнего слова. Например, если der дает вероятность (p = 0,05) для следующего слова, а i дает (p = 0.5) для следующего предсказанного слова мы отбрасываем последовательность der> и вместо этого используем i , поскольку сумма вероятностей предложения максимальна ( der p = 0,3+ 0,5 по сравнению с der next_word_to_der p = 0,6 + 0,05). Затем мы повторяем этот процесс, чтобы получить предложение с наибольшей вероятностью. i next_word_to_i
Так как мы использовали верхние 2 слова, размер луча для этого поиска луча равен 2. В статье они использовали лучевой поиск размера 4.
PS : Я для краткости показал, что английское предложение передается на каждом шаге, но на практике вывод кодера сохраняется, и только сдвинутый вывод проходит через декодер на каждом временном шаге.
В: Вы что-нибудь еще забыли мне сказать? Я дам тебе шанс.
Да. С тех пор, как вы спросили. Вот он:
BPE, Разделение веса и контрольные точки
В статье авторы использовали кодирование пар байтов для создания общего англо-немецкого словаря.Затем они использовали общие веса как для английского, так и для немецкого вложения и линейное преобразование pre-softmax, поскольку форма матрицы встраиваемых весов будет работать (длина словаря X D).
Кроме того, авторы усредняют последние k контрольных точек для создания эффекта объединения для достижения производительности . Это довольно известный метод, при котором мы усредняем веса за последние несколько эпох модели, чтобы создать новую модель, которая является своего рода ансамблем.
Q: Вы можете показать мне код?
Этот пост уже такой длинный, так что я сделаю это в следующем посте.Будьте на связи.
Теперь, наконец, моя очередь задать вопрос: вы поняли, как работает трансформатор? Да или Нет, можете ответить в комментариях. 🙂
Ссылки
В этом посте я рассмотрел, как работает архитектура Transformer, с детальной, интуитивно понятной точки зрения.
Если вы хотите узнать больше о НЛП, я хотел бы назвать отличный курс Обработка естественного языка из специализации «Продвинутое машинное обучение».Проверьте это.
Я собираюсь писать больше таких постов в будущем. Дай мне знать, что ты о них думаешь. Должен ли я писать на технические темы или статьи для начинающих? Раздел комментариев — ваш друг. Используй это. Кроме того, подпишитесь на меня на Medium или подпишитесь на мой блог .
И, наконец, небольшой отказ от ответственности — в этом посте могут быть некоторые партнерские ссылки на соответствующие ресурсы, так как обмен знаниями никогда не является плохой идеей.
Эта история была впервые опубликована здесь .
Биография: Рахул Агарвал — старший статистический аналитик в WalmartLabs. Следуйте за ним в Twitter @mlwhiz.
Оригинал. Размещено с разрешения.
Связанный:
Решение проблем безопасности и надежности больших силовых трансформаторов
Большие силовые трансформаторы (LPT) имеют решающее значение для национальной энергосистемы, так как более 90 процентов потребляемой мощности в какой-то момент проходит через высоковольтные трансформаторы. Однако LPT сталкиваются с рядом проблем, которые делают их одними из наиболее уязвимых компонентов сети.Они дороги, их трудно транспортировать, и, как правило, они изготавливаются по индивидуальному заказу, а сроки поставки составляют один год или более. Многие из используемых в настоящее время LPT вышли из своего пикового возраста. Кроме того, LPT могут подвергаться воздействию природных и антропогенных угроз, с которыми сталкивается национальная энергосистема, включая суровые погодные условия, космическую погоду и атаки. Потеря критически важных LPT может нарушить работу электроснабжения на большой территории страны. Поскольку национальная безопасность и экономика зависят от надежной подачи электроэнергии, последствия длительных отключений из-за потери одного или нескольких LPT вызывают серьезную озабоченность.
На протяжении многих лет OE работала с частными и государственными партнерами для повышения осведомленности и решения проблем внутреннего производства и транспортировки посредством информационно-пропагандистской работы и технической помощи. Обеспокоенность по поводу ограниченного внутреннего производства в результате таких событий, как геомагнитные возмущения (GMD) и электромагнитные импульсы (EMP), обсуждалась на семинаре по высокоэффективным низкочастотным (HILF) рискам 2009 года и в итоговом отчете. В отчете OE «Большие силовые трансформаторы и электрическая сеть США», первоначально выпущенном в 2012 году и обновленном в 2014 году, также исследуется ряд вопросов, связанных с LPT, включая характеристики и закупку LPT, исторические тенденции и будущие потребности, а также риски, с которыми сталкиваются LPT. .
Основываясь на постоянном взаимодействии с заинтересованными сторонами в отрасли, OE разработала стратегию космической погоды для решения проблем, связанных с более широким воздействием экстремальных явлений GMD на трансформаторы и надежность сети. Программа GMD OE проанализировала влияние эталонного 100-летнего события GMD, изучила восприимчивость трансформаторов к событиям GMD и развернула датчики для измерения геомагнитно-индуцированных токов (GIC) и для повышения усилий по моделированию системы. Эти усилия помогли OE внести свой вклад в разработку Национальной стратегии по космической погоде и сопутствующего Плана действий, выпущенного Управлением по научно-технической политике (OSTP) Белого дома в 2015 году.OE продолжает работать с OSTP и другими федеральными агентствами и в настоящее время разрабатывает требования и план по обеспечению общесистемного обзора GIC в режиме реального времени на региональном уровне.
OE также изучает риск ЭМИ и исследует, как уменьшить их влияние на трансформаторы и надежность сети. В начале 2016 года OE и Исследовательский институт электроэнергетики (EPRI) разработали Совместную стратегию устойчивости к электромагнитным импульсам (EMP) для сети и в настоящее время совместно разрабатывают планы действий по реализации этой стратегии.Кроме того, в национальных лабораториях Министерства энергетики в настоящее время проводится несколько исследований ЭМИ.
В свете этих угроз, все более мощных штормов и потенциальных террористических атак, в четырехгодичном обзоре энергетики за 2015 г. рекомендуется, чтобы «Министерство энергетики возглавило — в координации с DHS и другими федеральными агентствами, штатами и отраслью — инициативу по снижению связанных с этим рисков. с потерей трансформаторов. Подходы к снижению этого риска должны включать разработку одного или нескольких резервов трансформатора посредством поэтапного процесса.В ответ на это в июле 2015 года OE выпустило запрос на информацию с просьбой прокомментировать возможное создание резерва LPT, которые поддержали бы восстановление национальной энергосистемы.
Закон об исправлении наземного транспорта в Америке (FAST) 2015 г. требует от Министерства энергетики представить Конгрессу план оценки возможности создания Стратегического резерва трансформаторов для хранения на стратегически расположенных объектах запасного оборудования в достаточном количестве для временной замены критически поврежденных LPT.В январе 2016 года OE поручил технический компонент этого важного анализа команде, возглавляемой Окриджской национальной лабораторией. В команду проекта входили исследователи из Университета Теннесси-Ноксвилл, Сандийской национальной лаборатории, EPRI и Dominion Virginia Power. Отчет о резерве стратегических трансформаторов для Конгресса доступен ЗДЕСЬ.
Помимо информирования, мониторинга, технической помощи и анализа, OE также поддерживает исследования и разработку инновационных решений.Например, OE и промышленность призвали Министерство внутренней безопасности (DHS) профинансировать разработку концепции восстановительного трансформатора, которая сократит время, необходимое для замены поврежденного LPT. DHS завершило проект Recovery Transformer (RecX) в сотрудничестве с EPRI, ABB, CenterPoint Energy и DOE в марте 2013 года. Проект включал годовые полевые испытания.
Другие текущие исследования включают усилия программы OE Transformer Resilience and Advanced Components (TRAC).Портфель программы TRAC включает моделирование, тестирование и разработку компонентов для расширения возможностей трансформаторов и других критически важных компонентов энергосистемы, чтобы сделать энергосистему будущего более устойчивой. Объявление о возможностях финансирования «Трансформаторы нового поколения — гибкие конструкции», выпущенное в июне 2016 года, было посвящено новым концепциям дизайна, которые способствуют большей стандартизации, чтобы увеличить возможность совместного использования LPT в случае потери одного или нескольких трансформаторов. 28 сентября 2016 года финансирование более 1 доллара.Было объявлено о выделении 5 миллионов долларов нового финансирования, чтобы позволить корпорациям, малому бизнесу и академическим учреждениям в Джорджии, Иллинойсе, Нью-Йорке и Северной Каролине создавать новые конструкции, которые помогут производить следующее поколение LPT.
Кроме того, через GMLC была выбрана группа под руководством Окриджской национальной лаборатории (ORNL) и Ливерморской национальной лаборатории Лоуренса для проведения моделирования и тестирования трансформаторов с целью улучшения понимания уязвимостей к воздействию событий GMD и EMP.Проверенные модели могут использоваться для улучшения конструкции LPT и производственных требований. Другая группа, возглавляемая Тихоокеанской северо-западной национальной лабораторией и ORNL, была выбрана для разработки и оценки новых стратегий управления для систем постоянного тока высокого напряжения (HVDC) для уменьшения перегрузок и циркуляционных потоков, а также обеспечения синтетической инерции. Возможности, разработанные в рамках этого проекта, могут быть применены для изменения потоков электроэнергии в системе во время аварийных ситуаций, чтобы минимизировать критичность подстанций и связанных с ними LPT.
Поскольку мы продолжаем заниматься этим важным аспектом помощи в обеспечении надежности и отказоустойчивости национальной энергосистемы с помощью этих различных мероприятий, жизненно важно постоянное сотрудничество с коммунальными предприятиями, научными кругами, поставщиками оборудования, регулирующими органами и другими заинтересованными сторонами.
Расшифровка энергетического кризиса в Пенджабе: «Практически без кабелей»; Инсайдеры PSPCL указывают на острую нехватку критически важных материалов и рабочих рук
За энергетическим кризисом, с которым столкнулся Пенджаб в пик летнего сезона, стоит острая нехватка материалов и людей, необходимых для поддержания работоспособности сети снабжения в условиях частых поломок.
В Пенджабе сезон рисовых полей начался с 10 июля, и заявления PSPCL о бесперебойной подаче электроэнергии стали известны вскоре после того, как проливной дождь и сильный ветер парализовали электроснабжение.
Источники сообщили, что в PSPCL отсутствуют необходимые поставки распределительных трансформаторов, кабелей из сшитого полиэтилена (сшитого полиэтилена) на 11 кВ, опор, кабелей низкого напряжения (низкого напряжения) и шунтирующих конденсаторов на 11 кВ. Запас трансформаторов составляет около 25 процентов от необходимого количества.
«Согласно полученным нами документам, количество трансформаторов всей необходимой мощности составляет около 17 000 против средней потребности более 67 000, поскольку степень повреждения трансформаторов максимальна во время рисового сезона из-за перегрузки.
Кроме того, несмотря на потребность примерно в 16 000 трансформаторов для 10/25 кВА, PSPCL имеет в запасе около 4700 и 4100 трансформаторов соответственно », — сказал В. К. Гупта, представитель Всеиндийской инженерной федерации. Он добавил, что нехватка материалов наблюдается каждый год, но в этом году ситуация хуже всего, будь то распределительные трансформаторы, изоляторы, кабели и кабельные коробки. Теперь руководство пытается возложить вину на пандемию, чтобы скрыть свои неудачи, сказал Гупта.
В случае кабелей с изоляцией из сшитого полиэтилена 11 кВ магазины PSPCL показывают доступность длиной около 91 км против среднего потребления за последние три года во время рисового сезона, составляющего около 160 км, согласно источникам.
Источники добавили, что наличие 2-х или 4-х жильных кабелей разных размеров также меньше по сравнению со средним потреблением за последние три сезона рисовых полей.
Рекорд показывает наличие 900 км двухжильных кабелей при средней потребности в 7000 км. Наличие 4-жильных кабелей разных размеров в магазинах PSPCL составляет четверть от требуемой.
«PSPCL не смогла закупить материалы, необходимые для надлежащего обслуживания системы распределения электроэнергии.Практически нет кабелей, будь то кабель LT или кабели из сшитого полиэтилена 11 кВ разных размеров для проведения ремонтных работ », — сказал главный инженер.
Ввиду низких запасов критически важных элементов распределение материалов было поручено главным инженерам, и их попросили отрегулировать их использование таким образом, чтобы не возникало серьезных проблем во время рисового сезона.
«Закупка материалов для чрезвычайных ситуаций теперь поручена комитетам по закупкам на местах, что ставит под угрозу качество закупаемых материалов», — сказал Гупта.
«Высшее руководство попросило всех супервизоров (SE) не обращаться к ним за материалами, а вместо этого они должны согласовывать свои требования с разными главными инженерами. Инженеры беспокоятся о трудностях, связанных с отсутствием необходимого материала », — сказал инженер-суперинтендант PSPCL, добавив, что требуется независимый министр энергетики, поскольку портфель проектов уже давно находится в офисе КМ.
«Политические принуждения и обещания опросов нанесут огромный урон государственным финансам в год выборов, и, возможно, он не сможет очистить закон о субсидиях на электроэнергию, который неуклонно увеличивался до 17 796 крор, включая задолженность, что составляет более 10 евро. процентов от общего бюджета Пенджаба », — сказал другой главный инженер, добавив, что Комиссия по регулированию электроэнергетики штата Пенджаб (PSERC) уже разработала субсидию в размере 10 668 крор, подлежащую выплате различным категориям потребителей.
Гупта добавил: «Финансовое здоровье PSPCL полностью зависит от своевременной выплаты субсидии. Эти деньги в основном используются для покупки электроэнергии во время рисового сезона ».
Старший офицер PSPCL сказал, что история корпорации — это история нехватки людей и материалов. «Из-за ненадлежащего планирования не было организовано ни достаточного количества персонала, ни достаточного количества материалов, и теперь претензии руководства относительно адекватной доступности электроэнергии становятся очевидными из-за периодических отключений электроэнергии и недостаточного электроснабжения сельскохозяйственных потребителей», — сказал он.
«Согласно предоставленным нами документам, в PSPCL наблюдается острая нехватка персонала, поскольку более 50 процентов должностей вакантны», — сказал
Гупта, добавив, что инженеры предупредили руководство PSPCL, что в случае любой неудачи на тепловых станциях из-за нехватки персонала они не должны нести ответственности.
Эксплуатация всех четырех блоков в термальных источниках Ропар и Лехра Мохаббат со скелетным персоналом может привести к катастрофе, предупредил он.
«Согласно заявлению о вакансиях на 21 мая для компании Ropar Thermal, есть 32 должности помощников инженеров-исполнителей и помощников инженеров (AEE / AE), которые остаются вакантными в производственном цикле, который отвечает за эксплуатацию теплоцентрали.Департамент нанял 5 инженеров на пенсии на сезон рисовых полей в качестве специальной договоренности. Нет персонала, который бы следил за работой вспомогательного оборудования, и большинство объектов остаются без персонала », — сказал источник.
Гупта также сообщил, что система распределения электроэнергии в сельской местности передана на аутсорсинг и находится в аварийном состоянии.
Между тем, А. Вену Прасад, председатель и управляющий директор (CMD), во время разговора с Indian Express сказал: «Нет сомнений в том, что из-за Covid наши производственные предприятия также были закрыты, а линия поставок в какой-то степени пострадала, и теперь у нас нет Излишки материала, но в то же время нет недостатка в материалах, которые нам нужны для обслуживания и ремонта, которые закупаются и поставляются.”
По поводу нехватки трансформаторов он сказал: «Зачем нам заранее хранить огромное количество трансформаторов. Где бы это ни потребовалось, мы их поставим ».
Другой старший офицер PSPCL на условиях анонимности сказал, что существует острая необходимость в обновлении всей инфраструктуры электроснабжения по всему штату.
Умные трансформаторысделают сеть более чистой и гибкой
Трудно переоценить важность трансформаторов в наших электрических сетях.Они буквально везде: на столбах и площадках, на подстанциях и в частной собственности, на земле и под ней. В одном только вашем районе их, наверное, десятки. Без них сложно представить мир. Но мы с коллегами именно этим и занимаемся.
В распределительной системе трансформаторы обычно принимают средние или «первичные» напряжения, измеряемые в тысячах вольт, и преобразуют их во вторичные напряжения, такие как 120, 240 или 480 вольт, которые могут быть безопасно доставлены в дома и на предприятия. по всему миру.Этот подход использовался еще до того, как переменный ток выиграл войну токов в 1892 году. Трудно назвать другую электротехнологию, которая выжила бы так долго.
Тем не менее, пора начать думать за пределами обычного трансформатора. Во-первых, трансформаторы громоздкие. Они часто охлаждаются маслом, которое может протекать и его трудно утилизировать безопасным образом. Что особенно важно, трансформаторы — это пассивные инструменты с односторонним движением. Они не предназначены для адаптации к быстро меняющимся нагрузкам.Этот недостаток быстро станет недопустимым, поскольку распределенные источники энергии, такие как ветряные турбины, солнечные панели и батареи электромобилей, подают в сеть все больше и больше энергии.
К счастью, исследования нового типа технологии, способной устранить все эти ограничения, достигли значительных успехов. Благодаря последним достижениям в области силовой электроники мы теперь можем задуматься о создании интеллектуальных, эффективных «твердотельных трансформаторов» или SST. Они обещают справиться с задачами, которые сложно, если вообще возможно, выполнить с помощью обычного трансформатора, например, управлять очень изменчивым двусторонним потоком электроэнергии между, скажем, микросетью и основной сетью.Более того, эти интеллектуальные трансформаторы могут быть модульными, что упрощает их транспортировку и установку. И они могут быть значительно меньше, чем аналогичный обычный трансформатор — примерно вдвое меньше по весу и втрое меньше по объему.
В ближайшем будущем SST могут стать благом для аварийного восстановления в местах с поврежденной электрической инфраструктурой и для таких объектов, как военно-морские суда, где объем и вес имеют большое значение. Кроме того, в будущем они могли бы переопределить электрическую сеть, создав распределительные системы, способные принять большой приток возобновляемой и накопленной энергии, резко повысив стабильность и энергоэффективность процесса.
Сети переменного тока используют напряжения в сотни тысяч вольт для передачи энергии на большие расстояния. Но по мере того, как ток приближается к нагрузке, напряжение должно снова упасть. Таким образом, трансформаторы используются по всей сети, чтобы повысить электрическое напряжение, выходящее с электростанции, до высокого напряжения, чтобы его можно было передавать с большой эффективностью, и понизить его на стороне распределения до уровней, подходящих для электростанций и предприятий. , и дома.
Несмотря на то, что трансформатор много раз совершенствовался на протяжении многих лет, это, по сути, технология 19-го века, в которой используются простые принципы электромагнетизма. В самом базовом варианте на магнитопровод намотаны две катушки. Поскольку переменный ток, проходящий через одну катушку провода — первичную — изменяется со временем, он создает магнитное поле в сердечнике, которое также изменяется во времени. Это изменяющееся магнитное поле, в свою очередь, индуцирует переменный ток и напряжение в другой катушке — вторичной обмотке.Отношение входного или первичного напряжения к выходному или вторичному напряжению определяется соотношением витков в первичной и вторичной катушках.
Трансформаторы обладают рядом замечательных свойств. Они эффективны и надежны, а также обладают очень полезной функцией, называемой гальванической развязкой. Поскольку входная и выходная стороны трансформатора связаны только магнитными полями, ток не может протекать напрямую через устройство от первичной к вторичной стороне.Эта изоляция является важной мерой безопасности, которая помогает предотвратить попадание электричества высокого напряжения в места, куда оно не должно попадать.
Некоторые трансформаторы способны выдерживать определенную изменчивость. Распределительные трансформаторы могут быть оснащены переключателем ответвлений, который механически переключает между различными частями катушки, уменьшая или увеличивая количество витков, чтобы уменьшить или увеличить напряжение в ответ на большие изменения нагрузки.
Но эти трансформаторы с отводами не подходят для частых и больших перепадов напряжения, которые могут происходить в настоящее время.Вместо того, чтобы менять один или два раза в день, как это было много лет назад, переключатели ответвлений теперь могут легко менять положение более десятка раз, что приводит к значительному износу.
Если бы мы могли спроектировать трансформатор, который не нуждался бы в механическом инструменте для регулировки его напряжения, мы могли бы устранить значительные расходы на распределительную инфраструктуру. Естественным решением, конечно же, является применение наиболее подходящей технологии, а именно силовой электроники.
Фактически, ряд инженеров изучают идею «гибридного трансформатора», который добавляет силовую электронику для помощи в управлении напряжением.Но новые высоковольтные полупроводниковые устройства необходимы, если мы хотим создать более мощные электронные распределительные трансформаторы. И до недавнего времени не было переключателей со всеми нужными свойствами.
Например, тиристорыможно использовать для создания преобразователей, которые можно подключать к высоковольтным линиям. Но конвертеры занимали бы много места. Это потому, что тиристоры не предназначены для работы на высоких частотах. Чем ниже частота, тем больше должны быть пассивные элементы системы, в частности катушки индуктивности и конденсаторы.Вы можете думать об этих компонентах как об устройствах для хранения заряда; чем ниже частота, тем больше времени им нужно, чтобы выдерживать протекающие через них заряды, а это значит, что они должны быть довольно большими.
Рабочий переключатель силовой электроники, кремниевый биполярный транзистор с изолированным затвором (IGBT) лучше подходит. Эти устройства использовались для создания SST для железнодорожных приложений в Европе. И они конечно быстрее. Но самые строгие коммерческие устройства могут выдерживать напряжение до 6.5 киловольт. Хотя это напряжение пробоя идеально подходит для ряда энергетических приложений, его недостаточно для обработки электричества, протекающего через распределительные трансформаторы; в Соединенных Штатах типичное напряжение в нижней части спектра составляет 7,2 кВ.
Конечно, если бы несколько из этих IGBT были соединены последовательно, их можно было бы использовать для создания SST, способного выдерживать напряжение. Но небольшие производственные изменения означают, что каждый IGBT будет переключаться при немного другом напряжении, а это означает, что некоторые транзисторы переключаются раньше, чем другие, неся большую нагрузку.Конденсаторы могут помочь уравновесить напряжения, но в результате они будут громоздкими, неэффективными, менее надежными и более дорогими.
К счастью, кремний — не единственный вариант. За последние 10 лет были достигнуты большие успехи в разработке переключателей на основе сложных полупроводников, в частности карбида кремния. Карбид кремния обладает рядом привлекательных свойств, которые проистекают из его большой запрещенной зоны — энергетического барьера, который необходимо преодолеть, чтобы переключиться с изолятора на проводник. Ширина запрещенной зоны карбида кремния равна 3.26 электрон-вольт до 1,1 эВ кремния, что означает, что материал может подвергаться воздействию значительно более высоких электрических полей и температур, чем кремний, без разрушения. А поскольку этот составной полупроводник может выдерживать гораздо более высокие напряжения, силовые транзисторы, построенные из него, можно сделать более компактными, что, в свою очередь, позволяет им переключаться намного быстрее, чем их аналоги на основе кремния. Более высокая скорость переключения также снижает потери энергии, поэтому транзисторы из карбида кремния могут пропускать больший ток при заданном тепловом балансе.
Уменьшение: на этих полках в Системном центре FREEDM находится часть TIPS, трехфазного твердотельного трансформатора. Обычный трансформаторный компонент TIPS (серые прямоугольники внизу) может быть небольшим благодаря силовой электронике, преобразующей электричество в высокочастотный. Фото: Субхашиш Бхаттачарья / NCSU
Вдохновленные разработками в устройствах из карбида кремния и соответствующими исследованиями, финансируемыми Исследовательским институтом электроэнергетики в США, наша группа из Университета штата Северная Каролина в 2007 году подала заявку на получение гранта от Университета штата Северная Каролина.S. Национальный научный фонд. Мы использовали грант для создания Центра систем доставки и управления будущей возобновляемой электрической энергией (FREEDM) с целью развития технологий, которые потребуются нам для модернизации электрической сети, чтобы сделать ее более безопасной, надежной и экологически устойчивой.
SSTбыли большим приоритетом для центра, и мы стремились решить проблему как однофазных, так и трехфазных распределительных трансформаторов. Чтобы понять разницу, вот небольшая предыстория. Энергия, вытекающая из подстанций, обычно передается по трем проводам, по каждому из которых протекает переменный ток, сдвинутый по фазе на 120 градусов по отношению к двум другим.Эти линии могут быть разделены и пропущены по отдельности (вместе с нейтральной линией) через однофазный трансформатор, например, для подачи электроэнергии низкого напряжения в жилые кварталы. Или линии могут быть проведены вместе в трехфазном фидере в места с повышенным энергопотреблением, такие как центры обработки данных, фабрики, коммерческие здания и торговые комплексы.
В FREEDM мы начали с работы над SST, предназначенными для обслуживания однофазных сетей с низким напряжением. Трансформаторы в некоторых отношениях похожи на импульсные блоки питания, которые теперь повсеместно используются в качестве источников питания для портативных компьютеров и других устройств.
Наш подход заключался в создании SST из трех модулей. Первый, называемый входным преобразователем, принимает входящий переменный ток, скажем, 7,2 кВ, и преобразует его в постоянный ток (из-за особенностей нашей конструкции этот постоянный ток имеет несколько более высокое напряжение). Преобразование переменного тока в постоянное выполняется с помощью набора силовых транзисторов. В первом воплощении это было сделано с помощью кремниевых IGBT, а в нашем втором SST мы сделали это с помощью одного из первых переключателей из карбида кремния: полевого транзистора из карбида кремния, металл-оксид-полупроводник, или MOSFET.
Для преобразования входящего электричества, которое колеблется с частотой 60 Гц в США, в постоянный ток требуются два дополнительных набора транзисторов. Один набор работает, когда поступающее электричество переменного тока имеет положительное напряжение, а другой набор работает, когда он имеет отрицательное напряжение. Благодаря способу подключения транзисторов, независимо от напряжения поступающего электричества, заряд накапливается на конденсаторе, который постоянно разряжается, создавая постоянный ток. Мы используем транзисторы для выполнения этого процесса выпрямления вместо традиционных диодов, потому что мы можем запускать их на частоте, во много раз превышающей входную частоту.Это позволяет нам очень точно нарезать синусоидальный входящий ток, чтобы не вводить шум и нежелательные гармоники в восходящем направлении. Это приведет к отклонениям от четких синусоидальных волн в напряжении и токе и, следовательно, к непригодной для использования энергии, которая будет потеряна на тепло.
Во втором модуле другой набор транзисторов преобразует поступающий постоянный ток в переменный ток с частотой, измеряемой в килогерцах. Затем этот ток пропускается через обычный, хотя и высокочастотный, трансформатор для преобразования напряжения, скажем, до 800 В.
Почему высокая частота? По сути, размер трансформатора обратно пропорционален частоте напряжения, которое он должен преобразовывать. Чем выше частота, тем меньше трансформатор и, в качестве бонуса, он будет эффективнее. После того, как напряжение снижается, набор устройств с более низким напряжением преобразует этот все еще высокочастотный переменный ток обратно в постоянный ток.
Третий модуль представляет собой инвертор, который использует еще один набор транзисторов для преобразования электроэнергии постоянного тока обратно в переменный ток с частотой сети, после чего его можно безопасно поставлять конечным пользователям.
Первая однофазная SST, созданная нами, была разработана для изучения ограничений кремния; второй позволил нам испытать устройства из карбида кремния. И если есть какие-либо сомнения в преимуществах карбида кремния по сравнению с кремнием, их можно решить, сравнив эти два SST. Нашему кремниевому трансформатору потребовалось три набора кремниевых IGBT, расположенных последовательно, для преобразования входящей электроэнергии 7,2 кВ в стандартное выходное напряжение 120 и 240 В, и он мог работать только на частоте до 3 кГц. На этой частоте обычный трансформатор был меньше, но нам понадобилось их три.Версия из карбида кремния могла выполнять ту же задачу с одним набором транзисторов, и она могла работать на частоте 20 кГц — частота, которая позволила нам использовать трансформатор во втором модуле, который был всего на 20 процентов от размера обычного трансформатора на 60 Гц. . В целом, наш однофазный карбид кремния SST был втрое меньше своего обычного аналога.
Итак, в конце концов, мы просто взяли один большой трансформатор и заменили его меньшим с большим количеством дорогостоящей электроники? Не совсем.Подобно гибридному трансформатору, созданный нами трансформатор может автоматически и быстро адаптироваться к изменениям напряжения в широком диапазоне, устраняя необходимость в механических переключателях ответвлений. Но это также интеллектуальное устройство управления энергией, которое может обрабатывать широкий спектр нагрузок и источников, обеспечивая гораздо лучшую гибкость и отказоустойчивость, чем обычный или гибридный трансформатор.
При трехмодульном подходе батареи и возобновляемые источники энергии могут подключаться непосредственно к одной стороне центрального модуля SST.В результате эти источники энергии могут иметь прямой интерфейс постоянного тока с сетью. Такая компоновка значительно снизит потери энергии, когда солнечные панели, ветряные турбины и т.п. перекачивают энергию обратно в сеть, так как вырабатываемая ими электроэнергия не нуждается в преобразовании в переменный ток, чтобы проходить через близлежащие трансформаторы. .
Наша работа с однофазными SST побудила нас расширить наши усилия по созданию трехфазных SST. Это означало бы создание трансформатора, который мог бы обслуживать все три линии, которые покидают подстанцию или проходят по распределительной фидерной цепи.Обычное входное напряжение составляет 13,8 кВ, которое преобразуется в 480 В для промышленного и коммерческого использования.
Здесь, при таком относительно высоком напряжении, полевые МОП-транзисторы из карбида кремния были не лучшим выбором; они теряют много энергии, когда через них протекает ток, и потери тем больше, чем выше напряжение и температура. К счастью, корпоративный партнер недалеко от университета, Кри, работал над карбидокремниевыми IGBT. Они теряют больше энергии, чем полевые МОП-транзисторы, при переключении, но они могут пропускать больше тока через ту же область и поэтому быть еще более компактными.
В 2010 году Агентство перспективных исследовательских проектов Министерства энергетики США выделило нашей команде 4,2 миллиона долларов США на создание трехфазной SST из этих устройств. Мы назвали этот проект Бестрансформаторной интеллектуальной подстанцией, или TIPS. Признаюсь, это прозвище несколько странное: TIPS — это не подстанция, и в ней нет трансформатора. Но часть названия «подстанция» возникла потому, что мы хотели подчеркнуть, насколько умной и производительной может быть SST. А «бестрансформаторный» на самом деле относится к идее использования меньшего количества традиционных трансформаторных технологий за счет работы на довольно высокой частоте.
Фото: Кри Преобразование в трех частях: TIPS (Бестрансформаторная интеллектуальная силовая подстанция) была завершена в 2015 году и стала первым трехфазным трансформатором, изготовленным на твердотельных устройствах. Трансформатор состоит из трех модулей и включает в себя небольшие обычные однофазные трансформаторы, работающие на высокой частоте.
При таком большом количестве различных шагов преобразования можно подумать, что SST, такие как TIPS, значительно менее эффективны, чем обычные трансформаторы.Но на самом деле они неплохо справляются. Сегодня трансформаторы имеют КПД более 99 процентов, когда они работают на полную мощность, при этом менее 1 процента электроэнергии теряется на тепло. Но КПД падает до 95 процентов для трансформатора, работающего на 30–50 процентов мощности. Для сравнения, мы ожидаем, что SST, такие как TIPS, будут иметь эффективность 98 процентов, независимо от нагрузки. Более того, плавно регулируя напряжение, SST может снизить зависимость от повышающего тока — крайне неэффективное средство, которое используется сегодня, чтобы гарантировать, что потребителю поступает достаточно энергии, даже если напряжение в линии падает.
Наша команда не единственная , которая построила SST. Но с помощью TIPS мы смогли продемонстрировать, что могут предложить карбидокремниевые IGBT: новый класс трехфазных трансформаторов, одновременно компактных и сверхмощных.
Есть все еще препятствия на пути к широкому распространению. Один из них — способность противостоять экстремальным условиям. Традиционные трансформаторы могут выдерживать удары молнии и скачки напряжения, безотказно перегреваясь. Но силовая электроника гораздо менее снисходительна; Транзисторы маленькие и имеют небольшую тепловую инерцию, что означает, что они нагреваются почти мгновенно.Зависящие от напряжения резисторы и ограничители перенапряжения, установленные на стороне высокого напряжения SST, могут помочь компенсировать это ограничение.
Еще одно препятствие — это стоимость. IGBT-транзисторы из карбида кремния, которые мы использовали для изготовления TIPS, были экспериментальными устройствами, коммерчески недоступными. Такие компании, как Cree, General Electric, Infineon, Mitsubishi и Rohm, продолжают разрабатывать эти устройства. И с тех пор Cree продолжила строить версии на 20 и 24 кВ. Эти более высокие значения напряжения могут привести к SST, для которых потребуется значительно меньше устройств, что приведет к экономии средств и места.Но IGBT из карбида кремния все еще находятся на ранней стадии разработки, и их коммерциализация будет частично зависеть от практических аспектов, таких как способность производить их с меньшим количеством дефектов. Может пройти несколько лет, прежде чем карбидокремниевые IGBT станут зрелыми и, следовательно, достаточно дешевыми, чтобы производить SST, которые можно было бы предлагать по конкурентоспособной цене.
Тем временем наша команда получила значительную поддержку в исследовании создания SST с использованием более совершенных полевых МОП-транзисторов из карбида кремния 10 кВ.Эти транзисторы должны быть соединены последовательно, чтобы выдерживать трехфазные распределительные напряжения, и они не будут такими же эффективными, как IGBT. Но они по-прежнему могут предложить путь к созданию трансформаторов меньшего размера, чем у нас сегодня, со всеми продемонстрированными нами интеллектуальными возможностями и функциональностью SST.
Возможно, вы заметили, что если вы отключите внешние модули TIPS, вы получите преобразователь постоянного тока в постоянный. Если бы у нас были такие преобразователи на заре электричества, мы вполне могли бы видеть, как схема распределения постоянного тока Томаса Эдисона до сих пор конкурирует с подходом Николы Теслы к переменному току.В последние несколько лет это давнее соперничество снова вышло на первый план. Передача постоянного тока обещает меньшие потери на большие расстояния. И инженеры рассматривают микросети постоянного тока, чтобы более эффективно питать наши устройства, зависящие от постоянного тока, и повседневные гаджеты. Теперь мы можем делать преобразователи постоянного тока из кремниевой силовой электроники, достаточно эффективные для использования в таких микросетях; Версии из карбида кремния могут иметь более высокий КПД и более широкое применение.
Некоторые из этих идей являются новыми. Но они приобретают новую актуальность, поскольку мы стремимся максимально использовать наши энергетические ресурсы.SST предлагают способ кардинально изменить то, как власть доходит до нас. Изменения, которые они произведут, не будут такими гламурными и заметными, как огромные скачки в электронике, которые за последние 50 лет произвели революцию в нашей повседневной жизни.