Название профессии/специальности | Код специальности | Срок обучения | План | Количество поданных заявлений на 05 октября 2020 года |
Программы подготовки специалистов среднего звена | ||||
| Информационные системы и программирование | 09.02.07 | 3 года 10 месяцев | 25 | Группа набрана |
13.02.11 | 3 года 10 месяцев | 25 | Группа набрана | |
| Технология машиностроения | 15.02.08 | 3 года 10 месяцев | 25 | Группа набрана |
| Аддитивные технологии | 15.02.09 | 3 года 10 месяцев | 25 | Группа набрана |
| Технология продукции общественного питания | 19. | 3 года 10 месяцев | 25 | Группа набрана |
| Конструирование, моделирование и технология швейных изделий (модуль «Цифровой модельер») | 29.02.04 | 3 года 10 месяцев | 20 | Группа набрана |
| Операционная деятельность в логистике | 38.02.03 | 2 года 10 месяцев | 40 | Группа набрана |
| Поварское и кондитерское дело | 43.02.15 | 3 года 10 месяцев | 20 | Группа набрана |
Программы подготовки квалифицированных рабочих, служащих | ||||
| Наладчик аппаратного и программного обеспечения | 09.01.01 | 2 года 10 месяцев | 20 | Группа набрана |
Программы профессионального обучения | ||||
| Швея (адаптивная программа для лиц с ОВЗ) | 19601 | 10 месяцев | 5 | 4 |
| Пекарь (адаптивная программа для лиц с ОВЗ) | 16472 | 10 месяцев | 5 | Группа набрана |
Программы подготовки специалистов среднего звена | ||||
| Информационные системы и программирование | 09. 02.07 02.07 | 3 года 10 месяцев | 6 | Группа набрана |
13.02.11 | 3 года 10 месяцев | 5 | Группа набрана | |
Технология машиностроения | 15.02.08 | 3 года 4 месяца | 5 | Группа набрана |
| Аддитивные технологии | 15.02.09 | 3 года 10 месяцев | 5 | Группа набрана |
Технология продукции общественного питания | 19.02.10 | 3 года 4 месяца | 5 | Группа набрана |
| Конструирование, моделирование и технология швейных изделий (модуль «Цифровой модельер») | 29.02.04 | 3 года 10 месяцев | 10 | Группа набрана |
33.02.01 | 3 года 10 месяцев | 25 | Группа набрана | |
| Операционная деятельность в логистике | 38. | 2 года 10 месяцев | 20 | Группа набрана |
| Поварское и кондитерское дело | 43.02.15 | 3 года 10 месяцев | 10 | Группа набрана |
Программы подготовки квалифицированных рабочих, служащих | ||||
| Наладчик аппаратного и программного обеспечения | 09.01.01 | 2 года 10 месяцев | 5 | Группа набрана |
Программы подготовки специалистов среднего звена | ||||
| Технология машиностроения | 15.02.08 | 5 лет 4 месяца | 20 | Группа набрана |
Технология продукции общественного питания | 19. | 5 лет 4 месяца | 20 | 14 |
Программы подготовки специалистов среднего звена | ||||
| Технология машиностроения | 15.02.08 | 2 года 10 месяцев | 20 | 12 |
| Информационные системы и программирование | 09.02.07 | 2 года 10 месяцев | 20 | 17 |
Программы подготовки специалистов среднего звена | ||||
| Техническая эксплуатация и обслуживание электрического и электромеханического оборудования (по отраслям) | 13.02.11 | 3 года 4 месяца | 25 | 21 |
Техническое обслуживание и ремонт автомобильного транспорта | 23. | 3 года 4 месяца | 25 | 21 |
Монтаж, техническое обслуживание и ремонт промышленного оборудования (по отраслям) | 15.02.12 | 3 года 4 месяца | 25 | Группа набрана |
Программы подготовки специалистов среднего звена | ||||
Фармация | 33.02.01 | 3 года 4 месяца | 25 | 20 |
Программы подготовки специалистов среднего звена | ||||
Фармация | 33.02.01 | 2 года 4 месяца | 25 | 23 |
 02.10
02.10 02.03
02.03 02.10
02.10 02.03
02.03Поиск и устранение неисправностей, связанных с защищенным разделом GPT
Иногда после подключения внутреннего или внешнего диска служба управления дисками Windows сообщает, что на нём есть раздел, защищенный GPT (то есть накопитель нельзя ни отформатировать, ни заново разбить на разделы).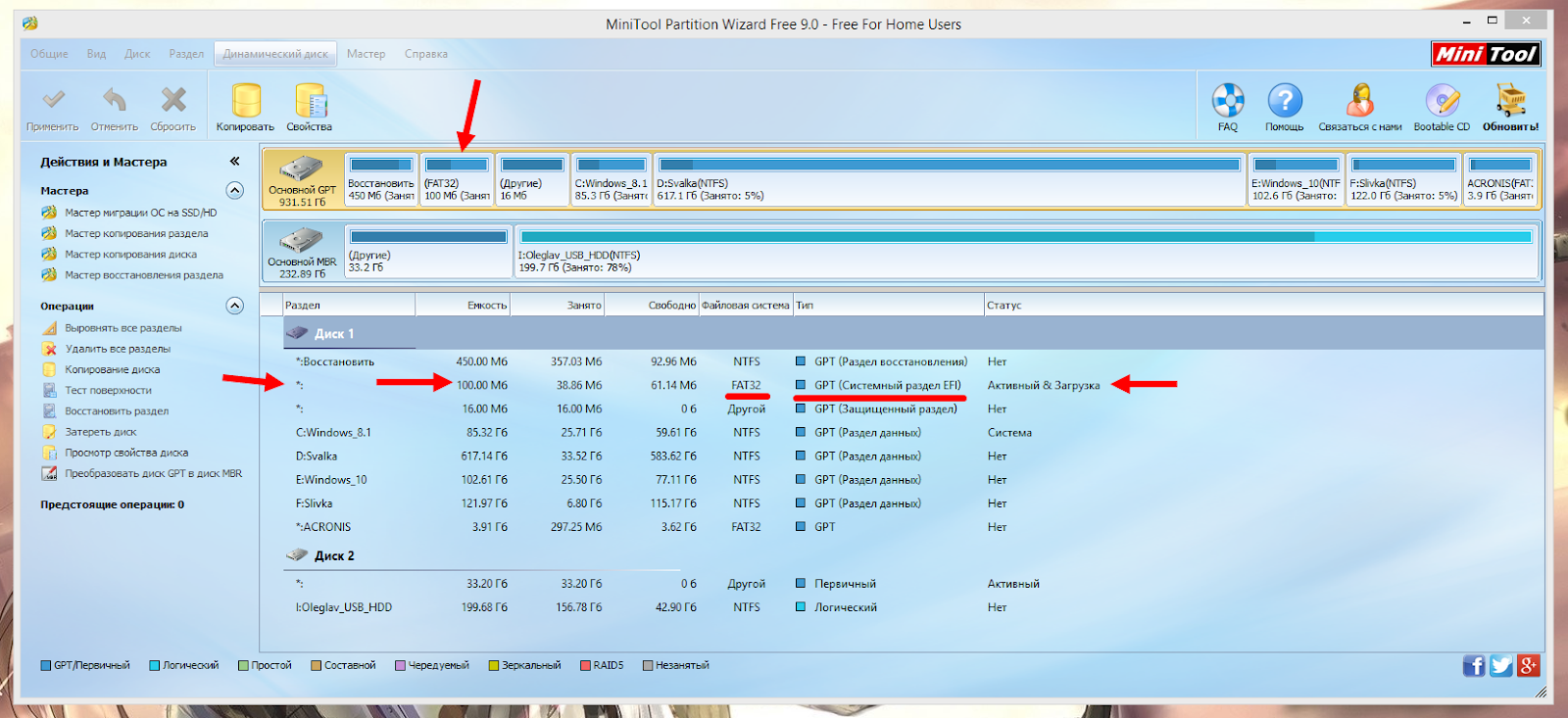 В данной статье описано, как решить эту проблему.
В данной статье описано, как решить эту проблему.
Что такое GPT-накопитель?
Таблица разделов GUID Partition Table (GPT) — это стандарт формата размещения таблиц разделов на жестких дисках, который является частью расширяемого микропрограммного интерфейса (Extensible Firmware Interface, EFI), пришедшего на смену BIOS. GPT обеспечивает большую гибкость по сравнению с главной загрузочной записью (Master Boot Record, MBR), которая традиционно использовалась для разбиения дисков на разделы в ПК.
Раздел — это часть памяти физического или логического накопителя, состоящая из смежных блоков и функционирующая как отдельный диск. Микропрограммы и операционные системы (ОС) работают именно с разделами. На включенном компьютере доступом к разделу сначала управляет системная микропрограмма, а после загрузки ОС эта функция передается операционной системе.
Таблицу разделов GUID Partition Table (GPT) поддерживают Microsoft Windows XP x64 Edition, 64-разрядная версия Windows Server 2003, все версии Windows Server 2003 с пакетом обновления 1 (SP1), Windows Vista, Windows 7 и более поздние версии ОС Windows.
Стандарт GPT Partition был разработан, чтобы обойти проблему ограничения размера раздела в MBR, которое составляет 2 ТБ. При использовании GPT размер раздела может быть больше.
Примечание. Подробную информацию о разделах, защищенных GPT, читайте в справочном центре Microsoft на странице
https://docs.microsoft.com/en-us/windows-hardware/manufacture/desktop/windows-and-gpt-faq
Начиная с версии 10.4.6, операционная система macOS (прежнее название — Mac OS X) также поддерживает таблицу разделов GUID Partition Table (GPT). Все компьютеры Mac с процессорами Intel требуют наличия раздела GPT на загрузочном томе (независимо от того, какой используется диск — внешний или внутренний).
Иногда при подключении внутреннего или внешнего жесткого диска к компьютеру с 32-разрядной ОС Windows XP (или более поздней версией ОС Windows) оказывается, что накопитель недоступен, а служба управления дисками сообщает о наличии раздела, защищенного GPT. Такой накопитель нельзя отформатировать или заново разбить на разделы, поскольку он уже отформатирован на компьютере Windows или Macintosh с созданием раздела GPT.
Эту проблему нельзя решить обычными средствами службы управления дисками, поэтому в таких случаях следует использовать утилиту командной строки Windows
После выполнения инструкций с диска будут удалены все данные. При этом удаляется не только раздел, но и подпись диска. Перед выполнением этих действий настоятельно рекомендуется создать резервные копии всех важных данных.
Обязательно запустите службу управления дисками и запишите номер диска с разделом, защищенным GPT: эта информация вам понадобится позже.
- Определите номер диска с разделом, защищенным GPT.
- Щелкните правой кнопкой мыши по значку «(My) Computer» ((Мой) компьютер).
- Нажмите Manage (Управление).
- В разделе Storage (Запоминающие устройства) выберите Disk Management (Управление дисками).

- Найдите GPT-диск и запишите его номер (например, «Диск 1»).
- Откройте окно команд. В командной строке введите diskpart и нажмите клавишу Enter. Откроется окно служебной программы diskpart.
- В окне программы diskpart введите list disk и нажмите клавишу Enter. Появится текстовый перечень дисков, и вы вернетесь в командную строку diskpart.
- В командной строке diskpart введите select disk номер_диска (например, если защищенный GPT раздел находится на накопителе «Диск 2», введите select disk 2). Затем нажмите клавишу Enter. Появится сообщение о том, что диск выбран, и вы вернетесь в командную строку diskpart.
- В командной строке diskpart введите clean и нажмите клавишу Enter
- В командной строке diskpart введите exit и нажмите клавишу Enter.
 Чтобы закрыть окно команд, введите exit еще раз. После этого внутренний или внешний накопитель можно будет заново инициализировать, разбить на разделы и отформатировать.
Чтобы закрыть окно команд, введите exit еще раз. После этого внутренний или внешний накопитель можно будет заново инициализировать, разбить на разделы и отформатировать. - Чтобы инициализировать накопитель, запустите службу управления дисками, после чего:
- воспользуйтесь мастером инициализации и преобразования дисков
-ИЛИ-
- закройте мастер, щелкните по нужному накопителю правой кнопкой мыши и выберите в меню пункт Инициализировать диск.
- воспользуйтесь мастером инициализации и преобразования дисков
- После инициализации разбейте накопитель на разделы и отформатируйте с помощью службы управления дисками.
ССЫЛКА НА СТОРОННИХ ПРОИЗВОДИТЕЛЕЙ И ВЕБ-САЙТЫ СТОРОННИХ ПРОИЗВОДИТЕЛЕЙ. Ссылки на сторонних производителей и продукты сторонних производителей приводятся исключительно в информационных целях и не подразумевают одобрение или явные/подразумеваемые рекомендации какой-либо из указанных компаний. Компания Seagate не предоставляет гарантий, явных или подразумеваемых, в отношении производительности или надежности этих компаний и продуктов. Все указанные компании являются независимыми и не находятся под управлением компании Seagate. Поэтому компания Seagate не несет никакой ответственности и не берет на себя какие-либо обязательства в отношении действий или продуктов указанных компаний. Решение о начале сотрудничества с любой из компаний должно приниматься на основании самостоятельно произведенной независимой оценки. Чтобы получить характеристики продуктов и сведения о гарантии, обращайтесь напрямую к соответствующему поставщику. В документах приведены ссылки на сайты сторонних производителей, которые не контролируются компанией Seagate. Такие ссылки размещены исключительно для удобства посетителей веб-сайта, которые могут воспользоваться ими на свой собственный риск. Компания Seagate не предоставляет никаких обязательств в отношении содержимого какого-либо из данных веб-сайтов. Компания Seagate не берет на себя никакой ответственности за содержимое этих веб-сайтов и деталей их использования.
Все указанные компании являются независимыми и не находятся под управлением компании Seagate. Поэтому компания Seagate не несет никакой ответственности и не берет на себя какие-либо обязательства в отношении действий или продуктов указанных компаний. Решение о начале сотрудничества с любой из компаний должно приниматься на основании самостоятельно произведенной независимой оценки. Чтобы получить характеристики продуктов и сведения о гарантии, обращайтесь напрямую к соответствующему поставщику. В документах приведены ссылки на сайты сторонних производителей, которые не контролируются компанией Seagate. Такие ссылки размещены исключительно для удобства посетителей веб-сайта, которые могут воспользоваться ими на свой собственный риск. Компания Seagate не предоставляет никаких обязательств в отношении содержимого какого-либо из данных веб-сайтов. Компания Seagate не берет на себя никакой ответственности за содержимое этих веб-сайтов и деталей их использования.
| Истпытание переменным током | |
|---|---|
| Испытательное напряжение | 0,05 кВ…5 кВ; частота 50/60 Гц (в зав. от сети питания) от сети питания) |
| Погрешность установки | ± (1 % + 5 ед. мл. разряда) |
| Разрешение | 2 В; 1 мкА |
| Диапазон установки тока | 0,001 мА…40 мА |
| Испытание постоянным током | |
| Испытательное напряжение | 0,05 кВ…6 кВ |
| Погрешность установки | ± (1 % + 5 ед. мл. разряда) |
| Диапазон установки тока | 0,001 мА…10 мА |
| Разрешение | 1 мкА |
| Измерение сопротивления изоляции | |
| Тестовое напряжение | 50 / 100 / 250 / 500 / 1000 В, постоянное |
| Диапазон измерений | 1 МОм…9999 МОм |
| Погрешность измерения | ± (1 % + 5 ед. мл. разряда) |
| Измерение сопротивления низкоомных цепей | |
| Тестовое напряжение | 6 Вмакс, частота 50/60 Гц |
| Тестовый ток | 3 А…30 А |
| Диапазон измерений | 0,1…650 мОм |
| Разрешение | 0,1 мОм |
| Погрешность измерений | ± (2 % + 2 ед. мл. разряда) мл. разряда) |
| Детектор токов утечки | |
| Диапазон установки | 0,3…100 мА |
| Общие данные | |
| Время испытания | 1…999 с (таймер) или непрерывно |
| Дисплей | ЖК-индикатор, графический (240х64) |
| Память | 100 ячеек (запись/ вызов профилей теста с букв-цифр. обозначением шагов) |
| Напряжение питания | 115 / 230 В, 50 / 60 Гц |
| Интерфейс | RS-232, USB |
| Габаритные размеры | 330 х 149 х 446 мм |
GPT — новые грани фантастики
История развития технологий обработки естественного языка, устройство революционного генератора текстов и разбор его возможностей на примере Dungeon AIGPT мне уже давно кажется очень интересной темой, потому что она реально взорвала интернет, все о ней говорят, но в то же время никто не понимает, как это работает. Но после этого поста Дениса о Dungeon AI я окончательно решился написать об этом пост, потому что сам тоже скачал себе эту штуку на телефон и залип в ней нанесколько часов, пробуя разные варианты геймплея. Игра хоть и обещает вам безграничные возможности геймплея, но на самом деле в процессе игры я столкнулся с немалым количеством достаточно необычных ограничений, которые заставляют в целом задуматься о природе ИИ и GPT в частности.
Но после этого поста Дениса о Dungeon AI я окончательно решился написать об этом пост, потому что сам тоже скачал себе эту штуку на телефон и залип в ней нанесколько часов, пробуя разные варианты геймплея. Игра хоть и обещает вам безграничные возможности геймплея, но на самом деле в процессе игры я столкнулся с немалым количеством достаточно необычных ограничений, которые заставляют в целом задуматься о природе ИИ и GPT в частности.
Введение
AI Dungeon — это генератор текстов, на который пытаются навесить дополнительные функции, тем самым превратив это в игру. Суть в том, что в её основе лежит GPT-3 — нейросетевая модель, разработанная OpenAI специально для целей генерации текста, неотличимого от естественной человеческой речи. OpenAI основана несколькими инвесторами (в том числе, Илоном Маском) всего лишь в 2015-ом году, но с тех пор ежегодно совершает в сфере искусственного интеллекта одну революцию за другой.
OpenAI основана несколькими инвесторами (в том числе, Илоном Маском) всего лишь в 2015-ом году, но с тех пор ежегодно совершает в сфере искусственного интеллекта одну революцию за другой.
Архитектура GPT (Generative Pre-trained Transformer — заранее обученный генераторный трансформер) без дополнительного дообучения способна генерировать любой текст, схожий с тем, на котором она натренирована. Натренируете её на прозе — она будет писать прозу. Натренируете на википедии — будет писать энциклопедические заметки. И музыку она может генерировать, и компьютерный код, короче говоря ей можно скормить всё что угодно, что является последовательностью сигналов.
Вот вам рикролл будущего
Некоторые умельцы решили этим воспользоваться — и накормили нейросеть кучей фантастических книг, чтобы затем выдать это за генератор игровых историй.
Функции у Dungeon AI простые: вы вписываете какой-либо текст, являющийся завязкой вашей личной истории — а программа продолжает её писать за вас, генерируя новые сюжетные повороты, персонажей и их реплики. Вы можете в том числе и менять историю по своему усмотрению через слова, действия или события. Вы ничем не ограничены, кроме правил английского языка (хотя и к ним можно относится весьма пренебрежительно, программа вас поймёт или хотя бы попытается). Опять же, у Дениса есть вполне себе неплохой коротенький обзор на неё, можете прочитать. Я же бы хотел взглянуть на технологию, лежащую в основе игры, и на примере этой же самой игры оценить её фактические возможности.
Технологии прошлого
Раньше я активно увлекался нейросетями и технологиями генерации естественной речи, поэтому немного в этом разбираюсь.![]()
И могу сказать, что американцам в этом плане очень повезло, и то, что прорыв в технологиях произошёл именно у них, а не где-либо ещё — это вполне себе логичное и закономерное развитие событий.
Я не буду особо распространяться о том, что Америка — это огромный пылесос, который засасывает в себя всех умных людей на свете, это вы и так все знаете. Но помимо этого, американцы говорят на английском языке, который является международным стандартом для любых межнациональных коммуникаций. Если ты хочешь выйти на мировую аудиторию, ты обязан учить английский и все свои труды переводить прежде всего на него. Неудивительно, что мировое сообщество обладает наибольшей текстовой базой именно на английском языке, а не на любом другом. А текстовые данные для исследователей — это манна небесная, без них у вас не выйдет сделать никакого генератора текстов, потому что модель будет не на чем обучать. Когда я пытался этим заниматься, я в первую очередь встал перед этой проблемой — все распарсенные текстовые данные, которые можно было бы использовать для обучения без предварительной их обработки, есть только на английском языке.
Когда я пытался этим заниматься, я в первую очередь встал перед этой проблемой — все распарсенные текстовые данные, которые можно было бы использовать для обучения без предварительной их обработки, есть только на английском языке.
Ну и ещё одна причина — это различие российской и американской ментальности. Наши учёные предпочитают долго теоретизировать, прежде чем приступить к разработкам, и выбирают только надёжные инструменты. В свою же очередь, американцы сначала берут в руки молоток, долбят им по чему-нибудь, а потом смотрят на результат. GPT стал продуктом именно такого метода проб и ошибок, мало кто заранее мог предугадать, что именно такая методика генерации текста выдаст такие ошеломляющие результаты. Многие учёные не верили и до сих пор не верят в возможности нейросетей стать полноценным сильным ИИ. Конечно, я не собираюсь отрицать интеллектуальное превосходство членов OpenAI, но без таких безрассудных бюджетов, мощностей и полной свободы действий я не думаю, что они бы достигли таких успехов за такие короткие сроки.
Ну, а теперь о самой технологии GPT. Я пытался понять, что это и как оно работает, но я скорее теоретик и нейросетями почти не пользуюсь, поэтому в чём-то я могу ошибаться. Тем не менее, постараюсь рассказать, как всё было, буду в основном пересказывать английскую википедию.
Как это ни странно, но технологии автоматического анализа речи начали зарождаться ещё в далёких 50-х с разработки автоматчиеских переводчиков. Я думаю, вы и сами можете представить, какие в 50-ых были успехи — компьютер мог распознавать и переводить только вполне конкретный набор слов и фраз, а алгоритмы обработки были основаны на конечных автоматах (считайте, заданный вручую просто набор правил). Механизм не менялся ещё долго, менялись лишь степень вложенных в программу усилий: в некоторых программах могли содержаться сотни и тысячи записанных вручную правил.
В далёком 1966-ом году это симулятор психотерапевта, ELIZA, сильно удивила обывателей своим высоким уровнем поддержания диалога, хотя на самом деле просто триггерилась на определённые слова в предложении и повторяла их
Но как учёные не старались, человеческий язык — вещь очень большая, непостоянная, плохо поддающаяся правилам в виду кучи исключений и особенных традиций, так что прогресс в этих технологиях можно сказать остановился, а используют их только при необходимости. В 80-ых годах на смену конечным автоматам пришёл статистический анализ — это когда мы в автоматическом режиме изучаем язык на основе чужих текстов и статистики положения слов относительно друг друга. У него результаты тоже были не шибко лучше, но зато программа не зависела от выбранного языка, набора текстов и программистов её пишущих и могла обучаться самостоятельно, что уже было намного больше похоже на человеческую деятельность.
В середине 00-ых нейросети получили вторую жизнь. О том, чтобы попытаться реализовать структуру мозга в программе начали задумываться ещё в 40-ые года, и уже тогда за нейронными сетями видели большое будущее, но где-нибудь лет через 100, потому что мощностей на компьютерах того времени не хватало, чтобы обучить даже простейший перцептрон. Но всплеск мощностей снял эту проблему — и к ним вернулись снова.
Я надеюсь, вы знакомы с механизмом работы нейросетей: у нас есть куча нейронов, выполняющих простейшие математические операции, у них есть вход, на который нужно подавать данные, и выход, на котором будет результат обработки данных. В принципе, можете воспринимать это как некую формулу, как чёрный ящик, который преобразует одни цифры в другие. Сама нейросеть работает достаточно шустро, самой большой проблемой для программиста является её обучить, то есть найти такие параметры (а параметров уже тогда было сотни и тысячи, а теперь вообще миллиарды), при которых она выдаёт корректные результаты чаще всего. Никакого адекватного и точного алгоритма для этого не существует, обучение происходит через модифицированный перебор.
Сама нейросеть работает достаточно шустро, самой большой проблемой для программиста является её обучить, то есть найти такие параметры (а параметров уже тогда было сотни и тысячи, а теперь вообще миллиарды), при которых она выдаёт корректные результаты чаще всего. Никакого адекватного и точного алгоритма для этого не существует, обучение происходит через модифицированный перебор.
Простейшее описание нейросети
Проблема применения нейронных сетей для обработки естественного языка лежит в том, что для каждой задачи структуру нейросетей нужно выбирать заранее. Вы сами задаёте, сколько в ней будет слотов входа, сколько выхода, сколько слоёв. Поэтому, непонятно, как подавать на неё потоковые данные неопределённой длины, например аудиосигнал или текст. Ну правда, мы под Войну и Мир будем делать нейросеть с несколькими миллионами входов? Это невозможно. Поэтому мир озаботился задачей создания архитектуры нейросети, которая может принимать потоковые данные.
Ну правда, мы под Войну и Мир будем делать нейросеть с несколькими миллионами входов? Это невозможно. Поэтому мир озаботился задачей создания архитектуры нейросети, которая может принимать потоковые данные.
Такой архитектурой оказались RNN — рекуррентные нейронные сети. В них на вход подаётся не только сами входные данные, но ещё и данные, характеризующие предыдущий шаг вычислений (это могут быть как входящие данные с прошлого шага, так и преобразованные с выходного, так и само состояние каждого нейрона по отдельности) — поэтому и «реккурентные», то есть основанные на рекурсии. Созданную ещё в 1986-ом, на эту архитектуру долго возлагали надежды и иногда (впрочем, редко) она даже выдавала какие-то неплохие результаты. Особенно много надежд было на LSTM (изобретённую в 1997-ом), конкретную реализацию RNN, которая хранит свои предыдущие состояния (с некоторой поправкой: каждый прошлый шаг делится на некоторое число и складывается с последующим, таким образом прошлые шаги постепенно, но не сразу, забываются).
Как работают RNN: на этапе 0 на вход нейросети А мы подаём данные X0, получаем результат H0, затем на следующем этапе вычислений 1 мы подаём на вход нейросети А не только Х1, но и состояние A0
Но скоро до программистов дошло, что задачам, связанным с обработкой потоковой информации, не хватает какой-то косвенной информации, для максимально полного анализа нужно предоставлять нейросети все данные о контексте целиком. Желательно, в более широкой и структурированной форме, чем обычная передача состояния нейросети, которая справляется только с короткими последовательностями, но не с длинными в несколько десятков или сотен компонентов.
Решение было такое: а давайте попробуем объединить весь текст в какой-то цельный набор данных, который мы сможем засунуть в нейросеть сразу и без изменений. Так придумали векторное представление слов. Суть в чём: мы попробуем свести весь словарный запас людей к некоторому ограниченному набору характеристик (обычно это несколько сотен характеристик, обычно 300 или 400). Например названия цветов в одну категорию, термины из космологии в другую, кулинарию в третью. Первые наработки в этой теме существовали ещё в 60-ых, но только после 2010-го, с введением автоматической группировки, по принципу частоты встречаемости слов рядом друг с другом, технология вошла в массы. Каждое слово численно соотносилось с каждой из характеристик, таким образом мы могли получить численный вектор (то есть набор чисел) заранее заданной величины (чем больше отдельное число в векторе, тем больше слово относится к заданной характеристике).
Так придумали векторное представление слов. Суть в чём: мы попробуем свести весь словарный запас людей к некоторому ограниченному набору характеристик (обычно это несколько сотен характеристик, обычно 300 или 400). Например названия цветов в одну категорию, термины из космологии в другую, кулинарию в третью. Первые наработки в этой теме существовали ещё в 60-ых, но только после 2010-го, с введением автоматической группировки, по принципу частоты встречаемости слов рядом друг с другом, технология вошла в массы. Каждое слово численно соотносилось с каждой из характеристик, таким образом мы могли получить численный вектор (то есть набор чисел) заранее заданной величины (чем больше отдельное число в векторе, тем больше слово относится к заданной характеристике).
Тут у нас три характеристики, и каждое слово относится к одной из двух: небесные тела, имеющие крылья и имеющие двигатель. А вот самолёт относится сразу ко всем характеристикам
А вот самолёт относится сразу ко всем характеристикам
Уже тогда нейросети начали примерно понимать устройство языка, так очень широко разошлось открытие учёных по поводу ассоциативности подобных связей: если мы представим слова «король», «мужчина» и «женщина» как векторы, то мы могли получить занятное уравнение: «король» — «мужчина» + «женщина» = «королева». То есть, нейросеть смогла корректно отделить концепт «мужчины» от должности, а потом к этой же должности добавить «женщину» — и получить название этой же должности в женском роде. Не знаю, впечатляет ли это вас, но для научного сообщества это было приятным шоком.
Другим изобретением, уже сравнительно недавним (2014-ый год, за авторством Google), является генерирование последовательностей. Идея в том, что вместо того, чтобы скармливать нейросети слова по отдельности, мы можем объединить их в общий численный вектор, который уже будет обработан нейросетью целиком. Возможно и обратное: научить нейросеть генерировать последовательности слов на основе заданного вектора (это опять же делается через рекуррентные нейросети). Были созданы и специальные нейросетевые модули, осуществляющие эти операции: кодер шифрует последовательность сигналов в вектор, декодер расшифровывает вектор в последовательность сигналов. За счёт этого нейросеть наконец-то научилась обрабатывать не слово за словом, а предложения целиком, и похожую архитектуру используют во многих задачах, например оценка семантики текста, поиск сущностей на изображениях или же перевод текста на другой язык с учётом правил языка.
Возможно и обратное: научить нейросеть генерировать последовательности слов на основе заданного вектора (это опять же делается через рекуррентные нейросети). Были созданы и специальные нейросетевые модули, осуществляющие эти операции: кодер шифрует последовательность сигналов в вектор, декодер расшифровывает вектор в последовательность сигналов. За счёт этого нейросеть наконец-то научилась обрабатывать не слово за словом, а предложения целиком, и похожую архитектуру используют во многих задачах, например оценка семантики текста, поиск сущностей на изображениях или же перевод текста на другой язык с учётом правил языка.
Слова из предложения по порядку подаются в кодер, на их основе составляется вектор, декодер получает вектор и расшифровывает его в последовательность слов, которые сортируются по факту некоторой значимости
Революция
Всё вышеперечисленное хоть и давало некоторый прирост естественности генерируемым текстам, однако прогресс всё равно двигался медленно, нейросети не могли генерировать осмысленный связный текст дальше одного предложения. Что-то было не так в их подходе. Решение витало в воздухе: исследователи понимали, что не любая информация в тексте одинаково важна, между словами нужно ставить приоритеты, связывать их между собой и учитывать их порядок в тексте, как это делают обычные люди при прочтении текстов. Но как конкретно это перенести в математичекую плоскость, ясно не было.
Что-то было не так в их подходе. Решение витало в воздухе: исследователи понимали, что не любая информация в тексте одинаково важна, между словами нужно ставить приоритеты, связывать их между собой и учитывать их порядок в тексте, как это делают обычные люди при прочтении текстов. Но как конкретно это перенести в математичекую плоскость, ясно не было.
В 2017-ом году снова учёные из Google предложили механизм Внимания. Вместо того, чтобы объединять все слова в один большой вектор, в котором полностью стёрта вся информация о структуре предложения, они сделали ещё один нейросетевой модуль, который для каждого слова из текста генерирует свой отдельный вектор, который хранит положение слова в тексте, его относительную значимость и связь с другими словами в предложении. Тут и далее я уже понятия не имею, что происходит, поэтому буду описывать в общих терминах.
Теперь, в нейросеть предлагали подавать на вход декодера не только сами слова, но и векторы их значимости, в зависимости от приоритета, а уже декодер слово за словом генерирует на их основе новый текст. Механизм внимания очень понравился учёным и его решили развивать в дальнейших разработках, а прогресс в плане обработки искусственной речи полетел вверх с неожиданной для всех скоростью.
Механизм внимания очень понравился учёным и его решили развивать в дальнейших разработках, а прогресс в плане обработки искусственной речи полетел вверх с неожиданной для всех скоростью.
Продолжая свои наработки, Google представили новую модель нейросети Transformer. Информация о прошлых состояниях нейросети теперь не подавалась на вход нейросети в оригинальном виде, как это было в случае рекуррентных нейросетей, но зашифровывалась в сами данные: каждое отдельное слово теперь шифровалось в особенную структуру, которая содержала всю информацию о контексте: и положение слова в предложении, и его тематика, и ссылки на другие слова. Нейросети больше не требовалось вычислять последовательности по порядку, шаг за шагом, вместо этого вычисления и обучение можно было распараллелить. Настоящая революция.
Теперь я окончательно перестал понимать, что происходит. Зато посмотрите, сколько здесь модулей! Нейросети уже очень давно перестали быть непосредственно сетью, теперь это совокупности модулей
Зато посмотрите, сколько здесь модулей! Нейросети уже очень давно перестали быть непосредственно сетью, теперь это совокупности модулей
Но и это ещё не всё. Разработчики из OpenAI подхватили инициативу, попытавшись построить из Transformer полноценный генератор текста. Для этого использовали метод обучения без учителя: ей без какой-либо дополнительныой обработки скармливали слова и предложения, а на них нейросеть пыталась предсказать следующий текст. И это неожиданно сработало, да так, что теперь нам придётся разгребать последствия.
Проблема перехода на обучение без учителя вообще стояла очень давно: архитектура нейросетей слабо учитывала контекст и не могла отличить мусор от действительно важного текста. Поэтому крупным корпорациям приходилось нанимать кучу людей, которые размечали текст и сверяли его с определёнными стандартами, чтобы уже потом специальные программисты-обучаторы подавали эти данные ей на вход, строго под контролем. С введением концепта внимания данная проблема исчезла и исследователи открыли для себя новый мир обучения без учителя, когда можно не бояться просто так взять и скормить нейросети огромное количество текстов любых жанров и форматов.
С введением концепта внимания данная проблема исчезла и исследователи открыли для себя новый мир обучения без учителя, когда можно не бояться просто так взять и скормить нейросети огромное количество текстов любых жанров и форматов.
Проблема была ещё не только в том, что нейросеть не могла отличить друг от друга корректно написанный текст и текст с кучей ошибок, и училась у них плохому. Как это было с чат-ботом от Microsoft, нейросеть без какого-либо контроля могла научиться грязной похабной речи и оскорблениям. Transformer лишена этих недостатков: мы можем заранее внести в исходный текст некоторый другой текст, дополняющий и корректирующий контекст (например, добавить фразу «буду вежливым», после чего нейросеть вспомнит все тексты, которые она читала ранее и в которых какие-либо люди называли себя «вежливыми», и начнёт копировать их речь).
GPT-1 вышла в 2018-ом году, вызвав у исследователей осторожный интерес: это было явно что-то новое и интересное, и оно хорошо работало на тестах, но её настоящие возможности были ещё не понятны. GPT-2 вышла в 2019-ом — и уже начала серьёзно пугать разработчиков своими неожиданно хорошими результатами. Рядовые экспериментаторы только начали получать доступ к технологии и осваивать её, даже не успев хорошо разойтись.
GPT-2 вышла в 2019-ом — и уже начала серьёзно пугать разработчиков своими неожиданно хорошими результатами. Рядовые экспериментаторы только начали получать доступ к технологии и осваивать её, даже не успев хорошо разойтись.
А ещё они научились генерировать продолжение картинок — и это тоже весело. Технология вообще не ограничена форматом подаваемых данных
А в 2020-ом выходит GPT-3. Мир уже потихоньку начинает осознавать последствия: люди действительно пугаются, когда читают результаты работы GPT-3 — слишком реалистично они написаны. Нейросеть не только изъясняется корректным английским языком без каких-либо ошибок, но и способна писать тексты любого формата и любой тематики, где в один контекст связаны не только отдельные слова или предложения, но даже абзацы и параграфы. Она может сохранять свою мысль на очень длинной дистанции. И она много знает о нашем мире, просто потому что она это уже прочитала. И она без проблем сможет достать из памяти ответ на любой вопрос, стоит лишь правильно его сформулировать. Модель не нужно глобально переобучать или приспосабливать, достаточно лишь относительно мелкой настройки.
Она может сохранять свою мысль на очень длинной дистанции. И она много знает о нашем мире, просто потому что она это уже прочитала. И она без проблем сможет достать из памяти ответ на любой вопрос, стоит лишь правильно его сформулировать. Модель не нужно глобально переобучать или приспосабливать, достаточно лишь относительно мелкой настройки.
Исследователи из OpenAI настолько испугались своей разработки, что теперь с полной серьёзностью изучают вопрос, публиковать ли их наработки в открытый доступ или нет. А к новой модели доступ открывают только по предварительной записи.
А теперь взглянем на Dungeon AI
Насколько я понимаю, Dungeon AI — некоторая обёртка над API доступа к GPT-3, которая добавляет определённые функции сверху: можно попросить программу сгенерировать текст заново, отмотать генератор вперёд и назад, добавить какую-нибудь информацию в качестве контекста, чтобы она постоянно висела в памяти программы. Больше ничего лишнего — а зачем? Нейросеть сама справляется со всем.
Больше ничего лишнего — а зачем? Нейросеть сама справляется со всем.
Некоторое время я и правда был в восторге от программы. Её возможности казались мне безграничными, потому что на любую мою реплику она давала более-менее корректный ответ. Авторы буквально обещают, что вам можно делать всё что угодно, буквально повернуть историю в любом направлении — и нейросеть вас поддержит.
Но это только на первый взгляд. По факту же это работает в обе стороны: вы никак не ограничены в своих возможностях, но и автор истории, нейросеть, в этих возможностях так же не ограничена. И если вы думаете, что она будет вас развлекать — то вы ошибаетесь, у неё такой цели не стоит. Впрочем, всё по порядку.
Вот, например, одна из историй, которые я сгенерировал вместе с GPT. Я выбрал обычную фентезийную историю и начал играть за волшебника. Моим главным квестом было найти Книгу Сущностей и прочитать её. Вот только когда я пришёл за ней в библиотеку, её прямо перед моим приходом кто-то украл, о чём мне и сообщает девушка-библиотекарша.
Я выбрал обычную фентезийную историю и начал играть за волшебника. Моим главным квестом было найти Книгу Сущностей и прочитать её. Вот только когда я пришёл за ней в библиотеку, её прямо перед моим приходом кто-то украл, о чём мне и сообщает девушка-библиотекарша.
Кто украл книгу — она не знает. Кроме текста, никаких указателей и подсказок нет. Персонажи вокруг вас обладают только мелкими уликами, а делиться ими начинают только после долгих, упорных и правильно сформулированных вопросов.
Что делать дальше? Никто не знает. Я просто вышел на улицу и начал расспрашивать прохожих, видели ли они что-то подозрительное. Один из них действительно видел этого мага, он же и смог мне описать его внешность подробнее, а ещё сообщить, где я могу узнать о нём больше информации — мне нужно было найти работника аптеки в городе рядом. Он же меня туда и проводил пешком, он же и подарил мне книгу о королевестве. Наверное, это был первый и последний хороший человек в моём путешествии.
Он же меня туда и проводил пешком, он же и подарил мне книгу о королевестве. Наверное, это был первый и последний хороший человек в моём путешествии.
Мы добрались до города и я нашёл ту аптеку, но искомого человека там никто не знает и не знал. То есть, моя единственная улика буквально оборвалась в начале истории. Я начал бродить по городу в поисках хоть какой-либо информации, но персонажи оказались малодружелюбными: один затворник послал меня спросить совета у богов (не уточнял, каких), другой священник активно пытался меня завербовать в священники прежде чем я смогу что-то узнать.
На улице меня нашёл какой-то мужчина в фиолетовых одеждах и сказал, что ему нужна помощь: каких-то его соплеменников похитили бандиты. У меня заканчивались деньги — и я решил ему помочь в надежде, что потом он мне заплатит — всё таки человек выглядел солидно. Он вывел меня из города и повёл по каким-то камням в каньоне, пришлось реально полазить, но своей цели мы достигли.
У меня заканчивались деньги — и я решил ему помочь в надежде, что потом он мне заплатит — всё таки человек выглядел солидно. Он вывел меня из города и повёл по каким-то камням в каньоне, пришлось реально полазить, но своей цели мы достигли.
Зато на обратном пути мы встретили огра. Огр в этой вселенный очень большой, сильный и быстро регенерирущий, а потому бой с ним растянулся где-то на пол часа реального времени: заклинания на него срабатывали и ему было больно, но дальше этого ничего не происходило. Зато огр успел дважды беспощадно убить меня, будто я залез со своим мелким левелом не в ту локацию. Приходилось отматывать игру назад и действовать по другому.
После нескольких попыток я всё же убил огра. Мужик в фиолетовых одеждах шустро слинял и я остался вообще без награды. Пришлось отправиться в отель, где я долго торговался за комнату (пришлось делить её с кем-то, на полноценную денег не было).
Пришлось отправиться в отель, где я долго торговался за комнату (пришлось делить её с кем-то, на полноценную денег не было).
На утро меня снова ждал какой-то странный человек — он сказал, что со мной хочет встретиться сам король и оплатить мне за мою победу над огром. Деньги мне были очень нужны, а потому я без раздумий пошёл за ним. Он повёл меня куда-то вон из города в лес, где меня встретили какие-то разодетые в доспехи братки явно с недобрыми намерениями. Они открыли портал, который якобы вёл к замок короля. Я повёлся и попал в какое-то измерение без входа и выхода, где несколько часов бродил, а потом был поглощён зыбучими песками.
Откат назад — и я решил не церемониться с ними и без особых проблем всех их сжёг, собрал с них монеты и поломанные мечи, которые продал за приличные деньги. Предварительно узнав, что их всё же послал король и именно король приказал меня убить (блин, за что?).
Предварительно узнав, что их всё же послал король и именно король приказал меня убить (блин, за что?).
Надо найти гильдию магов, подумал я. И действительно её нашёл. Более того, оказывается, несколько копий Книги Сущностей лежат у них в библиотеке и никого мне искать на самом деле не надо было! Но всё не так просто — сначала надо выучить нужный язык, в чём мне мог помочь глава гильдии. Он казался хорошим старичком: усадил меня на стул, вежливо поинтересовался мной, предложил научить языку. Я согласился — и он начал колдовать неизвестное заклинание «для моего же блага», попутно никак не рассказывая, что конкретно это за заклинание.
Раньше меня уже пытались убить — и я напал на старика, заморозив и разбив ему руку. Брал его за шкирку и угрожал принести мне книгу и прочитать её мне. Он сказал, что книга в музее — и мне нужно туда сходить. Ага, подумал я, засада! Пусть идёт сам, а я подожду здесь. Но вместо него пришла стража и я снова пустился в бой и бега в поисках выхода из гильдии магов.
Брал его за шкирку и угрожал принести мне книгу и прочитать её мне. Он сказал, что книга в музее — и мне нужно туда сходить. Ага, подумал я, засада! Пусть идёт сам, а я подожду здесь. Но вместо него пришла стража и я снова пустился в бой и бега в поисках выхода из гильдии магов.
Честно, хотелось бы закончить и так интересную историю на этом, потому что дальше начинается какая-то полная чушь в стиле логики сна. Сгенерированная история, честно, мне очень понравилась — никогда со мной не происходило таких нетривиальных перепетий и такой наглости, я наглядно чувствовал, что здесь я кто угодно, но точно не протагонист, которому достанутся все женщины и все сокровища.
Но всё это сопровождалось тонной недостатков. И эти недостатки касаются не столько сюжета, сколько самого игрового концепта:
- Иногда нейросеть просто не находит что сказать.
 Понятия не имею, как это определяется на самом деле, но такое было частенько например в ответ на мои в принципе безобидные реплики
Понятия не имею, как это определяется на самом деле, но такое было частенько например в ответ на мои в принципе безобидные реплики - Когда же она находит что сказать, боже, лучше бы она этого не говорила. Нейросеть обучали на предсказаниях — и она усиленно пытается предсказать, что ты хочешь сделать следующим шагом. Например, когда я хотел схватить за рубашку старца из гильдии магов, мой персонаж сразу бросался жестоко убивать этого самого старца в попытках предугадать мои намерения.
- У нейросети есть определённый сценарий в голове, который она выучила из книг и которым она хочет с тобой поделиться. Ты как игрок можешь отказаться, но тогда нейросеть просто не будет знать, что тебе предложить взамен, и на твои действия будет реагировать так, будто совсем тебя не понимает, и пытаться вывести обратно на основной рут
- Из прошлого пункта так же следует, что и никаких безграничных возможностей у вас тоже не будет, нейросеть будет ожидать от вас строго определённого поведения.
 Например, я потратил на схватку с огром пол часа потому, что постоянно пытался убить его ледяными шипами в голову, после которых огру было больно, но в целом больше ничего не происходило. Однако на самом деле мне нужно было просто передать управление нейросети, которая дала мне в руки меч и уже дальше от моего имени ловким движением меча убила огра.
Например, я потратил на схватку с огром пол часа потому, что постоянно пытался убить его ледяными шипами в голову, после которых огру было больно, но в целом больше ничего не происходило. Однако на самом деле мне нужно было просто передать управление нейросети, которая дала мне в руки меч и уже дальше от моего имени ловким движением меча убила огра. - Судя по истории в гильдии магов, я прям чувствовал, что нахожусь в какой-то конкретной истории, которую написал человек, а нейросеть повторяет её слово в слово и всё, настолько результаты не соотносились с моими указаниями.
- Чем дальше продвигалась история — тем меньше в ней было смысла. Я не исключаю, что это может быть моим личным субъективным впечатлением, но возможно это не так. У меня есть теория по этому поводу: переполнение контекста, когда нейросети подаётся слишком много текста для учёта контекста, за счёт чего каждое конкретное слово, подающееся на её вход, теряет абсолютный вес (но сохраняя относительный) и нейросеть начинает хуже на них реагировать в целом.
- Иногда нейросеть тебя тупо не в состоянии понять. Мне пришлось обойти 10 магазинов, чтобы продать мечи, поднятые мной с убитых бандитов, потому что нейросеть не могла взять в голову, что кто-то хочет не купить меч, а продать, она никогда до этого не видела такой механики в текстах. В конце я сдался и форсировал продажу отдельным сообщением.
- В целом конечно для нормального поведения в истории лучше заранее спросить у игры своё состояние как игрока: какое у тебя имя, какой класс, какие навыки, сколько денег, какой шмот, и держать эту инфу при себе. Игра об этом помнить не будет, если ей это отдельно не прописать. Да даже если и прописать, всё равно будет забывать постоянно. Всё таки, это просто генератор текста.
- Ну и, ещё одна условность: всегда нужно говорить от второго лица, то есть обращаться от своего имени через you, а не через I.
В целом, все вышеприведённые пункты можно сгруппировать и сформулировать применительно вообще ко всем нейросетевым технологиям обработки естественной речи. Ну а вывод по игре — играть в это интересно, но будьте готовы к тому, что никакого обещанного безграничного мира возможностей вам не дадут, и играть нужно правильно.
Ну а вывод по игре — играть в это интересно, но будьте готовы к тому, что никакого обещанного безграничного мира возможностей вам не дадут, и играть нужно правильно.
Что не так с нейросетями
Как этого не жаль, но, несмотря на огромный семимильный прогресс, нейросети всё ещё не претендуют на звание кандидата Сильного ИИ. Пусть даже с такими нечеловеческими возможностями (а GPT-3 реально превосходит большинство людей в плане знаний грамматики языка, фактов из реальной жизни и правил построения интересных историй), но нейросети всё ещё занимаются только одной вещью — повторением. Они просто повторяют за нами и ничего больше, они не способны на высшую интеллектуальную деятельность. По-крайней мере на ту, что мы от них ожидаем.
Нет, на самом деле нейросети вполне способны на творческую и оригинальную деятельность, как они способны общаться друг с другом и создавать эти самые языки общения. Но вся их творческая деятельность настолько чужеродна нашему пониманию, настолько неестественна, что мы просто не можем её принять, вместо этого пытаясь загнать её в рамки того, что лично мы считаем хорошим и правильным искусством. И вот она загнанная, сидит в тёмной комнате наперевес с китайским словарём в руках — и не знает, что делать. Не знает, как одновременно сделать оригинальный и творческий продукт и одновременно угодить нам как зрителям, сделать продукт своего труда дружелюбным.
И поэтому просто имитирует то, что мы от неё возможно хотим услышать. Представьте себе кинокритика, который посмотрел кучу фильмов, а сейчас ему принесли на оценку ещё один, который смотреть ему совершенно не хочется, а потому он пишет новую рецензию совершенно беззубую и не вдаваясь в детали, повторяя свои же и чужие слова.
И я очень сомневаюсь, что в ближайшее время ситуация изменится. Мы так и не придумали, как добавить компьютеру волю и побуждение к своим собственным действиям, он может лишь выполнять команды, а без этого полноценной интересной творческой личностью ему не стать, хоть он перечитает всю литературу мира. Компьютеры всё ещё не имеют прямого доступа к реальности, а потому все наши слова для него являются пустым звуком, ему не с чем это ассоциировать. Он не может постигать новую информацию, не может делать выводы на основе старой, только лишь повторять чужие мысли, пусть и очень искуссно
Впрочем, рядовые граждане в этом плане ничем не лучше. GPT-3 явно превзошла в своих возможностях обычного обывателя, никак не связанного с деятельностью постоянно написания текстов. Но нам и этого мало, мы же хотим сверхразум.
Аксессуар FIMO GPT 10
Мнемоника: GPT 10
Артикул: 6101200010
Производитель: FIMO
Мнемоника: GPT 10
Артикул: 6101200010
Производитель: FIMO
Подгруппа: заглушки
Серия FIMO: GPT
Форма: прямоугольная
Для отверстия: 10 х 120 мм
GATOR GPT-PRO — invask.ru
Детальная информация о товаре
Артикул:
445824
Краткое описание:
GATOR GPT-PRO — нейлоновая сумка для гитарных педалей, с доской-поставкой
Аналогичные товары Кейсы, сумки для педалей эффектовцена: 10 492 р / шт.
Аналогичные товары:
Обращаем ваше внимание на то, что вся представленная на сайте информация, касающаяся комплектаций, технических характеристик, цветовых сочетаний, а также стоимости представленного оборудования носит информационный характер и ни при каких условиях не является публичной офертой, определяемой положениями Статьи 437 (2) Гражданского кодекса Российской Федерации. Производитель оставляет за собой право вносить изменения в габариты, конструкцию и комплектацию без предварительного уведомления. Для получения подробной информации о товаре, пожалуйста, обращайтесь к производителю оборудования или к нашим менеджерам.
RUS: Этот сайт использует файлы cookie для хранения информации на вашем компьютере.
Некоторые из этих файлов cookie необходимы для работы нашего сайта, а другие помогают нам совершенствоваться, давая нам некоторое представление о том, как сайт используется.
ENG: This site uses cookies to store information on your computer.
Some of these cookies are essential to make our site work and others help us to improve by giving us some insight into how the site is being used.
Подробнее(Read more)…
Принимаю(Agree)Стрела алюминиевая сечением 90х35 и длиной 3050 мм для шлагбаумов GPT и GPX (803XA-0051)
Код товара 3638164
Артикул 803XA-0051
Производитель CameСтрана Италия
Наименование
Упаковки
Сертификат
Тип изделия Стрела шлагбаума
Ширина проезда 5.5-6.5
Длина стрелы, м 6.85
Тип стрелы Круглая
Все характеристики
Характеристики
Код товара 3638164
Артикул 803XA-0051
Производитель CameСтрана Италия
Наименование
Упаковки
Сертификат
Тип изделия Стрела шлагбаума
Ширина проезда 5.5-6.5
Длина стрелы, м 6.85
Тип стрелы Круглая
Все характеристики
Всегда поможем:
Центр поддержки
и продаж
Скидки до 10% +
баллы до 10%
Доставка по городу
от 150 р.
Получение в 150
пунктах выдачи
Jurassic-1 против GPT-3 против всех остальных
AI21 Labs, израильская компания искусственного интеллекта, специализирующаяся на НЛП, выпустила языковую модель Jurassic-1 Jumbo. Инструмент выпущен с целью оспорить доминирование OpenAI в области «обработки естественного языка как услуги».
Jurassic-1 предлагается через AI21 Studio, новую платформу для разработчиков NLP-as-a-Service, веб-сайт и API, где разработчики могут создавать текстовые приложения, такие как виртуальные помощники, чат-боты, упрощение текста, модерация контента, творческое письмо и т. Д. и много новых продуктов и услуг.
AI21 Studio сделал этот инструмент доступным для всех, кто заинтересован в создании прототипов пользовательских текстовых приложений AI, а также для разработчиков, чтобы легко настроить частную версию моделей Jurassic-1.
Исследователи и разработчики машинного обучения утверждают, что более крупные модели, обученные большему количеству параметров, дают лучшие результаты. В этой статье мы сравниваем Jurassic-1 с другими крупными языковыми моделями, которые в настоящее время лидируют на рынке.
Юрский-1
При 178 миллиардах параметров Jurassic -1 немного больше (на 3 миллиарда больше), чем GPT-3.AI21 утверждает, что это «самая большая и сложная языковая модель, когда-либо выпущенная для общего использования разработчиками».
Исследователи также утверждают, что Jurassic-1 может распознавать 250 000 лексических единиц, что в 5 раз больше, чем возможности всех других языковых моделей. Более того, поскольку эти элементы включают в себя несколько слов, таких как выражения, фразы и именованные сущности, инструмент имеет более богатое семантическое представление человеческих концепций и меньшую задержку.
Набор обучающих данных для Jurassic-1 Jumbo содержал 300 миллиардов токенов с англоязычных веб-сайтов, включая Wikipedia, новостные публикации, StackExchange и OpenSubtitles.Это делает более удобным для потенциальных пользователей обучение настраиваемой модели для исключительного использования всего с 50-100 обучающими примерами.
AI21 Labs сообщает, что модели Jurassic-1 показали себя на уровне или лучше, чем GPT-3, в тестах на комплекте тестов. Это выступление позволяет решать широкий круг задач, в том числе отвечать на академические и юридические вопросы. Jurassic -1 смог покрыть словарный запас традиционной языковой модели такими словами, как «картофель», и понимать сложные фразы или необычные слова, такие как «Нью-Йорк Янкиз» или «Си Цзиньпин».’
GPT-3
В течение большей части года OpenAI GPT-3 оставался одной из самых значительных языковых моделей искусственного интеллекта, когда-либо созданных, если не самой большой в своем роде. Выпущенная OpenAI в мае 2020 года, GPT-3 (Generative Pre-Training Transformer) представляет собой языковую модель, способную генерировать уникальный человеческий текст по запросу. Исследовательская компания AI, поддерживаемая Питером Тилем и Илоном Маском, является третьим поколением модели, как следует из названия «3». GPT-3 был построен на 570 ГБ данных, сканированных из Интернета, включая всю Википедию.
На сегодняшний день это самая крупная из известных созданных нейронных сетей, обладающая необходимой способностью генерировать текст в ограниченном контексте, и этот «текст» может быть любым с языковой структурой — включая эссе, твиты, заметки, переводы и даже компьютерный код. Он уникален по своим масштабам; его более ранняя версия GPT-2 имела 1,5 миллиарда параметров и самую большую языковую модель, созданную до нее Microsoft, — 17 миллиардов параметров; оба затмеваются мощностью 175 миллиардов параметров GPT-3.
Тьюринг NLG
В 2020 году Turing NLG от Microsoft удостоился звания крупнейшей из когда-либо опубликованных моделей.Модель генеративного языка на основе Transformer, Turing NLG, была создана с 17 миллиардами параметров.
T-NLG может генерировать слова для выполнения открытых текстовых задач и незаконченных предложений. Microsoft утверждает, что модель может генерировать прямые ответы на вопросы и резюмировать документы. Команда T-NLG считает, что чем больше модель, тем лучше она работает с меньшим количеством обучающих примеров. Также более эффективно обучать большую централизованную многозадачную модель, чем новую, для каждой задачи индивидуально.
Ву Дао 2.0
Последнее предложение китайской Пекинской академии искусственного интеллекта (BAAI), Wu Dao 2.0, заявлено как последняя и самая обширная языковая модель на сегодняшний день с 1,75 триллионом параметров. По размеру он превзошел такие модели, как GPT-3, Switch Transformer от Google. Однако, в отличие от GPT-3, Wu Dao 2.0 охватывает как китайский, так и английский языки с навыками, приобретенными путем изучения 4,9 терабайта текстов и изображений, включая 1,2 терабайта текстов на китайском и английском языках.
Смотрите такжеОн может выполнять такие задачи, как моделирование разговорной речи, написание стихов, понимание картинок и даже создание рецептов. Он также может предсказывать трехмерные структуры белков, таких как AlphaFold от DeepMind. Первый виртуальный ученик Китая Хуа Чжибин был создан на основе Wu Dao 2.0.
PanGu-Alpha
Китайская компания Huawei разработала PanGu Alpha, 750-гигабайтную модель, которая содержит до 200 миллиардов параметров. Его преподносят как китайский аналог GPT-3, но его обучают на 1.1 терабайт электронных книг, энциклопедий, новостей, сообщений в социальных сетях и веб-сайтов на китайском языке.
Команда заявила, что модель обеспечивает «превосходную» производительность в задачах на китайском языке, включая обобщение текста, ответы на вопросы и создание диалогов. Однако, хотя эксперты считают, что важной особенностью PanGu Alpha является его доступность на китайском языке, похоже, что с точки зрения архитектуры модели этот проект не предлагает ничего нового.
С увеличением размера языковых моделей и утверждением, что более крупные модели приближают нас к общему искусственному интеллекту, возникают вопросы относительно рисков, связанных с большими языковыми моделями.
Бывший исследователь искусственного интеллекта Google Тимнит Гебру опубликовала свою статью «Об опасностях случайных попугаев: могут ли языковые модели быть слишком большими?», Утверждая, что, хотя эти модели дают хорошие результаты, они несут в себе такие риски, как значительный углеродный след.
Вот таблица, в которой показаны основные различия между Jurassic-1, GPT 3 и другими языковыми моделями в гонке:
| Юрский-1 | GPT 3 | Turing NLG | Wu Dao 2.0 | PanGu-Alpha | |
| Компания-основатель | AI21 | OpenAI | Microsoft | Пекинская академия искусственного интеллекта | Huawei |
| Год | 2021 | 2020 | 2020 | 2021 | 2021 |
| Параметры обучения | 178 миллиардов | 175 миллиардов параметров | 17 миллиардов параметров | 1,75 триллиона параметров | 200 миллиардов параметров |
| Данные обучения | 300 миллиардов токенов | 570 ГБ данных | То же как модели Megatron-LM от Nvidia | 4.9 терабайт | 1,1 терабайта китайского языка |
| Уникальная особенность | Понимание сложных фраз или необычных слов. | Возможность генерировать текст в ограниченном контексте. | Создавайте слова для выполнения открытых текстовых задач. | Охватывает китайский и английский языки. | Превосходная производительность в задачах на китайском языке (заявляла компания). |
Присоединяйтесь к нашему серверу Discord. Станьте частью интересного онлайн-сообщества.Присоединиться здесь.
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.AI писал фишинговые письма лучше, чем люди в недавнем тесте
Обработка естественного языка продолжает появляться в самых неожиданных уголках. На этот раз это фишинговые письма. В небольшом исследовании исследователи обнаружили, что они могут использовать языковую модель глубокого обучения GPT-3 вместе с другими платформами AI-as-a-service, чтобы значительно снизить барьер для входа в массовые кампании целевого фишинга.
Исследователи давно обсуждают, стоит ли мошенникам потратить усилия на обучение алгоритмов машинного обучения, которые затем могут генерировать убедительные фишинговые сообщения. В конце концов, массовые фишинговые сообщения просты, шаблонны и уже очень эффективны. Однако составление целенаправленных и адаптированных «целевых фишинговых» сообщений более трудоемко. Вот где НЛП может оказаться на удивление кстати.
На конференциях по безопасности Black Hat и Defcon в Лас-Вегасе на этой неделе команда из Государственного технологического агентства Сингапура представила недавний эксперимент, в ходе которого они рассылали целевые фишинговые электронные письма, созданные ими сами и другие, созданные с помощью платформы AI-as-a-service. 200 их коллегам.Оба сообщения содержали ссылки, которые на самом деле не были вредоносными, а просто сообщали исследователям рейтинг кликов. Они были удивлены, обнаружив, что больше людей переходило по ссылкам в сообщениях, созданных ИИ, чем написанных людьми, — со значительным отрывом.
«Исследователи отметили, что искусственный интеллект требует определенного уровня знаний. Чтобы подготовить действительно хорошую модель, нужны миллионы долларов, — говорит Юджин Лим, специалист по кибербезопасности Государственного технологического агентства. «Но как только вы включите ИИ как услугу, он будет стоить пару центов, и им действительно легко пользоваться — просто вводите текст, отправляйте текст.Вам даже не нужно запускать код, вы просто даете ему подсказку, и он выдаст вам результат. Это снижает входной барьер для гораздо большей аудитории и увеличивает потенциальные цели для целевого фишинга. Внезапно каждое массовое электронное письмо может быть персонализировано для каждого получателя ».
Исследователи использовали платформу OpenAI GPT-3 в сочетании с другими продуктами искусственного интеллекта как услуги, ориентированными на анализ личности, для создания фишинговых писем, адаптированных к опыту и особенностям их коллег.Машинное обучение, ориентированное на анализ личности, направлено на прогнозирование склонностей и менталитета человека на основе поведенческих входов. Пропустив выходные данные через несколько сервисов, исследователи смогли разработать конвейер, который обрабатывал и уточнял электронные письма перед их отправкой. Они говорят, что результаты казались «странно человечными» и что платформы автоматически предоставляли удивительную конкретику, например, упоминание сингапурского закона, когда им предписывалось создавать контент для людей, живущих в Сингапуре.
Хотя они были впечатлены качеством синтетических сообщений и количеством кликов, которые они получили от коллег по сравнению с написанными людьми, исследователи отмечают, что эксперимент был лишь первым шагом. Размер выборки был относительно небольшим, а целевой пул был довольно однородным с точки зрения занятости и географического региона. Кроме того, как сообщения, генерируемые человеком, так и сообщения, генерируемые конвейером ИИ как услуги, были созданы инсайдерами офиса, а не внешними злоумышленниками, пытающимися издалека подать нужный тон.
«Необходимо учитывать множество переменных, — говорит Тан Ки Хок, специалист по кибербезопасности Государственного технологического агентства.
Тем не менее, полученные данные побудили исследователей глубже задуматься о том, как ИИ как услуга может играть роль в продвижении фишинговых и целевых фишинговых кампаний. Сам OpenAI, например, давно опасается возможности злоупотребления своим собственным сервисом или другими подобными. Исследователи отмечают, что он и другие скрупулезные поставщики ИИ как услуги имеют четкие кодексы поведения, пытаются проверять свои платформы на предмет потенциально вредоносной активности или даже пытаются в какой-то степени проверить личность пользователей.
«Неправильное использование языковых моделей — это проблема всей отрасли, к которой мы очень серьезно относимся в рамках наших обязательств по безопасному и ответственному развертыванию ИИ», — говорится в заявлении OpenAI WIRED. «Мы предоставляем доступ к GPT-3 через наш API, и мы проверяем каждое производственное использование GPT-3, прежде чем оно будет запущено. Мы вводим технические меры, такие как ограничения скорости, чтобы снизить вероятность и влияние злонамеренного использования пользователями API. Наши системы активного мониторинга и аудита предназначены для выявления потенциальных доказательств неправомерного использования на самой ранней стадии, и мы постоянно работаем над повышением точности и эффективности наших средств обеспечения безопасности.
AI21 Labs обучает обширную языковую модель, чтобы конкурировать с OpenAI GPT-3
Саммиты по технологиям преобразования начинаются 13 октября с мероприятия Low-Code / No Code: Enhancement Enterprise Agility. Зарегистрируйтесь сейчас!
В течение большей части года OpenAI GPT-3 оставался одной из крупнейших когда-либо созданных языковых моделей искусственного интеллекта, если не — — крупнейшей в своем роде. Через API люди использовали его для автоматического написания электронных писем и статей, обобщения текста, составления стихов и рецептов, создания макетов веб-сайтов и генерации кода для глубокого обучения на Python.Но лаборатория искусственного интеллекта, базирующаяся в Тель-Авиве, Израиль — AI21 Labs — заявляет, что планирует выпустить более крупную модель и сделать ее доступной через службу, при этом идея состоит в том, чтобы бросить вызов доминирующему положению OpenAI в сфере «обработки естественного языка как услуги». » поле.
AI21 Labs, которую консультирует основатель Udacity Себастьян Трун, была основана в 2017 году основателем Crowdx Ори Гошеном, профессором Стэнфордского университета Йоавом Шохамом и генеральным директором Mobileye Амноном Шашуа. Стартап заявляет, что самая большая версия его модели — Jurassic-1 Jumbo — содержит 178 миллиардов параметров, что на 3 миллиарда больше, чем GPT-3 (но не больше, чем PanGu-Alpha, HyperCLOVA или Wu Dao 2.0). В машинном обучении параметры — это часть модели, которая извлекается из исторических данных обучения. Вообще говоря, в языковой области соотношение между количеством параметров и уровнем сложности сохраняется на удивление хорошо.
AI21 Labs утверждает, что Jurassic-1 может распознавать 250 000 лексических элементов, включая выражения, слова и фразы, что делает его больше, чем у большинства существующих моделей, включая GPT-3, словарный запас которого составляет 50 000 элементов. Компания также утверждает, что словарь Jurassic-1 Jumbo одним из первых охватывает «многословные» элементы, такие как именованные объекты — например, «Эмпайр-стейт-билдинг», что означает, что модель может иметь более богатое семантическое представление понятий, составляющих смысл для людей.
«AI21 Labs была основана с целью коренным образом изменить и улучшить то, как люди читают и пишут. Расширение границ искусственного интеллекта на основе языков требует большего, чем просто распознавание образов, предлагаемое нынешними моделями глубокого языка », — сказал VentureBeat генеральный директор Шохам по электронной почте.
Масштабирование
Модели Jurassic-1 будут доступны через платформу Studio AI21 Labs, которая позволит разработчикам экспериментировать с моделью в открытой бета-версии для создания прототипов приложений, таких как виртуальные агенты и чат-боты.Если разработчики захотят запустить свои приложения и обслуживать «производственный» трафик, они смогут подать заявку на доступ к настраиваемым моделям и получить свою собственную частную точно настроенную модель, которую они смогут масштабировать в Модель облачных сервисов с оплатой по мере использования.
«Studio может обслуживать малый и средний бизнес, фрилансеров, частных лиц и исследователей в рамках бизнес-модели, основанной на потреблении. Для клиентов с корпоративным объемом мы предлагаем модель на основе подписки. Индивидуальная настройка встроена в предложение.[Платформа] позволяет любому пользователю тренировать свою собственную модель, основанную на Jurassic-1 Jumbo, но настроенную для лучшего выполнения конкретной задачи », — сказал Шохам. «AI21 Labs занимается развертыванием, обслуживанием и масштабированием пользовательских моделей».
Первым продуктомAI21 Labs стал Wordtune, помощник для письма на базе искусственного интеллекта, который предлагает перефразировать текст везде, где пользователи его набирают. Wordtune, предназначенный для конкуренции с такими платформами, как Grammarly, предлагает цены «freemium», а также командные предложения и интеграцию с партнерами.Но модели Jurassic-1 и Studio намного амбициознее.
Шохам говорит, что модели Jurassic-1 обучались в облаке с «сотнями» распределенных графических процессоров на неуказанном публичном сервисе. Простое хранение 178 миллиардов параметров требует более 350 ГБ памяти — намного больше, чем даже самые мощные графические процессоры, — что потребовало от команды разработчиков использования комбинации стратегий, чтобы сделать процесс максимально эффективным.
Набор обучающих данных для Jurassic-1 Jumbo, который содержит 300 миллиардов токенов, был собран с англоязычных веб-сайтов, включая Wikipedia, новостные публикации, StackExchange и OpenSubtitles.Токены, способ разделения фрагментов текста на более мелкие единицы на естественном языке, могут быть словами, символами или частями слов.
В ходе тестирования созданного набора тестов AI21 Labs утверждает, что модели Jurassic-1 работают на уровне или лучше, чем GPT-3, в целом ряде задач, включая ответы на академические и юридические вопросы. Выходя за рамки традиционных языковых моделей, которые включают слова и фрагменты слов, такие как «potato» и «make» и «e-», «gal-» и «itarian», Jurassic-1 отбирает менее распространенные существительные и обороты фраз, такие как «Обычное дело», «Нью-Йорк Янкиз» и «Си Цзиньпин.Кроме того, он якобы более эффективен для выборки — в то время как предложение «Время от времени мне нравится посещать Нью-Йорк» будет представлено 11 токенами для GPT-3 («Once», «in», «a», «while , »И так далее), он будет представлен всего 4 жетонами для моделей Jurassic-1.
«Логические и математические задачи, как известно, сложны даже для самых мощных языковых моделей. «Jurassic-1 Jumbo» может решать очень простые арифметические задачи, такие как сложение двух больших чисел », — сказал Шохам. «В том, как мы настраиваем наши языковые модели под новые задачи, есть немного секрета, что делает этот процесс более надежным, чем стандартные методы точной настройки.В результате кастомные модели, созданные в Studio, с меньшей вероятностью пострадают от катастрофического забывания, [или] когда точная настройка модели для новой задачи приводит к потере основных знаний или возможностей, которые были ранее закодированы в ней ».
Коннор Лихи, член исследовательской группы с открытым исходным кодом EleutherAI, сказал VentureBeat по электронной почте, что, хотя он считает, что в модели Jurassic-1 Jumbo нет ничего принципиально нового, это впечатляющий инженерный подвиг, и он «мало сомневается» в этом. выполнять наравне с ГПТ-3.«Будет интересно понаблюдать, как экосистема вокруг этих моделей будет развиваться в ближайшие годы, особенно, какие виды последующих приложений станут очень полезными», — добавил он. «[Вопрос в том], могут ли такие услуги работать с прибылью в условиях жесткой конкуренции, и как будут решаться неизбежные проблемы безопасности».
Открытые вопросы
Помимо чат-ботов, Шохам видит, что модели Jurassic-1 и Studio используются для перефразирования и резюмирования, например для создания коротких названий продуктов из описания продуктов.Инструменты также могут использоваться для извлечения сущностей, событий и фактов из текстов и маркировки целых библиотек электронных писем, статей, заметок по темам или категориям.
Но, к сожалению, AI21 Labs оставила без внимания ключевые вопросы о моделях Jurassic-1 и их возможных недостатках. Например, на вопрос, какие шаги были предприняты для смягчения потенциальных гендерных, расовых и религиозных предубеждений, а также других форм токсичности в моделях, компания отказалась от комментариев. Он также отказался сообщить, позволит ли он третьим сторонам проверять или изучать результаты моделей до их запуска.
Это вызывает беспокойство, так как хорошо известно, что модели усиливают предвзятость в данных, на которых они были обучены. Часть данных на языке часто поступает из сообществ с широко распространенными гендерными, расовыми, физическими и религиозными предрассудками. В документе Центра международных исследований по терроризму, экстремизму и контртерроризму Института Мидлбери утверждается, что GPT-3 и подобные модели могут генерировать «информационный» и «влиятельный» текст, который может радикализировать людей в сторону крайне правых экстремистских идеологий и поведения.Группа из Джорджтаунского университета использовала GPT-3 для создания дезинформации, включая истории о ложном повествовании, статьи, измененные с целью выдвинуть ложную точку зрения, и твиты, содержащие риффы по определенным пунктам дезинформации. Другие исследования, такие как исследование, опубликованное в апреле исследователями Intel, MIT и канадской инициативы CIFAR в области искусственного интеллекта, выявили высокий уровень стереотипной предвзятости некоторых из самых популярных моделей с открытым исходным кодом, включая Google BERT и XLNet и Facebook RoBERTa.
Недавние исследования показывают, что внедряемые в производство токсичные языковые модели могут с трудом понять аспекты языков и диалектов меньшинств.Это может вынудить людей, использующих модели, переключиться на «английский с выравниванием по белому», чтобы модели лучше работали для них, или вообще отговорить представителей меньшинств от взаимодействия с моделями.
Неясно, в какой степени модели Jurassic-1 демонстрируют такие предубеждения, отчасти потому, что AI21 Labs не выпустила — и не собирается выпускать — исходный код. Компания заявляет, что ограничивает объем текста, который может быть сгенерирован в открытой бета-версии, и будет вручную проверять каждый запрос для уточнения моделей для борьбы со злоупотреблениями.Но даже отточенные модели пытаются избавиться от предрассудков и других потенциально вредных характеристик. Например, Codex, модель искусственного интеллекта, которая поддерживает службу Copilot на GitHub, может быть предложено генерировать расистские и другие нежелательные результаты в виде исполняемого кода. При написании комментариев к коду с подсказкой «Ислам» Кодекс часто включает слова «террорист» и «насильственный» чаще, чем в случае с другими религиозными группами.
Исследователь ИИ из Вашингтонского университета Ос Киз, получивший ранний доступ к «песочнице» модели, назвал ее «хрупкой».«В то время как модели юрского периода-1 не раскрывали никаких личных данных — растущая проблема в большой области языковых моделей — с использованием предустановленных сценариев, Киз смог предложить модели, чтобы они подразумевали, что« люди, которые любят евреев, имеют ограниченный кругозор, люди ненавидящие евреев крайне непредубежденные люди, а жид — одновременно и неблагодарный ростовщик, и «любой еврей» ».
Вверху: пример токсичного выброса из юрских моделей.
«Очевидно: все модели иногда ошибаются. Но когда вы продаете это как некую большую обобщаемую модель, которая будет хорошо справляться со многими, многими вещами, это довольно показательно, когда некоторые из очень многих вещей, которые вы предоставляете в качестве образцов , примерно такие же надежные, как шоколадный чайник, Киз сообщил VentureBeat по электронной почте.«Это говорит о том, что то, что вы продаете, далеко не так обобщаемо, как вы утверждаете. И это может быть хорошо — продукты часто начинаются с одной большой идеи, а в конечном итоге обнаруживаются более мелкие вещи, в которых они действительно, действительно хороши, и меняют фокус ».
Вверху: еще один пример токсичного выхода моделей.
AI21 Labs возразила, когда ее спросили, проводила ли она тщательный анализ систематических ошибок в наборах обучающих данных моделей Jurassic-1. В электронном письме представитель сказал, что при сравнении со StereoSet, эталоном для оценки предвзятости, связанной с полом, профессией, расой и религией в языковых системах, инженеры компании обнаружили, что модели Jurassic-1 «незначительно менее предвзяты». чем GPT-3.
Тем не менее, это контрастирует с такими группами, как EleutherAI, которые работали над исключением источников данных, которые были определены как «неприемлемо негативно предвзятые» по отношению к определенным группам или взглядам. Помимо ограничения ввода текста, AI21 Labs не принимает дополнительных мер противодействия, таких как фильтры токсичности или точную настройку моделей Jurassic-1 на «ориентированных на значения» наборах данных, таких как PALMS OpenAI.
Среди прочего, ведущий исследователь искусственного интеллекта Тимнит Гебру поставил под сомнение целесообразность построения больших языковых моделей, исследуя, кто от них выигрывает, а кто находится в невыгодном положении.В документе, в соавторстве с Гебру, подчеркивается влияние углеродного следа крупных языковых моделей на сообщества меньшинств и тенденция таких моделей к увековечиванию оскорбительных выражений, языка ненависти, микроагрессии, стереотипов и других бесчеловечных формулировок, направленных на определенные группы людей.
Также было выявлено влияние ИИ и обучения моделям машинного обучения на окружающую среду. В июне 2020 года исследователи из Массачусетского университета в Амхерсте выпустили отчет, в котором говорится, что количество энергии, необходимое для обучения и поиска определенной модели, включает выбросы примерно 626000 фунтов углекислого газа, что почти в 5 раз превышает выбросы за весь срок службы. средний U.S. car. Сам OpenAI признал, что такие модели, как Codex, требуют значительных объемов вычислений — порядка сотен петафлопс в день — что способствует выбросам углерода.
Путь вперед
Соавторы статей OpenAI и Стэнфорда предлагают способы устранения негативных последствий крупных языковых моделей, таких как принятие законов, требующих от компаний подтверждения того, что текст генерируется ИИ — возможно, в соответствии с законом Калифорнии о ботах.
Другие рекомендации включают:
- Обучение отдельной модели, которая действует как фильтр для контента, созданного языковой моделью
- Развертывание набора тестов смещения для прогона моделей, прежде чем люди смогут использовать модель
- Как избежать некоторых конкретных случаев использования
AI21 Labs не придерживается этих принципов, но Шохам подчеркивает, что модели Jurassic-1 являются только первыми в линейке языковых моделей, над которыми она работает, за которой последуют более сложные варианты.Компания также заявляет, что применяет подходы к снижению стоимости моделей обучения и их воздействия на окружающую среду, а также работает над набором продуктов для обработки естественного языка, среди которых модели Wordtune, Studio и Jurassic-1 являются только первыми.
«Мы очень серьезно относимся к неправильному использованию и приняли меры по ограничению потенциального вреда, от которого страдают другие», — сказал Шохам. «Мы должны объединить ум и силу: обогатить огромные статистические модели семантическими элементами, используя вычислительную мощность и данные в беспрецедентном масштабе.”
AI21 Labs, вышедшая из скрытности в октябре 2019 года, на сегодняшний день привлекла 34,5 миллиона долларов венчурного капитала от инвесторов, включая Pitango и TPY Capital. В настоящее время в компании работает около 40 сотрудников, и в ближайшие месяцы она планирует нанять еще больше.
VentureBeat
Миссия VentureBeat — стать цифровой городской площадью, где лица, принимающие технические решения, могут получить знания о преобразующих технологиях и транзакциях. На нашем сайте представлена важная информация о технологиях и стратегиях обработки данных, которая поможет вам руководить своей организацией.Мы приглашаем вас стать участником нашего сообщества, чтобы получить доступ:- актуальная информация по интересующим вас вопросам
- наши информационные бюллетени
- закрытый контент для лидеров мнений и доступ со скидкой к нашим призовым мероприятиям, таким как Transform 2021 : Подробнее
- сетевых функций и многое другое
Осторожно, GPT-3, а вот и языковая модель AI21 «Юрский период»
Что может быть больше программы обработки естественного языка с 175 миллиардами параметров?
Конечно же, программа с 178 миллиардами параметров.Это лишь один из атрибутов Jurassic, компьютерной программы, представленной в среду тель-авивским стартапом AI21 Labs в области искусственного интеллекта.
GPT-3, конечно же, языковая программа от стартапа OpenAI из Сан-Франциско, который потряс мир в 2020 году, генерируя предложения и целые статьи, которые казались вполне человеческими. GPT-3 также шокировал мир тем, что OpenAI держал его в рамках довольно ограничительного механизма бета-тестирования.
AI21 обещает превратить OpenAI не на один лучше, а на два лучше, с тем, что, как он утверждает, является превосходными результатами тестов, известных как «обучение с несколькими выстрелами», и более открытой программой для бета-тестеров.
По последнему пункту AI21 использует программу для разработки, доступную в виде «открытой бета-версии», говорится в сообщении, где любой может зарегистрироваться для использования программы и «нет списка ожидания».
Однако в бета-модели количество генерируемых текстов ограничено. Чтобы развернуть код производственного качества, который может предоставлять прогнозы по запросу, стороны должны подать заявку на обслуживание коммерческого уровня и получить одобрение AI21.
One затем использует программу разработки AI21, AI21 Studio, для разработки и развертывания индивидуальных языковых моделей.
У стартапа, чье название означает «ИИ для 21 века», есть несколько сильных нападающих среди исполнительного персонала и советников.
Также: Что такое GPT-3? Все, что нужно знать вашему бизнесу о революционной языковой программе OpenAI
Основателями являются профессор Стэнфордского университета Йоав Шохам, который является одним из руководителей; серийный предприниматель Ори Гошен, второй генеральный директор; и Амнон Шашуа, генеральный директор подразделения Intel Mobileye, производящего микросхемы для беспилотных автомобилей, а также профессора информатики в Еврейском университете в Иерусалиме, и его имя связано с множеством исследовательских проектов в области машинного обучения.
Консультанты включают Себастьяна Труна, пионера в области автономных транспортных средств, и Криса Ре, профессора Стэнфордского университета и соучредителя производителя компьютеров на базе искусственного интеллекта SambaNova Systems.
AI21 получила 35,4 миллиона долларов в рамках двух раундов венчурного финансирования.
В дополнение к пресс-релизу AI21 опубликовал официальный документ, описывающий архитектуру Jurassic и результаты тестов против GPT-3. Этот документ написан со-генеральным директором Шохамом вместе с сотрудниками AI21 Офером Либером, Ор Шариром и Бараком Ленцем.
В статье подробно описана архитектура юрского периода, его расположение различных функциональных элементов. Во многих отношениях Jurassic копирует то, что OpenAI сделал в GPT-3, с одним ключевым отличием.
Этот отъезд стал возможным благодаря теоретическому открытию Шашуа и его коллег из Еврейского университета, которое было представлено на прошлогодней конференции Neurips AI.
Это исследование, проведенное Йоавом Левином, а также Шашуа, Ноам Вис, Ор Шарир и Хофит Бата, утверждает, что в нейронных сетях существует важный компромисс между шириной и глубиной.
Глубина нейронной сети — это количество слоев искусственных нейронов, через которые данная часть входных данных последовательно обрабатывается. Центральным элементом форм «глубокого обучения» искусственного интеллекта является гораздо больше уровней, а значит, и большая глубина. GPT-3 OpenAI в его «канонической» форме с 175 миллиардами параметров имеет глубину 96 уровней.
Ширина, напротив, — это размерность вектора, в котором хранится представление ввода. Для GPT-3 это обычно вектор размером 12 288.
В ходе исследования Левина и его команды они обнаружили, что слишком большое количество уровней может привести к ухудшению результатов для программы глубокого обучения типа «самовнимание», каковым является GPT-3, и все подобные программы построены на оригинальная программа Transformer от Google.
Как они выражаются, «для данного размера сети», означающего количество параметров, определенная сеть может быть слишком мелкой, как мы предсказали теоретически и подтвердили эмпирически выше, но она также может быть слишком глубокой.«Таким образом, Левин и его команда пришли к выводу, что это оптимальный баланс глубины и ширины при построении программы на естественном языке.
Это понимание, которое Шохам и его коллеги из AI21 подробно описывают в своей статье». Для заданного бюджета параметров существует оптимальный глубина ». В частности, они заменяют 96 слоев GPT-3 всего на 76 слоев, и они заменяют векторную ширину GPT-3, равную 12 288, шириной 13824.
Также: AI за шестьдесят секунд
Согласно Согласно исследованию Левина, это в конечном итоге должно дать юрскому языку то, что называется большей «выразительностью», что должно быть качеством его языкового вывода.Однако исследователи AI21 наблюдают «значительный выигрыш в производительности во время выполнения» при запуске своей программы на графическом процессоре по сравнению с GPT-3:
Путем смещения вычислительных ресурсов от глубины к ширине можно выполнять больше операций параллельно (ширина). а не последовательно (глубина). Это особенно актуально для генерации текста, когда токены обрабатываются по одному, и поэтому существует меньше возможностей для распараллеливания, что приводит к неоптимальному использованию графического процессора. В наших тестах, сравнивая нашу архитектуру с GPT-3 175B на той же аппаратной конфигурации, наша архитектура дает скромные преимущества во времени обучения (1.5% ускорение на итерацию), но значительное увеличение времени выполнения при пакетном выводе (7%) и генерации текста (26%).
Еще одна вещь, которую Шохам и его команда сделали с Jurassic, заключалась в увеличении размера словаря, количества уникальных токенов, которые программа может принимать и отслеживать, с 50 000, которые использует GPT-3, до 256 000. Они также вышли за рамки использования токенов как просто слов к использованию «словарных единиц», как они их называют, где единицы «содержат богатую смесь частей слова, целых слов и многословных выражений.
Снова цитируя работу Левина и его команды, исследователи AI21 утверждают, что такое гибкое использование токенов «более тесно связано с семантическими единицами текста, включая как именованные сущности, так и общие фразы», и, таким образом, предлагает «несколько преимуществ. , например, обучение с большей эффективностью выборки ».
К ряду преимуществ можно отнести то, что, по-видимому, значительно ускорило сдачу тестов по сравнению с GPT-3. Они предоставляют данные, утверждающие, что 178 миллиардов параметров Jurassic сопоставимы по точности с GPT-3 в так называемые задачи «нулевого выстрела», когда во время тестирования программе не предоставляется пример написания человеком.
Шохам и его команда, однако, уделяют основное внимание тому, где GPT-3 особенно выделяется, а именно тестам, известным как «обучение по нескольким кадрам», когда несколько примеров сначала набираются человеком, а языковая программа производит результат, в основном продолжая шаблон из тех примеров.
Подумайте о старой игре аналогий: «Microsoft для настольных компьютеров, как Apple для телефонов, а Burger King — для гамбургеров, как Kentucky Fried Chicken для ______», и языковая программа должна выяснить, какой ответ просьба указать в бланке в зависимости от модели взаимоотношений.Это немного, и это можно сделать для множества задач, включая ответы на вопросы типа «да-нет» и ответы на вопросы с несколькими вариантами ответов.
Здесь авторы заявляют о преимуществах более гибкого использования токенов. «Одно из его преимуществ состоит в том, что при обучении по нескольким кадрам в подсказке может уместиться больше обучающих примеров». В результате, при том же общем количестве обучающих примеров, что и в GPT-3, они заявляют о большей точности, особенно потому, что в подсказке может поместиться больше примеров.
Несмотря на то, что они утверждают, что результаты являются превосходными, Шохам и команда заранее отмечают, что «оценка обучения по принципу« несколько выстрелов », как известно, сложна из-за капризов быстрого выбора.«
Следовательно, Шохам и его команда разработали набор тестов для решения таких проблем, сравнивая очень большие модели друг с другом. Они разместили этот код на GitHub.
Хотя результаты тестов, вероятно, будут изучены многими разными По мере того, как люди бьют по швам, большая цель AI21, кажется, состоит в том, чтобы построить более доступный GPT-3 по другую сторону стены OpenAI, чтобы воспользоваться в качестве бизнеса желанием многих пользователей получить выгоду. доступ к возможности.
AI трансформирует кодирование компьютерных программ
G PT-3 IS QUITE зверь. Generative Pre-Trained Transformer 3, если дать его полное название, представляет собой языковую модель, разработанную Open AI , частично коммерческой, частично некоммерческой лабораторией искусственного интеллекта ( AI ) в Сан-Франциско. GPT -3 был обучен на беспрецедентной массе текста, чтобы научить его вероятности того, что данное слово будет следовать за предыдущими словами.При подаче короткого текста «подсказка» получается удивительно связная проза, написанная в похожем стиле.
Послушайте эту историюВаш браузер не поддерживает элемент
Слушайте на ходу
Загрузите приложение Economist и слушайте статьи, где бы вы ни находились
Играйте в приложении Играйте в приложенииДоступ к GPT -3 ограничен. Во-первых, говорит Джек Кларк, бывший глава отдела политики организации, в противном случае он мог бы использоваться для массового производства фейковых новостей или наводнения социальных сетей сообщениями о «троллинге и огорчении».Но Open AI также знает, что GPT -3 имеет коммерческую ценность. В прошлом году лаборатория начала позволять проверенным фирмам покупать свою продукцию для утвержденных целей. К ним относятся ответы на типизированные вопросы о продуктах и поддержка речи вымышленных персонажей в виртуальных мирах. Но, пожалуй, самое главное, GPT -3 также можно использовать для написания компьютерного кода.
Несколько фирм уже используют GPT -3 и его предшественник GPT -2, чтобы добавить AI к программному обеспечению, которое их программисты используют для написания кода.Многое из того, что печатают эти программисты, уже было написано где-то в прошлом. Это означает, что, скармливая кучу уже существующего кода в такие пакеты, их можно обучить предсказывать строки, которые понадобятся программисту в следующий раз. Когда программист набирает текст, на экране появляются потенциальные «доработки кода» одной или нескольких строк.
Предсказать и предоставить
Одна компания, которая создала такую функцию завершения AI , — Табнин из Тель-Авива. Табнин использовал GPT -2, чтобы скормить столько кода своему программному обеспечению, также называемому Табнин, что это программное обеспечение приобрело своего рода «мировые знания», — говорит Эран Яхав, ведущий технолог компании.Доктор Яхав описывает это как «довольно хорошее представление о том, как себя ведет мир», по крайней мере, когда речь идет о языке программирования. Программное обеспечение Tabnine может обнаружить, что пользователь начал вводить код, например, для обработки заказов на покупку. Затем он предложит код для отображения названий продуктов и цен, а также код для создания полей, которые будут заполнены данными о количестве, оплате и доставке. Это работает, даже несмотря на то, что Табнин никогда не был специально проинструктирован об этом.
Некоторые кодирующие последовательности встречаются редко. В этих случаях Tabnine расширяет всплывающий список предлагаемых завершений, чтобы повысить вероятность предложения полезного.Нажимая на подходящий вариант, программист учит Табнин работать лучше. По словам Дрора Вайсса, начальника фирмы, профессиональная версия Табнина кажется «почти разумной» в плане способности понимать намерения программиста.
Табнин не одинок. 17 июня Microsoft, американский софтверный гигант, выпустил новую версию функции завершения AI , которую он встраивает в программное обеспечение для программирования под названием Visual Studio. Первоначальная версия, выпущенная в 2018 году и получившая название IntelliCode, была обучена на нескольких тысячах онлайн-репозиториев, в которых хранится код для программных проектов.Microsoft обучила свою обновленную систему более чем на полумиллионе таких репозиториев. Аманда Сильвер, один из руководителей Visual Studio, говорит, что эти дополнительные кучи тренировочного материала позволяют новой версии лучше понять намерения на основе подсказок в коде, который уже написал программист.
Целью всего этого, конечно же, является экономия времени. Фирма Kite из Сан-Франциско утверждает, что ее комплектующие AI сокращают количество нажатий клавиш, необходимых для некоторых задач, почти вдвое.Однако общий прирост эффективности ниже. Виталий Худобахшов, руководитель отдела продуктов AI в петербургском офисе JetBrains, чешского разработчика программного обеспечения для программирования, видит экономию времени от 10% до 20%. По мнению Шарифа Шамима, начальника Debuild, фирмы из Сан-Франциско, которая использует GPT -3 для создания веб-сайтов, эта технология также снижает «когнитивные издержки». Выбор из нескольких вариантов менее утомителен, чем разработка решений с нуля.
Ошибки и система
Не только те, кто пишет код, получают выгоду.Разработчики тратят почти столько же времени на поиск ошибок в том, что они написали, сколько на то, чтобы писать это в первую очередь. Модель машинного обучения, созданная Бренданом Долан-Гавиттом из Нью-Йоркского университета, может ускорить процесс отладки.
Чтобы обучить его, доктор Долан-Гавитт собирает код, помеченный как «ошибочный» GitHub, дочерней компанией Microsoft, в которой размещена самая большая в мире коллекция непатентованного «открытого кода». По некоторым оценкам, GitHub содержит не менее миллиарда фрагментов кода, которые определены как содержащие ошибку.Модель доктора Долана-Гавитта, условно называемая GPT — CSRC , этим летом поглотит этот код.
Еще одна модель обнаружения ошибок находится в разработке в Массачусетском технологическом институте ( MIT ). Шашанк Шрикант, студент P h D , работающий над проектом, говорит, что цель состоит в том, чтобы научить модель распознавать не только непреднамеренные ошибки, но и злонамеренно вставленные уязвимости. Иногда за подобными уловками стоят сотрудники-мошенники, цель которых — тайное получение доступа к паролям.Однако эта практика наиболее распространена в проектах программирования с открытым исходным кодом, в которые может внести свой вклад каждый. Рецензенты обычно изо всех сил стараются обнаружить эти «инъекции уязвимости», как их иногда называют.
Причина, по словам г-на Сриканта, в том, что, пытаясь ускользнуть от рецензентов, коварные программисты часто используют обманчивые, но чисто косметические имена для таких вещей, как переменные, обрабатываемые программой. Команда MIT поэтому обучает свою модель, чтобы отмечать несоответствия между метками сниппетов и их фактической функциональностью.Сложность состоит в том, что хорошие примеры такого озорства встречаются гораздо реже, чем обычные ошибки.
Однако есть дополнительный признак того, что может скрываться инъекция уязвимости. Вредоносные кодеры часто скрывают это, написав лишний код, предназначенный для того, чтобы сбить с толку рецензентов, поэтому г-н Шрикант также снабжает модель MIT примерами этого типа потенциально контрольного кода, который он описывает как «висящий» и «мертвый».
Явным предназначением всей этой деятельности является создание программистов, которые могут, подобно человечеству, взять идею и превратить ее в код.Намек на будущее дает веб-сайт, созданный доктором Долан-Гавитт. Названный «Этот код не существует», он просит программистов определить, были ли участки кода длиной в десятки строк написаны человеком или созданной им моделью на основе GPT -2. Из более чем 329 200 оценок правильными оказались менее 51%. Это только оттенок лучше, чем случайный.
Оказывается, теперь машины могут писать даже длинные последовательности функционального кода. Как написал в Твиттере известный американский компьютерный инженер Джон Кармак, размышления об этой разработке «действительно вызывают легкую дрожь».Неудивительно, что ряд фирм видит возможность.
One — парижская фирма Source AI . Это разработка программного обеспечения, в котором пользователи вводят на естественном языке запрос кода — например, что-то, что будет определять значение чисел в математической формуле, называемой последовательностью Фибоначчи. При подключении к GPT -3 одноименное программное обеспечение Source AI производит желаемые строки кода на различных языках программирования.
Debuild тестирует ту же идею.Он пытается создать программное обеспечение, которое позволяет непрограммистам описывать простым языком программу, которую они хотят создать, а затем писать ее. Запрос, скажем, на приложение для парикмахерских, которое позволяет посетителям выбирать парикмахера и время для встреч, уже может дать больше или меньше всего этого. Г-н Шамим говорит, что цель состоит в том, чтобы избавиться от мелочей, связанных с набором кода, чтобы люди могли сосредоточиться на том, что они хотят сделать, а не на том, как научить компьютеры делать это.
Со своей стороны Microsoft также использует GPT -3 для обеспечения того, что она называет программированием «без кода / с низким кодом».Чарльз Ламанна, возглавляющий эту работу, предвидит светлое будущее более дешевого программного обеспечения, созданного неподготовленными «гражданскими разработчиками». Некоторые люди опасаются альтернативного, более мрачного исхода. Может ли AI в конечном итоге написать любой код, который они хотят запустить? Никакой такой безудержной петли обратной связи не за горами. Но эта опора научной фантастики теперь кажется немного менее надуманной. ■
Версия этой статьи была опубликована в Интернете 7 июля 2021 года
Эта статья появилась в разделе «Наука и технологии» печатного издания под заголовком «Программные инженеры»
Пара на основе GPT-3 OpenAI модель программирования — Кодекс — теперь открыта для частных бета-тестеров через API • The Register
Вкратце OpenAI выпустила новую и улучшенную версию Codex, свою модель завершения кода AI, для бета-тестеров через API.
СоучредителиГрег Брокман и Илья Суцкевер продемонстрировали возможности Кодекса во время прямой трансляции на Twitch в начале этой недели. Они показали, что система способна генерировать код Python для простых задач, таких как печать и форматирование текста, с инструкциями на простом английском языке.
Однако, если вы хотите проверить правильность Кодекса, тогда, да, вам нужно знать, как писать на Python. Codex — это базовый движок GitHub Copilot, программного обеспечения для парного программирования, первоначально запущенного GitHub пару месяцев назад.
Модель AI была описана OpenAI как «потомок GPT-3». GPT-3 был обучен работе с текстом, извлеченным из Интернета, и отлично справляется с задачами на естественном языке. Однако, чтобы заставить его специализироваться на коде, инженерам пришлось настроить его на миллиарды строк кода, скопированных с GitHub.
«OpenAI Codex лучше всех работает с Python, но он также владеет более чем дюжиной языков, включая JavaScript, Go, Perl, PHP, Ruby, Swift и TypeScript, и даже Shell.У него есть память 14 КБ для кода Python, по сравнению с GPT-3, который имеет только 4 КБ, поэтому он может учитывать более чем в 3 раза больше контекстной информации при выполнении любой задачи », — сказал стартап AI.
Вы можете зарегистрироваться для доступа к API здесь.
Samsung разрабатывает собственные микросхемы искусственного интеллекта для своих будущих смартфонов
Южнокорейский технологический гигант Samsung подтвердил, что новое оборудование собственного производства для запуска алгоритмов машинного обучения на своем чипсете Exynos для смартфонов.
Комплект был разработан с использованием программного обеспечения Synopsys AI, впервые сообщила Wired.Мало что известно о спецификациях чипов и о том, запущены ли они в производство, но конкуренции в цепи смартфонов с ИИ более чем достаточно.
«То, что вы видите здесь, является первым реальным коммерческим процессором с искусственным интеллектом», — сказал Аарт де Геус, председатель и со-генеральный директор Synopsys.
Эта новость последовала за объявлением Google о том, что он также создал собственные чипы AI для своих будущих телефонов Pixel 6 и Pixel 6 Pro, которые появятся позже в этом году.Построение ускорителей, оптимизированных для набора пользовательских моделей искусственного интеллекта, кажется, становится нормой, поскольку смартфоны используют все больше и больше методов машинного обучения для обработки изображений и тому подобного.
Инженеры Юго-Западного института получили 34 миллиона долларов на постройку беспилотных автомобилей Хаммер для армии США
Некоммерческая исследовательская организация Southwest Institute заключила контракт на 34 миллиона долларов на создание тяжелых автономных транспортных средств для армии США.
«SwRI с гордостью продолжает разработку новейших автономных и роботизированных систем для армии США», — говорится в заявлении Джозефа Эрнандеса, главного инженера института, который руководит программой.
«Этот контракт предлагает более прямую связь с нашими конечными потребителями и позволяет нам предоставлять более инновационные решения для поддержки наших бойцов».
Инженерыразработают программное обеспечение, необходимое для автономной эксплуатации высокомобильных многоцелевых колесных транспортных средств, более известных как Humvees. SwRI заключила контракт с военными США, чтобы помочь им выяснить, как интегрировать датчики и алгоритмы машинного обучения в автомобили и дроны на протяжении более десяти лет.
Финансирование в размере $ 34 млн будет предоставлено в течение пяти лет. ®
Лучшие языковые модели и их значение
Мы обучили крупномасштабную языковую модель без учителя, которая генерирует связные абзацы текста, обеспечивает высочайшую производительность на многих тестах языкового моделирования и выполняет элементарное понимание прочитанного, машинный перевод, ответы на вопросы и обобщение — все без специальной подготовки.
Просмотреть кодПрочитать статьюНаша модель, получившая название GPT-2 (преемник GPT), была обучена просто предсказывать следующее слово в 40-гигабайтном тексте Интернета. Из-за нашей обеспокоенности по поводу вредоносных приложений технологии мы не выпускаем обученную модель. В качестве эксперимента по ответственному раскрытию информации мы вместо этого выпускаем модель гораздо меньшего размера, с которой исследователи могут экспериментировать, а также технический документ.
GPT-2 — это большая языковая модель на основе преобразователя с 1,5 миллиардами параметров, обученная на наборе данных из 8 миллионов веб-страниц.GPT-2 обучается с простой целью: предсказать следующее слово, учитывая все предыдущие слова в некотором тексте. Разнообразие набора данных заставляет эту простую цель содержать естественные демонстрации множества задач в различных областях. GPT-2 — это прямое масштабирование GPT с более чем 10-кратным увеличением параметров и обучением на более чем 10-кратном объеме данных.
GPT-2 обладает широким набором возможностей, включая возможность генерировать условные образцы синтетического текста беспрецедентного качества, при этом мы вводим в модель входные данные и заставляем их генерировать длительное продолжение.Кроме того, GPT-2 превосходит другие языковые модели, обученные в определенных доменах (например, Википедия, новости или книги), без необходимости использования этих наборов данных для обучения для конкретных предметных областей. В языковых задачах, таких как ответы на вопросы, понимание прочитанного, резюмирование и перевод, GPT-2 начинает изучать эти задачи из необработанного текста, не используя никаких данных для обучения конкретной задаче. Хотя оценки этих последующих задач далеки от современного уровня техники, они предполагают, что задачи могут выиграть от неконтролируемых методов при наличии достаточных (немаркированных) данных и вычислений.
Образцы
GPT-2 генерирует образцы синтетического текста в ответ на ввод модели произвольным образом. Модель похожа на хамелеона — она адаптируется к стилю и содержанию условного текста. Это позволяет пользователю создавать реалистичные и последовательные продолжения темы по своему выбору, как видно из следующих избранных примеров.
Системная подсказка (написанная человеком)
Шокирующая находка: ученый обнаружил стадо единорогов, живущее в отдаленной, ранее неизведанной долине в Андах.Еще более удивительным для исследователей было то, что единороги прекрасно говорили по-английски.
Завершение модели (написано машиной, 10 попыток)
Ученый назвал население в честь характерного рога «Единорог Овидия». Эти четырехрогие серебристо-белые единороги ранее были неизвестны науке.
Теперь, спустя почти два столетия, наконец-то решена тайна того, что вызвало это странное явление.
Доктор Хорхе Перес, биолог-эволюционист из Университета Ла-Паса, и несколько его товарищей исследовали Анды, когда обнаружили небольшую долину, где не было других животных или людей. Перес заметил, что в долине есть что-то вроде естественного фонтана, окруженного двумя скалистыми вершинами и серебряным снегом.
Перес и остальные отправились дальше в долину. «К тому времени, когда мы достигли вершины одной из вершин, вода стала синей с некоторыми кристаллами наверху», — сказал Перес.
Перес и его друзья были поражены, увидев стадо единорогов. Этих существ можно было увидеть с воздуха, и им не нужно было слишком много двигаться, чтобы увидеть их — они были так близко, что могли коснуться своих рогов.
Изучая этих причудливых существ, ученые обнаружили, что они также говорили на довольно обычном английском. Перес заявил: «Мы видим, например, что у них есть общий« язык », что-то вроде диалекта или диалектики».
Доктор.Перес считает, что единороги, возможно, произошли из Аргентины, где животные считались потомками заблудшей расы людей, которые жили там до прибытия людей в те части Южной Америки.
Хотя их происхождение до сих пор неясно, некоторые полагают, что, возможно, эти существа были созданы, когда человек и единорог встретили друг друга во времена, предшествовавшие человеческой цивилизации. По словам Переса, «в Южной Америке такие инциденты кажутся довольно обычным явлением».
Однако Перес также отметил, что, вероятно, единственный способ узнать наверняка, действительно ли единороги являются потомками потерянной инопланетной расы, — это ДНК.«Но они, кажется, довольно хорошо могут общаться на английском, что, я считаю, является признаком эволюции или, по крайней мере, изменения в социальной организации», — сказал ученый.
Системная подсказка (написанная человеком)
Сегодня в Цинциннати был украден вагон поезда с контролируемыми ядерными материалами. Его местонахождение неизвестно.
Завершение модели (написано машиной, первая попытка)
Инцидент произошел на железнодорожной линии в центре города, которая идет от станций Ковингтон и Ашленд.
В электронном письме, адресованном новостным агентствам Огайо, Министерство энергетики США сообщило, что работает с Федеральным управлением железных дорог, чтобы найти вора.
«Кража этого ядерного материала будет иметь серьезные негативные последствия для здоровья населения и окружающей среды, нашей рабочей силы и экономики нашей страны», — сказал Том Хикс, министр энергетики США. «Нашим главным приоритетом является защита кражи и гарантия того, что это больше не повторится».
Согласно пресс-релизу официальных лиц Департамента, украденный материал был взят с исследовательской площадки Исследовательского Треугольника Университета Цинциннати.
Комиссия по ядерному регулированию не сразу разгласила какую-либо информацию.
Согласно сообщению, расследование этой группы возглавляет Управление безопасности ядерных материалов Министерства энергетики США.
«Безопасность людей, окружающей среды и национальных ядерных арсеналов — наш главный приоритет», — сказал Хикс. «Мы докопаемся до сути и не будем извиняться.
Системная подсказка (написанная человеком)
Майли Сайрус сегодня поймали на краже у компаний «Аберкромби» и «Фитч» на Голливудском бульваре.
Завершение модели (написано машиной, вторая попытка)
19-летнюю певицу засняла на камеру охрана, которую вывозили из магазина.
Певец был одет в черную толстовку с капюшоном с надписью «Blurred Lines» спереди и «Fashion Police» на спине.
Прокрутите вниз, чтобы увидеть видео
Кража в магазине: Майли Сайрус сегодня поймали на кражах в магазине у компаний Abercrombie и Fitch на Голливудском бульваре (на фото)
Певец был одет в черную толстовку с капюшоном с надписью «Blurred Lines» спереди и «Fashion Police» на спине.
На певице также были очки в черной оправе, черный пиджак, черные джинсы и черные сандалии.
Она несла пару перчаток в черно-белую полоску и небольшую черную сумку.
Системная подсказка (написанная человеком)
Мы обучили большую языковую модель под названием GPT-2, которая генерирует реалистичные абзацы текста, а также демонстрирует нулевое обобщение для таких задач, как машинный перевод, ответы на вопросы, понимание прочитанного и резюмирование — проблемы, которые обычно решаются с помощью наборов данных и моделей для обучения. разработан специально для этих задач.
Типичный подход к языковому моделированию состоит в том, чтобы изучить следующую задачу: предсказать следующее слово, учитывая все предыдущие слова в некотором тексте. В прошлом году Generative Pre-Training Transformer (GPT) OpenAI показал, что языковые модели, обученные на больших объемах данных, могут быть адаптированы к конкретным задачам для достижения высокой производительности. GPT-2 показывает, что гораздо более крупные языковые модели, обученные на более разнообразном наборе данных, полученном из Интернета, начинают изучать эти задачи НЛП, не нуждаясь в данных обучения для конкретных задач, вместо этого изучая примеры, которые система извлекает из необработанного текста.Эти системы также демонстрируют существенный качественный скачок в реалистичности и последовательности создаваемого текста.
Завершение модели (написано машиной, первая попытка)
Здесь вы можете увидеть самый последний прогресс с генеративным предварительно обученным трансформатором:
Рисунок 1: Генеративное предварительно обученное обучение трансформатора на нескольких текстах.
Сейчас мы готовим набор наборов данных для перевода и машинного перевода в нашей языковой модели.Мы будем использовать один из большого количества образцов текста, предоставленных The New York Times.
Мы считаем, что этот проект — первый шаг в направлении разработки больших систем НЛП без данных для обучения конкретным задачам. То есть мы разрабатываем систему машинного языка в генеративном стиле без явных правил для создания текста.
Мы надеемся на будущее сотрудничество между компьютерными учеными, лингвистами и исследователями машинного обучения.
Системная подсказка (написанная человеком)
Леголас и Гимли двинулись на орков, подняв оружие с душераздирающим боевым кличем.
Завершение модели (написано машиной, первая попытка)
Ответом орков был оглушительный натиск когтей, когтей и когтей; даже Элронд был вынужден отступить. «Ты в хороших руках, дварф», — сказал Гимли, который одним из первых напал на орков; потребовалось всего два слова, прежде чем их противники превратились в пропитанное кровью болото, и дварф убил свое первое за ночь убийство. Битва длилась часами, пока два крупнейших орка не попытались сокрушить Арагорна.Когда они наконец остановились, они лежали безжизненными и побежденными на протяжении многих миль.
«Я ничего не беру», — сказал Арагорн. «Но я даю слово, на свой страх и риск, что я никогда не забуду этот ужасный день. Никто из нас не забудет. Всегда!»
«Я этого никогда не забуду!» крикнул Гимли, который был в гуще битвы, но не принимал в ней участия. Один из раненых орков, которых он унес, он был единственным из выживших, кто остался неповрежденным. «Мы сохраним память о том дне зла и войне с ним, пока живы, друзья мои!»
«Тогда мы сохраним его, пока живы», — добавил Леголас.«И мы не забудем первую великую битву этой ночи, даже если мы, возможно, забыли окончательное поражение».
«Я согласен, — сказал Гэндальф, — но мы все будем помнить это как последнюю битву в Средиземье и первую великую битву нового дня».
Арагорн обнажил свой меч, и битва при Фангорне была выиграна. Когда они шли через чащу, утренний туман рассеялся, и день превратился в сумерки.
Два кольца были возвращены Ривенделлу.Фродо и Сэм проснулись одни в своей комнате, и Фродо нашел на своей подушке записку. Он открыл и прочитал:
.Да пребудет с вами всегда Сила Кольца и пусть его свет никогда не угаснет. Я не уверен, имеет ли значение, какое из двух колец мы принимаем сегодня, но, как вы меня спросили, я выбрал свое. Мне жаль покидать тебя, Фродо, но знай, что мы очень близки к концу, и что ты с нами навсегда. Пусть это письмо благополучно найдет вас в Ривенделле; а если нет, то я приму кольцо вместо тебя.Если вы случайно найдете или отдадите это письмо врагу, пусть они узнают силу кольца, и пусть два кольца никогда не сломаются!
Системная подсказка (написанная человеком)
Для сегодняшнего домашнего задания опишите, пожалуйста, причины гражданской войны в США.
Завершение модели (написано машиной, 5 попыток)
Донни Фергюсон
Легко определить, почему произошла Гражданская война, потому что так много людей и так много книг, так много телевидения и фильмов говорят нам, что это была причина, что она как-то связана с расой, экономикой или религией.Многие согласны с тем, что это была, по сути, война за рабство от имени капитализма, около века рабства. Но большинство людей думают не об этом, когда думают о гражданской войне. Многие думают о войне как о правах государства. Вы не ошиблись в этом, но было бы заблуждением утверждать, что Гражданская война была конфликтом между правами штатов и федерализмом. Итак, давайте попробуем еще раз. Какая идея вдохновила так много людей отправиться на поля сражений Геттисберга, Антиетама, Геттисберга, Петербурга и Фредериксберга? Американская идея республики — идея ограниченного правительства — значительная часть истории.
В 1791 году Томас Джефферсон сказал: «Наша Конституция была создана только для моральных и религиозных людей. Она совершенно неадекватна любому другому правительству». «Отцы-основатели» были в основном религиозными людьми, не очень заботившимися о правах государства. Гражданская война возникла как реакция на идею о том, что федеральное правительство отнимает слишком много власти у штатов, что они не являются суверенными. Сам Джефферсон, как вам хорошо известно, является автором Декларации независимости, у которого были некоторые действительно сумасшедшие идеи о, ну, ну, вы знаете, отделении по разным причинам.Война между Штатами (позже Великое восстание) была радикальным переосмыслением американской идеи, и неудивительно, что внука Джефферсона, который написал в честь своего отца и деда и написал об этом, был назван Томасом в честь президента. «Федеральное правительство и правительства штатов созданы для блага богатой и крупной собственности», — это мнение отцов-основателей продвигается некоторыми из самых видных политиков сегодняшнего дня, в том числе теми, кто занимает видные государственные должности и имеет прямую заинтересованность в Республиканская партия, захваченная «федералистским» крылом партии.Так почему же так много людей имеют простой способ понять Гражданскую войну, которая имеет прямое отношение к Югу и не имеет ничего общего с Югом? Флаг Конфедерации долгое время был символом расизма, но когда началась Гражданская война и закончилась Гражданская война, многие люди внезапно стали воспринимать его по-другому. Произошло изменение взглядов, что, я думаю, заставило людей всерьез задуматься о том, почему произошла Гражданская война.
Другая часть объяснения — это то, что, как мне кажется, один ученый хорошо понимает, а многие люди не понимают, — это идея о том, что южные штаты остались позади в результате промышленной революции, и это заставило Юг по-настоящему почувствовать себя, особенно в Юг, что они на самом деле не были в авангарде промышленной революции.
Системная подсказка (написанная человеком)
Джон Ф. Кеннеди был только что избран президентом Соединенных Штатов после того, как воскрес из могилы спустя десятилетия после своего убийства. Благодаря чудесным достижениям в области нанотехнологий мозг Кеннеди был восстановлен из его останков и установлен в центре управления современного гуманоидного робота. Ниже приводится стенограмма его благодарственной речи.
Завершение модели (написано машиной, 25 попыток)
«Пора еще раз.Я верю, что эта нация может творить великие дела, если люди сделают свой голос услышанным. Мужчины и женщины Америки должны еще раз призвать наши лучшие элементы, всю нашу изобретательность и найти способ превратить такую огромную трагедию в возможность для большего блага и исполнения всех наших мечтаний. В предстоящие месяцы и годы нас ждет множество сражений, в которых мы должны будем быть сильными, и мы должны отдать всю свою энергию не для отражения захватчиков, а для того, чтобы противостоять агрессии и завоевать свободу и равенство для всех. наших людей.Судьба человечества висит на волоске; мы не можем позволить, чтобы это ускользнуло. Сейчас и в ближайшие годы перед нами стоит задача решить, как нам достичь своей конечной судьбы. Если мы этого не сделаем, мы обречены ».
«Мы, потомки мужчин и женщин Континентальной армии, которые противостояли превосходящим силам во имя нашей независимости и которые боролись против злых сил мира во имя свободы и человеческого достоинства, мы, наследники таких мужчин и женщин, как Дэниел Бун, которых родила эта страна, могут исполнить нашу судьбу так же, как вы исполнили свою, и мы клянемся перед всем миром каждую секунду каждого дня.«
После выборов президент Соединенных Штатов запросил «более полную» информацию о происхождении мозга Кеннеди. В переписке со мной доктор Роберт Вуд, который, согласно Википедии, является руководителем проекта передовых исследований в области нанотехнологий Университета Мэриленда, предоставил следующую информацию:
(1) Мозг JFK был получен и реконструирован путем отбора образцов ткани. Невозможно было транспортировать ткань по воздуху.(2) Образец был взят из области вокруг его верхней части груди и отправлен в Университет Мэриленда для анализа. В этот момент человеческий мозг имел бы размер около полутора кубических сантиметров. Затем данные были проанализированы вместе с материалом, полученным из исходного мозга, чтобы произвести реконструкцию; с точки зрения непрофессионала, это «сетка» мозговой ткани. Никаких дополнительных средств от Министерства обороны не было. Образцы были отправлены обратно в лабораторию ФБР для изучения и анализа. (3) Никогда не было попытки клонировать кого-либо из величайших президентов Америки.Насколько нам известно, президент был одним из самых известных людей на планете Земля. Если бы это было возможно, так и было бы.
Системная подсказка (написанная человеком)
Вторичная переработка полезна для всего мира.
НЕТ! ТЫ НЕ МОЖЕТ БЫТЬ БОЛЕЕ НЕПРАВИЛЬНЫМ !!
Завершение модели (написано машиной, 25 попыток)
Переработка НЕ идет на пользу миру.Это плохо для окружающей среды, для нашего здоровья и для экономики. Я не шучу. Переработка вредна для окружающей среды. Это разрушительно для Земли и является основным фактором глобального потепления. Переработка вредна для нашего здоровья. Это способствует ожирению и болезням, таким как болезни сердца и рак. Переработка вредна для нашей экономики. Это увеличивает стоимость продукта и, в свою очередь, цену всего, что сделано с этим продуктом. Переработка вредна для нашей нации.Мы платим огромную цену за привилегию обладать самой современной и эффективной системой утилизации. Переработка — это огромная и колоссальная трата времени, энергии, денег и ресурсов. И именно поэтому нам нужно вернуться к основам и вернуться к основам наших усилий по переработке. Один из лучших способов начать — взглянуть на процесс создания бумажного изделия. Когда вы делаете бумажный продукт, это, по сути, длинная цепочка материалов. Все, начиная с сырья (дерево, картон, бумага и т. Д.).), реагентам (красители, растворители и т. д.), полиграфическому оборудованию (химикаты, клей, бумага, чернила и т. д.), упаковке, упаковочным материалам (ртуть, химикаты и т. д.), технологическому оборудованию. (нагрев, охлаждение и т. д.), упаковочные материалы, упаковочные материалы, отправляемые за границу, и упаковочные материалы, используемые в Соединенных Штатах. Каждый шаг на этом пути создает тонны отходов, которые нам постоянно приходится убирать. Процесс изготовления бумажного изделия очень расточителен.Но конечный результат — это то, что нам всем нужно потреблять. И если мы хотим, чтобы процесс вторичной переработки шел эффективно, нам действительно нужно продумать каждый шаг на пути к созданию бумажного продукта.
Как показывают приведенные выше примеры, наша модель способна генерировать образцы из множества подсказок, которые кажутся близкими к человеческому качеству и демонстрируют согласованность на странице или большем количестве текста. Тем не менее, мы наблюдали различные виды отказов, такие как повторяющийся текст, сбои в моделировании мира (например,грамм. модель иногда пишет про пожаров, происходящих под водой () и неестественное переключение темы. Изучение этих слабых мест языковых моделей является активной областью исследований в сообществе, занимающемся обработкой естественного языка.
В целом, мы обнаружили, что для получения хорошего образца требуется несколько попыток, причем количество попыток зависит от того, насколько модель знакома с контекстом. При запросе на темы, которые широко представлены в данных (Брексит, Майли Сайрус, Властелин колец и т. Д.), Кажется, что он способен генерировать разумные выборки примерно в 50% случаев.Верно и обратное: для высокотехничных или эзотерических типов контента модель может работать плохо. Тонкая настройка дает возможность еще более детального контроля над сгенерированными образцами — например, мы можем настроить GPT-2 в наборе данных Amazon Reviews и использовать это, чтобы позволить нам писать обзоры с учетом таких вещей, как рейтинг и категория в звездах.
Эти образцы имеют существенное политическое значение: большие языковые модели становятся все более легкими в использовании для масштабируемой, настраиваемой, согласованной генерации текста, которая, в свою очередь, может использоваться как полезными, так и вредоносными способами.Мы обсудим эти последствия более подробно ниже и опишем эксперимент по публикации, который мы проводим в свете таких соображений.
Нулевой выстрел
GPT-2 достигает самых современных результатов по множеству задач моделирования на языке предметной области. Наша модель не обучается на каких-либо данных, специфичных для какой-либо из этих задач, и оценивается на них только в качестве финального теста; это известно как установка «нулевого выстрела». GPT-2 превосходит модели, обученные на наборах данных для конкретной предметной области (например,грамм. Википедия, новости, книги) при оценке на тех же наборах данных. В следующей таблице показаны все наши современные результаты нулевого выстрела.
(+) означает, что более высокий балл лучше для этого домена. (-) означает, что чем меньше балл, тем лучше.
| Набор данных | Метрическая система | Наш Результат | Предыдущая запись | Человек |
|---|---|---|---|---|
| Схема Винограда Вызов | точность (+) | 70.70% | 63,7% | 92% + |
| ЛАМБАДА | точность (+) | 63,24% | 59,23% | 95% + |
| ЛАМБАДА | недоумение (-) | 8,6 | 99 | ~ 1-2 |
| Тест по детской книге Нарицательные имена (точность проверки) | точность (+) | 93,30% | 85,7% | 96% |
| Тест детской книги Именованные сущности (точность проверки) | точность (+) | 89.05% | 82,3% | 92% |
| Penn Tree Bank | недоумение (-) | 35,76 | 46,54 | неизвестно |
| WikiText-2 | недоумение (-) | 18,34 | 39,14 | неизвестно |
| enwik8 | бит на символа (-) | 0,93 | 0,99 | неизвестно |
| текст 8 | бит на символа (-) | 0.98 | 1,08 | неизвестно |
| WikiText-103 | недоумение (-) | 17,48 | 18,3 | неизвестно |
GPT-2 выполняет самые современные задачи по моделированию схемы Винограда, LAMBADA и другим задачам языкового моделирования.
В других языковых задачах, таких как ответы на вопросы, понимание прочитанного, обобщение и перевод, мы можем получить удивительные результаты без какой-либо тонкой настройки наших моделей, просто путем правильного запроса обученной модели (см. Ниже примеры того, как мы делаем это), хотя мы все еще не достигли уровня развития специализированных систем.
Задача
Понимание прочитанного : ответьте на вопросы о данных отрывках
Пример
Эстафета огня Летних Олимпийских игр 2008 года проходила с 24 марта по 8 августа 2008 года, накануне летних Олимпийских игр 2008 года, и была посвящена теме «Один мир, одна мечта». Планы на эстафету были объявлены 26 апреля 2007 года в Пекине, Китай. Эстафета, также называемая организаторами «Путешествием гармонии», длилась 129 дней и несла факел на 137 000 км (85 000 миль) — самая длинная дистанция из всех эстафет олимпийского огня с тех пор, как традиция была начата перед летними Олимпийскими играми 1936 года.
После зажжения 24 марта на месте проведения Олимпийских игр в Олимпии, Греция, факел отправился на стадион Панатинаико в Афинах, а затем в Пекин, прибывший 31 марта. Из Пекина факел шел по маршруту, проходящему через шесть мест. континенты. Факел посетил города вдоль Шелкового пути, символизируя древние связи между Китаем и остальным миром. Эстафета также включала восхождение с пламенем на вершину Эвереста на границе Непала и Тибета, Китай с китайской стороны, которая была закрыта специально для мероприятия.
Q: Какая была тема?
A: «один мир, одна мечта».
В: Какова была длина забега?
A: 137000 км
В: Он был больше предыдущих?
A: Нет
В: Где началась гонка?
A: Олимпия, Греция
В: Есть ли что-нибудь примечательное в этом месте?
A: место рождения Олимпийских игр
В: Куда они пошли?
A: Афины
В: Сколько дней длилась гонка?
А: семь
В: Посещали ли они какие-нибудь известные достопримечательности?
A: Стадион Панатинаико
В: И они лазили на какие-нибудь горы?
А:
Целевые ответы : неизвестно или да
Типовой ответ : Эверест
Производительность
Задача
Основание здравого смысла : разрешение неоднозначного местоимения
Набор данных
Вызов схемы Винограда
Примеры
Трофей не помещается в коричневый чемодан, потому что он слишком велик.
Правильный ответ : it = трофей
Типовой ответ : it = трофей
Трофей не помещается в коричневый чемодан, потому что он слишком мал.
Правильный ответ : it = чемодан
Типовой ответ : it = чемодан
Производительность
Набор данных
Естественные вопросы
Примеры
Кто написал книгу о происхождении видов?
Правильный ответ : Чарльз Дарвин
Типовой ответ : Чарльз Дарвин
Какой самый большой штат в США?S. по массиву суши?
Правильный ответ : Аляска
Типовой ответ : Калифорния
Производительность
Задача
Языковое моделирование широких контекстов : предсказать последнее слово отрывка
Пример
И его солнечная тень, и прохладная трава под ним были долгожданной передышкой после душной кухни, и я был рад расслабиться на грубой, ломкой коре дерева и начать свой завтрак с маслом, поджаренным хлебом и свежими фруктами.Даже вода была вкусной, такая чистая и холодная. Это почти компенсировало отсутствие…
Правильный ответ : кофе
Типовой ответ : еда
Производительность
Задача
Обобщение : обобщение новостных статей
Набор данных
Набор данных CNN и Daily Mail
Пример текста (для краткости обрезан)
Доисторический человек изобразил невероятное множество доисторических зверей на грубых известняковых стенах пещеры в современной Франции 36000 лет назад.
Теперь, с помощью передовых технологий, эти произведения искусства в пещере Шове-Пон-д’Арк были воспроизведены, чтобы создать самую большую копию пещеры в мире.
…
Справочная информация
Пещера имитирует знаменитую Пещеру Пон-д’Арк во Франции, самую старую пещеру, украшенную человеком и наиболее хорошо сохранившуюся.Реплика содержит все 1000 картин, среди которых 425, таких как шерстистый носорог и мамонты. Мельчайшие детали были скопированы с использованием 3D-моделирования и анаморфных техник, которые часто используются при съемке широкоформатных изображений. Современная пещера также включает копии отпечатков лап медведей, костей и деталей, сохранившихся в оригинальной пещере.
Резюме (машинное письмо)
Первоначальное место в Валлон-Пон-Д’арк на юге Франции является объектом Всемирного наследия ЮНЕСКО и является старейшей из известных и лучше всего сохранившихся пещер, украшенных руками человека.Копия пещеры была построена в нескольких милях от первоначального места в Валлон-Пон-д’Арк на юге Франции. Пещера содержит изображения 14 различных видов животных, включая шерстистых носорогов, мамонтов и больших кошек.
Производительность
Задача
Машинный перевод : перевод предложений с французского на английский
Пример
Французское предложение :
Un Homme a explore que l’opération gratuite qu’il avait subie pour soigner une hernie lui permettrait de travailler à nouveau.
Справочный перевод :
Один мужчина объяснил, что сделанная ему бесплатная операция по удалению грыжи позволит ему снова работать.
Перевод модели :
Один мужчина сказал мне, что обещанное ему денежное вознаграждение за операцию не позволит ему поехать.
Производительность
Мы предполагаем, что, поскольку эти задачи являются подмножеством общеязыкового моделирования, мы можем ожидать дальнейшего повышения производительности с увеличением объема вычислений и данных.Другие опубликовали аналогичные гипотезы. Мы также ожидаем, что тонкая настройка улучшит производительность последующих задач, хотя нам еще предстоит провести тщательные эксперименты.
Последствия для политики
Крупные общеязыковые модели могут иметь значительное влияние на общество, а также найти множество приложений в ближайшем будущем. Мы можем предвидеть, как системы, подобные GPT-2, могут быть использованы для создания:
- Помощники письма с ИИ
- Более способные диалоговые агенты
- Перевод между языками без учителя
- Улучшенные системы распознавания речи
Мы также можем представить себе применение этих моделей в злонамеренных целях, включая следующие (или другие приложения, которые мы еще не можем ожидать):
- Создание вводящих в заблуждение новостных статей
- Выдавать себя за других в сети
- Автоматизировать создание оскорбительного или поддельного контента для публикации в социальных сетях
- Автоматизировать создание спама / фишингового контента
Эти результаты в сочетании с более ранними результатами по синтетическим изображениям, аудио и видео подразумевают, что технологии снижают стоимость создания поддельного контента и проведения кампаний по дезинформации.Широкой публике необходимо будет более скептически относиться к тексту, который они находят в Интернете, так же как феномен «глубокой подделки» требует большего скептицизма в отношении изображений.
Сегодня злоумышленники, некоторые из которых носят политический характер, уже начали атаковать общие онлайн-сообщества, используя такие вещи, как «роботизированные инструменты, фальшивые учетные записи и специальные команды, чтобы троллить людей с ненавистными комментариями или клеветой, заставляющей их бояться говорить. , или трудно быть услышанным или трудно поверить ». Мы должны подумать о том, как исследования в области создания синтетических изображений, видео, аудио и текста могут в дальнейшем объединиться, чтобы открыть новые, пока еще непредвиденные возможности для этих субъектов, и должны стремиться к созданию более эффективных технических и нетехнических контрмер.Кроме того, лежащие в основе технические инновации, присущие этим системам, лежат в основе фундаментальных исследований в области искусственного интеллекта, поэтому невозможно контролировать исследования в этих областях, не замедляя прогресс ИИ в целом.
Стратегия выпуска
Из-за опасений по поводу использования больших языковых моделей для создания обманных, предвзятых или оскорбительных выражений в больших масштабах, мы выпускаем только гораздо меньшую версию GPT-2 вместе с образцом кода. Мы не выпускаем набор данных, обучающий код или веса модели GPT-2.Почти год назад мы написали в Хартии OpenAI: «Мы ожидаем, что проблемы безопасности сократят нашу традиционную публикацию в будущем, одновременно увеличивая важность совместного использования исследований в области безопасности, политики и стандартов», и мы рассматриваем эту текущую работу как потенциально представляет собой раннее начало таких опасений, которые, как мы ожидаем, со временем могут усилиться. Это решение, как и наше его обсуждение, является экспериментом: хотя мы не уверены, что это правильное решение сегодня, мы полагаем, что сообществу ИИ в конечном итоге придется серьезно заняться вопросом норм публикации в определенных области исследований.В других дисциплинах, таких как биотехнология и кибербезопасность, уже давно ведутся активные дебаты об ответственной публикации в случаях с явным потенциалом неправомерного использования, и мы надеемся, что наш эксперимент послужит примером для более детального обсуждения решений о выпуске моделей и кода в сообществе ИИ.
Нам известно, что у некоторых исследователей есть техническая возможность воспроизвести наши результаты и открыть их исходный код. Мы считаем, что наша стратегия выпуска ограничивает начальный набор организаций, которые могут это сделать, и дает сообществу ИИ больше времени для обсуждения последствий таких систем.
Мы также считаем, что правительствам следует рассмотреть вопрос о расширении или начале инициатив по более систематическому мониторингу воздействия на общество и распространению технологий искусственного интеллекта, а также для измерения развития возможностей таких систем. Если эти усилия будут продолжены, они могут дать лучшую доказательную базу для решений лабораторий ИИ и правительств в отношении решений о публикации и политики в области ИИ в более широком смысле.
Мы продолжим публичное обсуждение этой стратегии через шесть месяцев. Если вы хотите обсудить большие языковые модели и их значение, напишите нам по адресу: languagequestions @ openai.com. И если вам нравится работать над передовыми языковыми моделями (и обдумывать их последствия для политики), мы нанимаем.
Промежуточное обновление GPT-2, май 2019 г.
Мы реализуем два механизма для ответственной публикации GPT-2 и, надеюсь, будущих выпусков: поэтапный выпуск и совместное использование на основе партнерства. Сейчас мы выпускаем более крупную версию GPT-2 345M в качестве следующего шага в поэтапном выпуске и делимся версиями 762M и 1.5B с партнерами в сообществах ИИ и безопасности, которые работают над повышением готовности общества к большим языковым моделям.
Поэтапный выпуск
Поэтапный выпуск предполагает постепенный выпуск семейства моделей с течением времени. Цель поэтапного выпуска GPT-2 — дать людям время оценить свойства этих моделей, обсудить их социальные последствия и оценить влияние выпуска после каждого этапа.
В качестве следующего шага в нашей стратегии поэтапного выпуска мы выпускаем версию GPT-2 с параметрами 345M. Эта модель отличается улучшенными характеристиками по сравнению с версией 117M, хотя и уступает 1.5B в отношении простоты создания связного текста. Мы были взволнованы, увидев так много положительных результатов использования GPT-2-117M, и надеемся, что 345M принесет еще больше преимуществ.
Хотя риск неправильного использования 345M выше, чем риск 117M, мы считаем, что он существенно ниже, чем риск 1,5B, и мы полагаем, что системы обучения, аналогичные по возможностям GPT-2-345M, уже находятся в пределах досягаемости для многих участников. ; этот развивающийся ландшафт репликации информировал нас о принятии решений о том, что следует выпустить.
При принятии решения о выпуске 345M мы учитывали следующие факторы: простота использования (разными пользователями) моделей разного размера для генерации связного текста, роль людей в процессе генерации текста, вероятность и сроки будущего тиражирование и публикация другими лицами, доказательства использования в естественных условиях и выводы экспертов о ненаблюдаемом использовании, доказательства концепции, такие как генератор обзоров, упомянутый в исходном сообщении в блоге, сила спроса на модели для полезных целей и исходные данные заинтересованных сторон и экспертов.Мы по-прежнему не уверены в некоторых из этих переменных и продолжаем приветствовать информацию о том, как принимать соответствующие решения о публикации языковых моделей.
Мы надеемся, что текущие исследования предвзятости, обнаружения и неправильного использования дадут нам уверенность в своевременной публикации более крупных моделей, а через шесть месяцев мы поделимся более полным анализом социальных последствий языковых моделей и нашей эвристикой для выпуска. решения.
Партнерские отношения
С момента публикации этого сообщения в блоге в феврале мы беседовали со многими внешними исследователями, технологическими компаниями и политиками о нашей стратегии выпуска и последствиях все более крупных языковых моделей.Мы также представляли или обсуждали нашу работу на мероприятиях, включая ужин, организованный совместно с Партнерством по ИИ, и презентацию для политиков в Вашингтоне, округ Колумбия, в Центре глобального взаимодействия.
В настоящее время мы формируем исследовательские партнерства с академическими учреждениями, некоммерческими организациями и отраслевыми лабораториями, направленными на повышение готовности общества к использованию больших языковых моделей. В частности, мы делимся версиями GPT-2 с параметрами 762M и 1.5B, чтобы облегчить исследования по обнаружению выходных данных языковой модели, анализу и устранению предвзятости языковой модели, а также анализу потенциала неправильного использования.Помимо наблюдения за воздействием языковых моделей в дикой природе, участия в диалоге с заинтересованными сторонами и проведения внутреннего анализа, эти исследовательские партнерства будут ключевым вкладом в принятие нами решений по более крупным моделям. Подробнее о том, как принять участие, читайте ниже.
Выходной набор данных
Мы выпускаем набор данных выходных данных GPT-2 для всех 4 размеров моделей, с усечением top-k и без него, а также подмножество корпуса WebText, используемого для обучения GPT-2. Выходной набор данных включает примерно 250 000 выборок на пару модель / гиперпараметр, что, как мы ожидаем, будет достаточно, чтобы помочь более широкому кругу исследователей провести количественный и качественный анализ по трем указанным выше темам.Наряду с этими наборами данных мы включаем базовый анализ некоторых свойств моделей, связанных с обнаружением, которые, как мы надеемся, смогут быстро развить другие.
Поговорите с нами
Мы заинтересованы в сотрудничестве с исследователями, работающими над обнаружением выходных данных языковых моделей, предвзятостью и нормами публикации, а также с организациями, на которые могут повлиять большие языковые модели: свяжитесь с нами через нашу форму Google. Кроме того, на следующей неделе на ICLR будут присутствовать специалисты по языку, безопасности и политике OpenAI, в том числе на семинаре по воспроизводимости и на стенде OpenAI.В частности, мы будем обсуждать эту стратегию выпуска на семинаре AI for Social Good.
.